1개의 예측 변수를 포함하는 선형 회귀
단순 선형 회귀는 예측 변수 1개와 응답 변수 1개 사이의 관계를 설명합니다. 선형 회귀 모델은 예측 변수의 변화가 응답 변수에 어떤 영향을 미치는지 이해하는 데 유용합니다.
이 예제에서는 polyfit 함수와 polyval 함수를 사용하여 다양한 차수의 단순 선형 회귀 모델을 피팅하고, 시각화하고, 유효성을 검사하는 방법을 보여줍니다. 기본 피팅 툴을 사용하여 모델을 피팅하고 시각화하는 방법에 대한 자세한 내용은 대화형 방식 피팅 항목을 참조하십시오.
단순 선형 회귀는 다음과 같은 경우에 사용합니다.
예측 변수가 1개입니다.
예측 변수와 응답 변수 간의 관계가 계수에 대해 선형입니다.
예측 변수가 응답 변수에 미치는 영향을 정량화하려고 합니다.
데이터 플로팅하기
먼저 데이터를 플로팅하여 다항식 피팅에 사용할 수 있는 차수를 확인합니다.
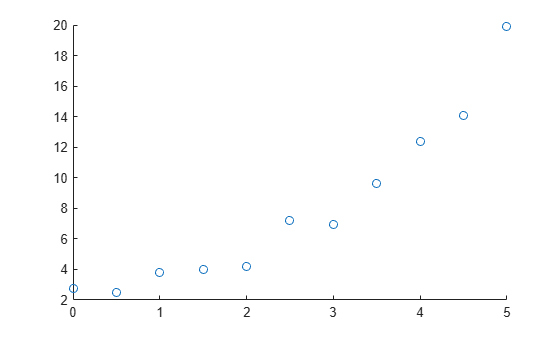
예를 들어, 표본 예측 변수 x와 표본 응답 변수 y를 만들고 시각화해 보겠습니다. 이 시각화는 선형 피팅 또는 2차 피팅이 예측 변수와 응답 변수 간의 관계를 설명할 수 있음을 의미합니다.
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
1차 모델 피팅하기
polyfit 함수를 사용하여 데이터에 1차(선형) 모델을 피팅합니다. 다항식 계수와 오차 추정값 구조체를 반환하는 2개의 출력 인수를 지정합니다.
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
피팅된 모델을 표시합니다.
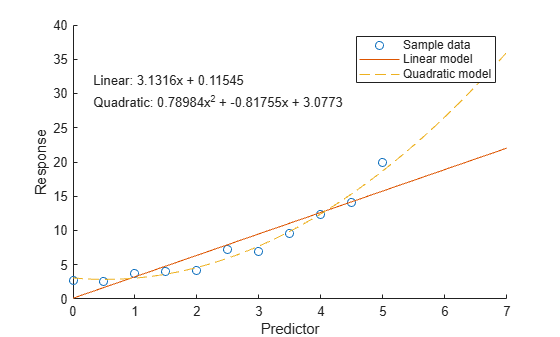
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
고차 모델 피팅하기
1차 모델이 예측 변수와 응답 변수 간의 관계를 적절하게 설명하지 못하는 경우, 고차 모델을 피팅할 수 있습니다. 예를 들어, polyfit 함수를 사용하여 데이터에 2차 모델을 피팅해 보겠습니다. 다항식 계수와 오차 추정값 구조체를 반환하는 2개의 출력 인수를 지정합니다.
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
피팅된 모델을 표시합니다.
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
모델 비교하기
플롯을 사용하여 모델을 비교하려면 먼저 쿼리 지점에서 각 모델을 평가하고 polyval 함수를 사용하여 예측된 응답 변수의 값을 반환합니다. 그런 다음, 데이터와 두 모델을 시각화합니다.
예를 들어, 더 세분화된 x 값의 범위에서 선형 모델과 2차 모델의 응답 변수 값을 구해 보겠습니다.
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
고차 모델이 응답 변수의 값을 제대로 예측하지 못한다면, 이는 과적합이 발생했음을 의미할 수 있습니다. 모델 유효성 검사와 모델 복잡도의 적절한 선택에 대한 자세한 내용은 모델 유효성 검사하기 섹션을 참조하십시오.
그런 다음, 표본 데이터와 모델 데이터를 플로팅합니다.
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
모델 유효성 검사하기
모델 유효성을 검사하려면 결정계수 또는 수정된 결정계수를 계산합니다. 값이 1에 가까울수록 피팅이 양호하다는 뜻입니다.
결정계수로 선형 모델 유효성 검사하기
1차 모델의 경우, polyfit 함수가 반환하는 오차 추정값 구조체를 사용하여 결정계수 값에 액세스할 수 있습니다. 예를 들어, rsquared 필드를 SLinear에서 쿼리해 보겠습니다.
linearR2 = SLinear.rsquared
linearR2 = 0.8715
수정된 결정계수로 고차 모델의 유효성 검사하기
항이 더 많은 고차 모델의 경우, 결정계수 값이 보통 증가하며 이는 관측 데이터에 더 가깝게 피팅된다는 뜻입니다. 그러나 이러한 모델은 과적합의 위험이 더 높습니다.
과적합은 모델이 원본 데이터(노이즈 포함)를 너무 정확하게 설명하여 새로운 데이터를 제대로 예측하지 못할 때 발생합니다.
예측 정확도와 모델 복잡도의 균형을 맞추기 위해, 수정된 결정계수 값을 사용하여 모델을 검증해 보십시오. 이 결정계수에는 예측 변수 개수에 대한 페널티가 포함되어 있습니다. 수정된 결정계수의 값은 다음 방정식을 사용하여 계산할 수 있습니다. 여기서 은 오차 추정 구조체의 rsquared 필드의 값이고, 은 데이터의 관측값 수이며, 는 모델의 차수입니다.
예를 들어, 2차 모델의 수정된 결정계수를 계산해 보겠습니다.
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
각 모델의 최대 예측 오차 계산하기
모델 예측값과 표본 데이터 간의 최대 오차를 계산하여 모델의 유효성을 검사할 수도 있습니다. 데이터 값을 기준으로 한 최대 오차가 작을수록 피팅이 양호하다는 뜻입니다.
예를 들어, 선형 모델과 2차 모델 모두에 대한 최대 오차를 계산해 보겠습니다.
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
참고 항목
함수
도움말 항목
- 대화형 방식 피팅
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- 다항식을 만들고 계산하기
- Linear Regression Workflow (Statistics and Machine Learning Toolbox)
- 다항식 모델 피팅하기 (Curve Fitting Toolbox)