이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
ttest2
2-표본 t-검정
설명
h = ttest2(x,y,Name,Value)
예제
데이터 세트를 불러옵니다. 데이터 행렬의 첫 번째 열과 두 번째 열을 포함하는 벡터를 생성하여 두 시험에 대한 학생들의 성적을 나타냅니다.
load examgrades
x = grades(:,1);
y = grades(:,2);'두 데이터 표본이 평균이 같은 모집단에서 추출된다'는 귀무가설을 검정합니다.
[h,p,ci,stats] = ttest2(x,y)
h = 0
p = 0.9867
ci = 2×1
-1.9438
1.9771
stats = struct with fields:
tstat: 0.0167
df: 238
sd: 7.7084
반환된 값 h = 0은 ttest2가 디폴트 5% 유의수준에서 귀무가설을 기각하지 않음을 나타냅니다.
데이터 세트를 불러옵니다. 데이터 행렬의 첫 번째 열과 두 번째 열을 포함하는 벡터를 생성하여 두 시험에 대한 학생들의 성적을 나타냅니다.
load examgrades
x = grades(:,1);
y = grades(:,2);'두 데이터 벡터가 평균이 같은 모집단에서 추출된다'는 귀무가설을 검정합니다. 이때 모집단의 분산은 같다고 가정하지 않습니다.
[h,p] = ttest2(x,y,'Vartype','unequal')
h = 0
p = 0.9867
반환된 값 h = 0은 ttest2가 분산이 같다고 가정하지 않는 경우에도 디폴트 5% 유의수준에서 귀무가설을 기각하지 않음을 나타냅니다.
표본 데이터를 불러옵니다. 차량 연도에 따라 차량 주행 거리 데이터에 레이블을 지정하는 categorical형 벡터를 만듭니다.
load carbig.mat; decade = categorical(Model_Year < 80,[true,false],["70s","80s"]);
매 10년마다 마일리지 데이터의 상자 플롯을 만듭니다.
boxchart(decade,MPG) xlabel("Decade") ylabel("Mileage")

매 10년마다 마일리지 데이터에서 벡터를 만듭니다. 왼쪽 꼬리, 2-표본 t-검정을 사용하여 '데이터가 평균이 같은 모집단에서 추출된다'는 귀무가설을 검정합니다. '1970년대에 만들어진 자동차의 마일리지에 대한 모집단 평균이 1980년대에 만들어진 자동차의 마일리지에 대한 모집단 평균보다 작다'는 대립가설을 사용합니다.
MPG70s = MPG(decade == "70s"); MPG80s = MPG(decade == "80s"); [h,~,~,stats] = ttest2(MPG70s,MPG80s,"Tail","left")
h = 1
stats = struct with fields:
tstat: -14.0630
df: 396
sd: 6.3910
반환된 값 h = 1은 ttest2가 디폴트 유의수준 5%에서 귀무가설을 기각하고 '1970년대에 만들어진 자동차의 마일리지에 대한 모집단 평균이 1980년대에 만들어진 자동차의 마일리지에 대한 모집단 평균보다 작다'는 대립가설을 채택함을 나타냅니다.
해당 스튜던트 t-분포, 반환된 t-통계량, 임계 t-값을 플로팅합니다. tinv를 사용하여 디폴트 신뢰수준 95%에서 임계 t-값을 계산합니다.
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = -14.0630
tvalpdf = tpdf(tval,nu); tcrit = -tinv(0.95,nu)
tcrit = -1.6487
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf","t-statistic", ... "Critical Cutoff"])
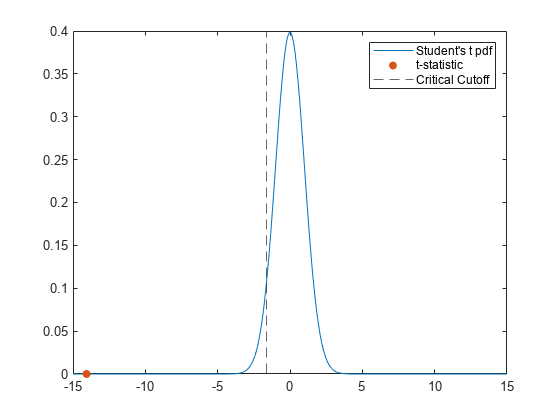
주황색 점은 t-통계량을 나타내며 임계 t-값을 나타내는 검은색 파선의 왼쪽에 위치합니다.
입력 인수
이름-값 인수
출력 인수
세부 정보
팁
다음을 계산하려면
sampsizepwr을 사용하십시오.지정된 검정력과 모수 값에 대응되는 표본 크기,
실제 모수 값이 주어진 경우 특정 표본 크기에 대해 달성한 검정력,
지정된 표본 크기와 검정력으로 검색 가능한 모수 값.
확장 기능
버전 내역
R2006a 이전에 개발됨
참고 항목
ttest | ztest | sampsizepwr