이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
대화형 방식 피팅
기본 피팅 UI
MATLAB® 기본 피팅 UI를 사용하면 다음 작업을 대화형 방식으로 수행할 수 있습니다.
스플라인 보간, 형태 보존 보간 또는 최대 10차 다항식을 사용하여 데이터 모델링
데이터에 하나 이상의 피팅을 함께 플로팅
피팅의 잔차 플로팅
모델 계수 계산
잔차의 노름(Norm) 계산(모델이 데이터를 얼마나 잘 피팅하는지 분석하는 데 사용할 수 있는 통계량)
모델을 사용하여 데이터 보간 또는 데이터 바깥쪽에 외삽
대화 상자 외부에서 사용할 수 있도록 계수와 계산된 값을 MATLAB 작업 공간에 저장
새 데이터에 대해 피팅을 다시 계산하고 플롯을 재현하는 MATLAB 코드 생성
참고
기본 피팅 UI는 2차원 플롯에만 사용할 수 있습니다. 고급 피팅과 회귀 분석에 대한 내용은 Curve Fitting Toolbox™ 문서와 Statistics and Machine Learning Toolbox™ 문서를 참조하십시오.
기본 피팅 준비하기
기본 피팅 UI는 피팅 전에 데이터를 오름차순으로 정렬합니다. 데이터 세트의 크기가 크고 값이 오름차순으로 정렬되어 있지 않으면 기본 피팅 UI가 피팅 전에 데이터를 전처리하는 데 시간이 더 오래 걸립니다.
먼저 데이터를 정렬하면 기본 피팅 UI 속도를 높일 수 있습니다. 데이터 벡터 x와 y에서 정렬된 벡터 x_sorted와 y_sorted를 생성하려면 다음과 같이 MATLAB sort 함수를 사용하십시오.
[x_sorted, i] = sort(x); y_sorted = y(i);
기본 피팅 UI 열기
기본 피팅 UI를 사용하려면 먼저 x와 y 데이터만 생성하는 임의의 MATLAB 플로팅 명령을 사용하여 Figure 창에 데이터를 플로팅해야 합니다.
기본 피팅 UI를 열려면 Figure 창의 맨 위에 있는 메뉴에서 툴 > 기본 피팅을 선택하십시오.
예제: 기본 피팅 UI 사용하기
이 예제에서는 기본 피팅 UI를 사용하여 다항 회귀의 코드를 피팅, 시각화, 분석, 저장 및 생성하는 방법을 보여줍니다.
인구 조사 데이터 불러오기와 플로팅하기
파일 census.mat에는 1790년부터 1990년까지 10년 간격으로 조사한 미국 인구 데이터가 들어 있습니다.
데이터를 불러오고 플로팅하려면 MATLAB 프롬프트에 다음 명령을 입력하십시오.
load census plot(cdate,pop,'ro')
load 명령은 MATLAB 작업 공간에 다음 변수를 추가합니다.
cdate— 1790년부터 1990년까지의 연도가 10년 단위로 포함되어 있는 열 벡터입니다. 이 변수는 예측 변수입니다.pop—cdate의 각 연도별 미국 인구가 포함되어 있는 열 벡터입니다. 이 변수는 응답 변수입니다.
데이터 벡터는 연도를 기준으로 오름차순으로 정렬됩니다. 플롯은 인구를 연도에 대한 함수로 표시합니다.
이제 데이터에 방정식을 피팅하여 시간 경과에 따른 인구 증가를 모델링할 수 있습니다.
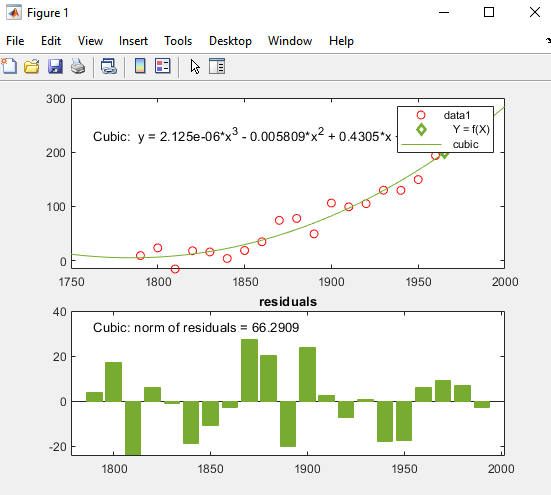
3차 다항식 피팅을 통해 인구 조사 데이터 예측하기
Figure 창에서 툴 > 기본 피팅을 선택하여 기본 피팅 대화 상자를 엽니다.
기본 피팅 대화 상자의 피팅 유형 영역에서 3차 체크박스를 선택하여 데이터에 3차 다항식을 피팅합니다.
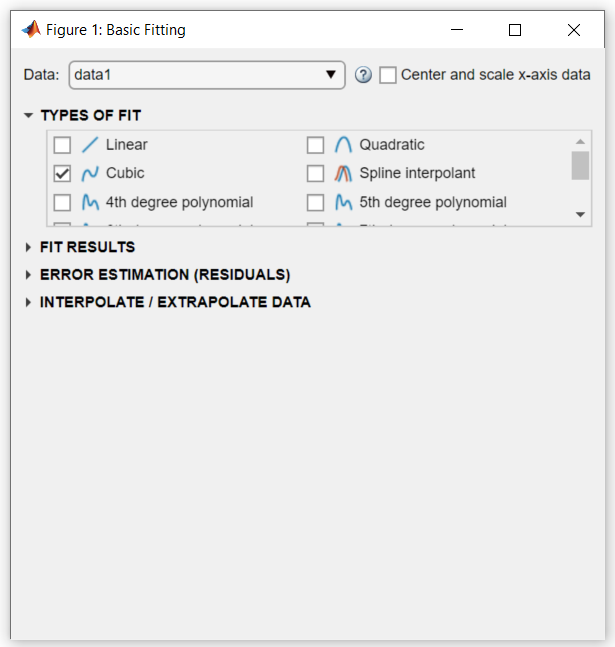
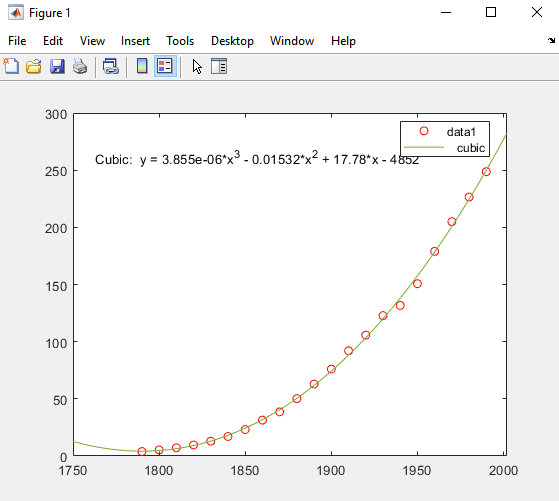
MATLAB은 선택된 옵션을 사용하여 데이터를 피팅하고, 다음과 같이 그래프에 3차 회귀선을 추가합니다.
피팅을 계산할 때 MATLAB에서 문제가 발생하고 다음과 같은 경고를 발생시킵니다.
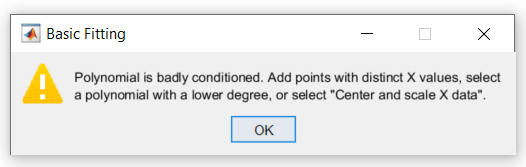
이 경고는 모델에 대해 계산된 계수가 응답 변수(측정된 인구)의 랜덤 오차에 민감하다는 것을 나타냅니다. 또한 더 적합한 피팅을 얻을 수 있는 방법도 제안합니다.
3차 피팅을 계속 사용합니다. 인구 조사 데이터에 새로운 관측값을 추가할 수 없으므로, 피팅을 다시 계산하기 전에 값을 z-점수로 변환하여 피팅을 향상시킵니다. 대화 상자의 오른쪽 상단에 있는 x축 데이터 정규화 체크박스를 선택하여 기본 피팅 툴이 변환을 수행하도록 합니다.
데이터 정규화가 동작하는 방식을 알아보려면 기본 피팅 툴이 피팅을 계산하는 방식 알아보기 항목을 참조하십시오.
오차 추정값(잔차) 아래에서 잔차의 노름(Norm) 체크박스를 선택합니다. 막대를 플롯 스타일로 선택합니다.
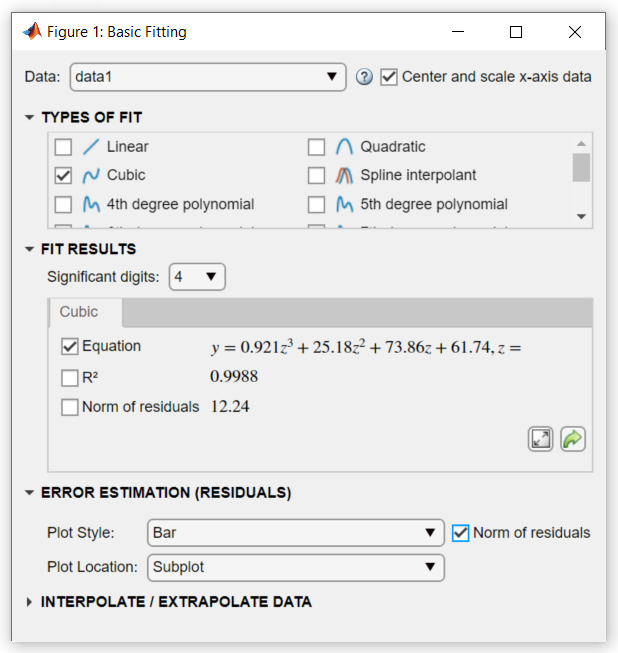
이러한 옵션을 선택하면 잔차의 서브플롯이 막대 그래프로 생성됩니다.
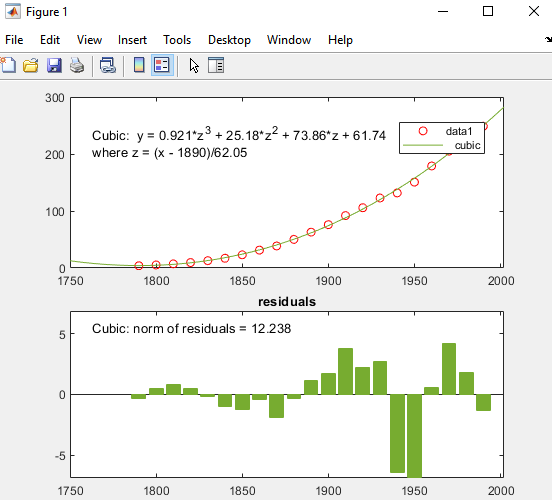
이 3차 피팅은 1790년 이전은 제대로 예측하지 못하고 있으며, 인구가 감소하는 것으로 나타납니다. 이 모델은 1790년 이후에는 데이터를 잘 근사하는 것으로 보입니다. 그러나 잔차의 패턴은 이 모델이 최소제곱 피팅의 기본이 되는 정규 오차의 가정을 충족하지 않음을 보여줍니다. 범례에 표시된 data 1 선은 관측된 x(cdate) 및 y(pop) 데이터 값입니다. 3차 회귀선은 데이터 값을 정규화한 후의 피팅을 나타냅니다. 툴이 변환된 z-점수를 사용하여 피팅을 계산하더라도, 이 Figure에는 원래 데이터 단위가 표시됩니다.
비교를 위해, 피팅 유형 영역에서 다른 다항 방정식을 선택하여 인구 조사 데이터에 피팅해 보십시오.
3차 피팅 파라미터 보기와 저장하기
기본 피팅 대화 상자에서 결과 확장 버튼 ![]() 을 클릭하여 추정된 계수와 잔차의 노름(Norm)을 표시합니다.
을 클릭하여 추정된 계수와 잔차의 노름(Norm)을 표시합니다.
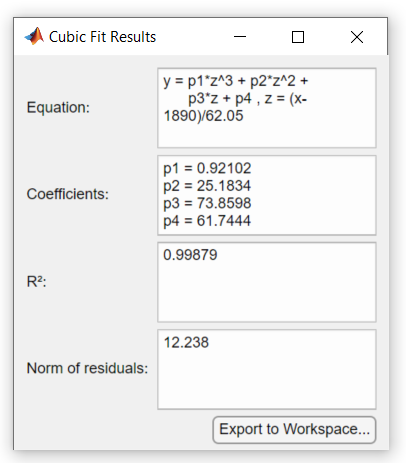
수치 결과 패널에서 작업 공간으로 내보내기 버튼을 클릭하여 피팅 데이터를 MATLAB 작업 공간에 저장합니다. 작업 공간에 피팅 저장 대화 상자가 열립니다.
모든 체크박스를 선택한 상태에서 확인을 클릭하여 다음과 같이 피팅 파라미터를 MATLAB 구조체 fit로 저장합니다.
fit
fit =
struct with fields:
type: 'polynomial degree 3'
coeff: [0.9210 25.1834 73.8598 61.7444]이제, 기본 피팅 UI 외부에서 MATLAB 프로그래밍에 피팅 결과를 사용할 수 있습니다.
결정계수 R2
결정계수, 즉 R 제곱(R2으로 표기)을 계산하여 다항 회귀가 관측된 데이터를 얼마나 잘 예측하는지 확인할 수 있습니다. R2 통계량은 0에서 1 사이의 값으로, 종속 변수의 값을 예측하는 데 있어 독립 변수가 얼마나 유용한지를 측정합니다.
R2 값이 0에 가까우면 피팅이 모델
y = constant보다 그다지 개선되지 않음을 나타냅니다.R2 값이 1에 가까우면 독립 변수가 종속 변수의 변량 대부분을 설명하고 있음을 나타냅니다.
R2은 관측된 종속 값과 피팅이 예측하는 값 사이의 부호 있는 차이인 잔차에서 계산됩니다.
| residuals = yobserved - yfitted | (1) |
이 예제에서 3차 피팅의 R2 숫자 값은 0.9988이며, 이 값은 기본 피팅 대화 상자의 피팅 결과에서 확인할 수 있습니다.
3차 피팅의 R2 숫자 값을 선형 최소제곱 피팅과 비교하려면 피팅 유형에서 선형을 선택하고 R2 숫자 값(여기서는 0.921임)을 구하십시오. 이 결과는 인구 데이터의 선형 최소제곱 피팅이 인구 데이터 분산의 92.1%를 설명한다는 것을 나타냅니다. 이 데이터의 3차 피팅은 해당 분산의 99.9%를 설명하므로, 3차 피팅이 더 잘 예측하는 것으로 보입니다. 그러나, 3차 피팅은 3개의 변수(x, x2, x3)를 사용하여 예측하기 때문에 기본 R2 값은 피팅이 얼마나 견고한지를 완전히 반영하지 못합니다. 다변량 피팅의 적합도를 평가하는 데 더 적절한 측정값은 조정된 R2입니다. 조정된 R2을 계산하고 사용하는 방법에 대해서는 항목을 참조하십시오.
인구 값 보간하기와 외삽하기
3차 모델을 사용하여 1965년(원래 데이터에 제공되지 않은 연도)의 미국 인구를 보간한다고 가정하겠습니다.
기본 피팅 대화 상자의 데이터 보간/외삽에서 X 값으로 1965를 입력하고 실행된 데이터 플로팅 체크박스를 선택합니다.
참고
정규화되지 않은 X 값을 사용하십시오. 3차 다항식 피팅을 통해 인구 조사 데이터 예측하기에서 X 값을 스케일링하여 계수를 구하도록 선택했더라도 먼저 정규화할 필요는 없습니다. 기본 피팅 툴이 필요한 조정을 자동으로 수행합니다.
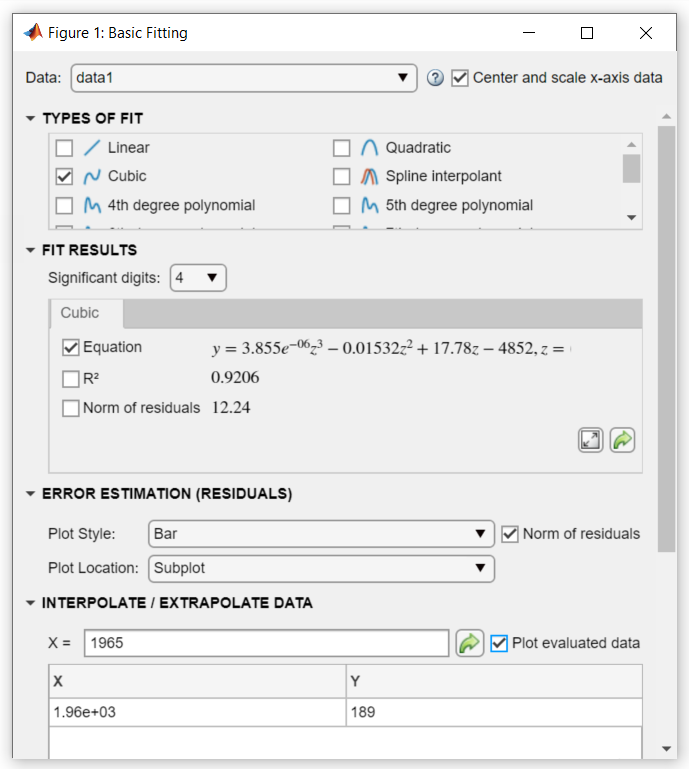
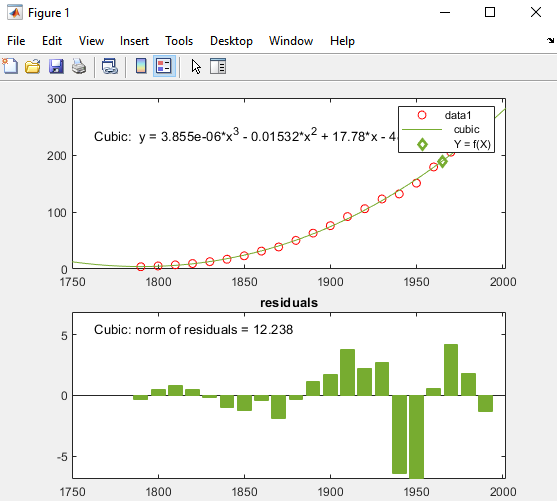
X 값과 f(X)의 대응값이 피팅에서 계산되어 아래와 같이 플로팅됩니다.
결과를 재현하는 코드 파일 생성하기
기본 피팅 세션을 완료한 후에는 새 데이터에 대해 피팅을 다시 계산하고 플롯을 재현하는 MATLAB 코드를 생성할 수 있습니다.
Figure 창에서 파일 > 코드 생성을 선택합니다.
그러면 함수가 생성되어 MATLAB 편집기에 표시됩니다. 이 코드는 기본 피팅 대화 상자에서 대화형 방식으로 수행한 작업을 프로그래밍 방식으로 재현하는 방법을 보여줍니다.
createfigure의 첫 라인에서 함수 이름을 좀 더 구체적인 이름(예:censusplot)으로 변경합니다. 코드 파일 이름을censusplot.m으로 지정하여 현재 폴더에 저장합니다. 함수는 다음 라인으로 시작합니다.function censusplot(X1, Y1, valuesToEvaluate1)
다음을 입력하여 무작위로 섭동된 새로운 인구 조사 데이터를 생성합니다.
rng('default') randpop = pop + 10*randn(size(pop));다음을 입력하여 새 데이터로 플롯을 재현하고 피팅을 다시 계산합니다.
censusplot(cdate,randpop,1965)
원래 그래프에 플로팅된 x,y 값(
data 1)과 마커의 x 값 등 세 개의 입력 인수가 필요합니다.다음 Figure는 생성된 코드로 만든 플롯을 표시합니다. 새 플롯은 y 데이터 값, 3차 피팅 방정식, 막대 그래프의 잔차 값을 제외하고 코드를 생성한 원래 Figure의 모양과 예상대로 일치합니다.
기본 피팅 툴이 피팅을 계산하는 방식 알아보기
기본 피팅 툴은 polyfit 함수를 호출하여 다항식 피팅을 계산합니다. 그리고 polyval 함수를 호출하여 피팅을 실행합니다. polyfit은 입력값을 분석하여 요청된 피팅 차수에 대해 데이터 조건이 좋은지 여부를 확인합니다.
조건이 나쁜 데이터가 발견되면, polyfit은 가능한 한 적합하게 회귀를 계산하지만 피팅을 개선할 여지가 있다는 내용의 경고를 반환합니다. 기본 피팅 예제 섹션 3차 다항식 피팅을 통해 인구 조사 데이터 예측하기에 이 경고가 표시되어 있습니다.
모델의 신뢰성을 개선할 수 있는 한 가지 방법은 데이터 점을 추가하는 것입니다. 그러나 데이터 세트에 항상 관측값을 추가할 수 있는 것은 아닙니다. 또 다른 방법은 예측 변수를 변환하여 정규화하는 것입니다. (이 예제에서 예측 변수는 인구 조사 날짜로 구성된 벡터입니다.)
polyfit 함수는 다음과 같이 z-점수를 계산하여 정규화합니다.
여기서 x는 예측 변수 데이터이고, μ는 x의 평균이며, σ는 x의 표준편차입니다. z-점수는 데이터의 평균을 0으로 만들고 표준편차를 1로 만듭니다. 기본 피팅 UI에서 x축 데이터 정규화 체크박스를 선택하여 예측 변수 데이터를 z-점수로 변환합니다.
정규화 후에는 모델 계수가 y 데이터에 대해 z의 함수로 계산됩니다. 이러한 계수는 y에 대해 x의 함수로 계산된 계수와 다르며 더 견고합니다. 모델의 형식과 잔차의 노름(Norm)은 변경되지 않습니다. 기본 피팅 UI는 피팅이 원래 x 데이터와 동일한 스케일로 플로팅되도록 z-점수를 자동으로 다시 스케일링합니다.
정규화된 데이터가 최종 플롯을 생성하기 위한 중개자로 사용되는 방식을 이해하려면 명령 창에서 다음 코드를 실행하십시오.
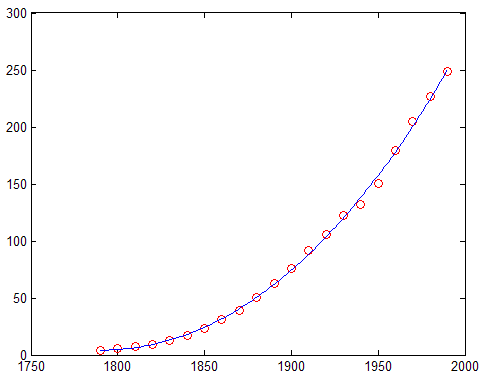
close load census x = cdate; y = pop; z = (x-mean(x))/std(x); % Compute z-scores of x data plot(x,y,'ro') % Plot data as red markers hold on % Prepare axes to accept new graph on top zfit = linspace(z(1),z(end),100); pz = polyfit(z,y,3); % Compute conditioned fit yfit = polyval(pz,zfit); xfit = linspace(x(1),x(end),100); plot(xfit,yfit,'b-') % Plot conditioned fit vs. x data
아래 그림과 같이, 정규화된 3차 다항식이 파란색 선으로 플로팅됩니다.
코드에서 z의 계산은 데이터를 정규화하는 방법을 보여줍니다. polyfit 함수는 다음과 같이 사용자가 이 함수를 호출할 때 세 개의 반환 인수를 제공하는 경우 자체적으로 변환을 수행합니다.
[p,S,mu] = polyfit(x,y,n)
p는 이제 정규화된 x를 기반으로 합니다. 반환된 벡터 mu에는 x의 평균과 표준편차가 포함됩니다. 자세한 내용은 polyfit 도움말 페이지를 참조하십시오.