spectralcluster
Spectral clustering
Syntax
Description
idx = spectralcluster(X,k)X into k clusters using the spectral clustering
algorithm (see Algorithms).
spectralcluster returns an n-by-1 vector
idx containing cluster indices of each observation.
idx = spectralcluster(S,k,'Distance','precomputed')S, the similarity matrix (or adjacency matrix) of a similarity graph. S can be the output of adjacency.
To use a similarity matrix as the first input, you must specify
'Distance','precomputed'.
idx = spectralcluster(___,Name,Value)'SimilarityGraph','epsilon' to construct a similarity graph using the
radius search method.
[
also returns the eigenvectors idx,V] = spectralcluster(___)V corresponding to the
k smallest eigenvalues of the Laplacian
matrix.
Examples
Cluster a 2-D circular data set using spectral clustering with the default Euclidean distance metric.
Generate synthetic data that contains two noisy circles.
rng('default') % For reproducibility % Parameters for data generation N = 300; % Size of each cluster r1 = 2; % Radius of first circle r2 = 4; % Radius of second circle theta = linspace(0,2*pi,N)'; X1 = r1*[cos(theta),sin(theta)]+ rand(N,1); X2 = r2*[cos(theta),sin(theta)]+ rand(N,1); X = [X1;X2]; % Noisy 2-D circular data set
Find two clusters in the data by using spectral clustering.
idx = spectralcluster(X,2);
Visualize the result of clustering.
gscatter(X(:,1),X(:,2),idx);
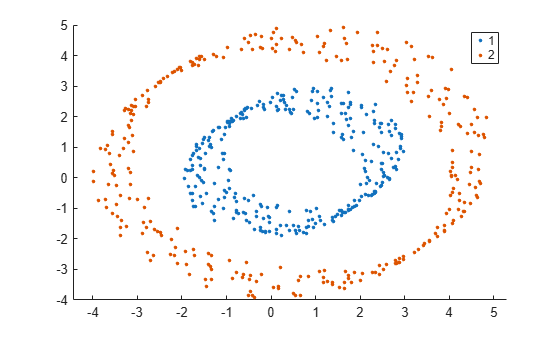
The spectralcluster function correctly identifies the two clusters in the data set.
Compute a similarity matrix from Fisher's iris data set and perform spectral clustering on the similarity matrix.
Load Fisher's iris data set. Use the petal lengths and widths as features to consider for clustering.
load fisheriris
X = meas(:,3:4);
gscatter(X(:,1),X(:,2),species);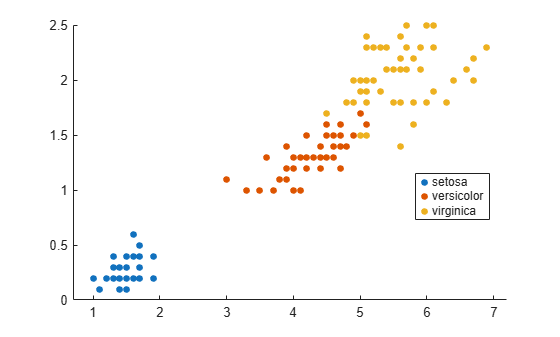
Find the distance between each pair of observations in X by using the pdist and squareform functions with the default Euclidean distance metric.
dist_temp = pdist(X); dist = squareform(dist_temp);
Construct the similarity matrix and confirm that it is symmetric.
S = exp(-dist.^2); issymmetric(S)
ans = logical
1
Perform spectral clustering. Specify 'Distance','precomputed' to perform clustering using the similarity matrix. Specify k=3 clusters, and set the 'LaplacianNormalization' name-value pair argument to use the normalized symmetric Laplacian matrix.
k = 3; % Number of clusters rng('default') % For reproducibility idx = spectralcluster(S,k,'Distance','precomputed','LaplacianNormalization','symmetric');
idx contains the cluster indices for each observation in X.
Visualize the result of clustering.
gscatter(X(:,1),X(:,2),idx);
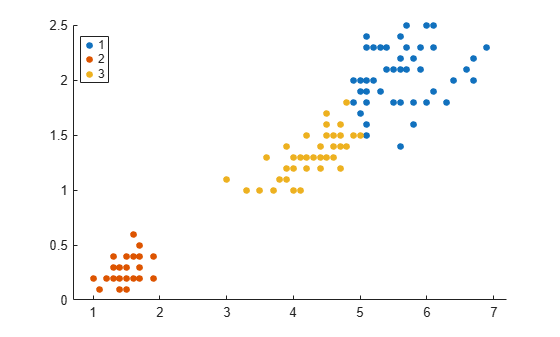
Tabulate the clustering results.
tabulate(idx)
Value Count Percent
1 48 32.00%
2 50 33.33%
3 52 34.67%
The Percent column shows the percentage of data points assigned to the three clusters.
Repeat spectral clustering using the data as input to spectralcluster. Specify 'NumNeighbors' as size(X,1), which corresponds to creating the similarity matrix S by connecting each point to all the remaining points.
idx2 = spectralcluster(X,k,'NumNeighbors',size(X,1),'LaplacianNormalization','symmetric'); gscatter(X(:,1),X(:,2),idx2);
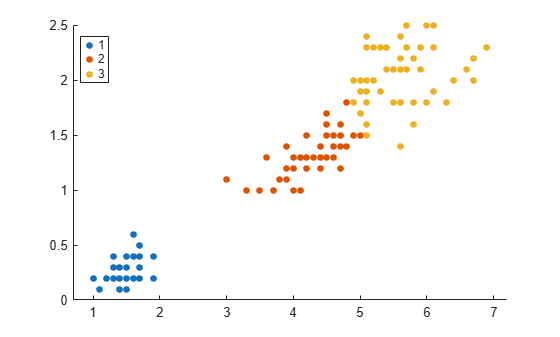
tabulate(idx2)
Value Count Percent
1 50 33.33%
2 52 34.67%
3 48 32.00%
The clustering results for both approaches are the same. The order of cluster assignments is different, even though the data points are clustered in the same way.
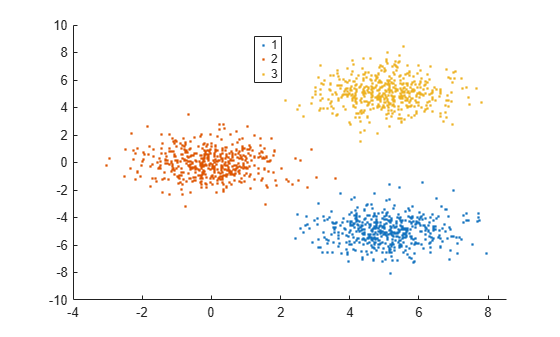
Find clusters in a data set, based on a specified search radius for creating a similarity graph.
Create data with 3 clusters, each containing 500 points.
rng('default') % For reproducibility N = 500; X = [mvnrnd([0 0],eye(2),N); ... mvnrnd(5*[1 -1],eye(2),N); ... mvnrnd(5*[1 1],eye(2),N)];
Specify a search radius of 2 for creating a similarity graph, and find 3 clusters in the data.
idx = spectralcluster(X,3,'SimilarityGraph','epsilon','Radius',2);
Visualize the result of clustering.
gscatter(X(:,1),X(:,2),idx);
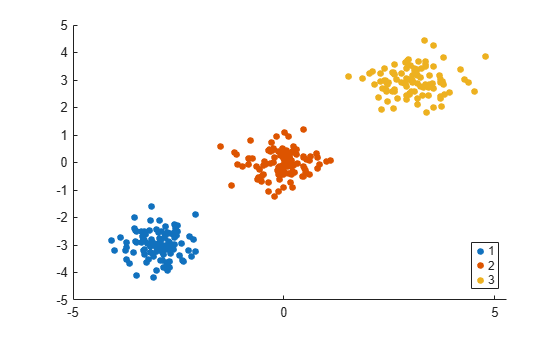
Find the eigenvalues and eigenvectors of the Laplacian matrix and use the values to confirm clustering results.
Randomly generate sample data with three well-separated clusters, each containing 100 points.
rng('default'); % For reproducibility n = 100; X = [randn(n,2)*0.5+3; randn(n,2)*0.5 randn(n,2)*0.5-3];
Estimate the number of clusters in the data by using the eigenvalues of the Laplacian matrix. Compute the five smallest eigenvalues (in magnitude) of the Laplacian matrix.
[~,~,D_temp] = spectralcluster(X,5)
D_temp = 5×1
-0.0000
-0.0000
-0.0000
0.0277
0.0296
Only the first three eigenvalues are approximately zero. The number of zero eigenvalues is a good indicator of the number of connected components in a similarity graph and, therefore, is a good estimate of the number of clusters in your data. So, k=3 is a good estimate of the number of clusters in X.
Find k=3 clusters and return the three smallest eigenvalues and corresponding eigenvectors of the Laplacian matrix.
[idx,V,D] = spectralcluster(X,3)
idx = 300×1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
⋮
V = 300×3
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
-0.0000 -0.0000 -0.1000
⋮
D = 3×1
10-16 ×
-0.3848
-0.4734
-0.5171
Elements of D correspond to the three smallest eigenvalues of the Laplacian matrix. The columns of V contain the eigenvectors corresponding to the eigenvalues in D. For well-separated clusters, the eigenvectors are indicator vectors. The eigenvectors have values of zero (or close to zero) for points that do not belong to a particular cluster, and nonzero values for points that belong to a particular cluster.
Visualize the result of clustering.
gscatter(X(:,1),X(:,2),idx);
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Consider using spectral clustering when the clusters in your data do not naturally correspond to convex regions.
From the spectral clustering algorithm, you can estimate the number of clusters
kas:For an example, see Estimate Number of Clusters and Perform Spectral Clustering.
Algorithms
Spectral clustering is a graph-based algorithm for clustering data points (or observations
in X). The algorithm involves constructing a graph, finding its Laplacian matrix, and
using this matrix to find k eigenvectors to split the graph
k ways. By default, the algorithm for
spectralcluster computes the normalized random-walk Laplacian matrix
using the method described by Shi-Malik [2].
spectralcluster also supports the unnormalized Laplacian matrix and the
normalized symmetric Laplacian matrix which uses the Ng-Jordan-Weiss method [3].
spectralcluster implements clustering as follows:
For each data point in
X, define a local neighborhood using either the radius search method or nearest neighbor method, as specified by the'SimilarityGraph'name-value pair argument (see Similarity Graph). Then, find the pairwise distances for all points i and j in the neighborhood.Convert the distances to similarity measures using the kernel transformation . The matrix S is the similarity matrix, and σ is the scale factor for the kernel, as specified using the
'KernelScale'name-value pair argument.Calculate the unnormalized Laplacian matrix L , the normalized random-walk Laplacian matrix Lrw, or the normalized symmetric Laplacian matrix Ls, depending on the value of the
'LaplacianNormalization'name-value pair argument.Create a matrix containing columns , where the columns are the k eigenvectors that correspond to the k smallest eigenvalues of the Laplacian matrix. If using Ls, normalize each row of V to have unit length.
Treating each row of V as a point, cluster the n points using k-means clustering (default) or k-medoids clustering, as specified by the
'ClusterMethod'name-value pair argument.Assign the original points in
Xto the same clusters as their corresponding rows in V.
References
[2] Shi, J., and J. Malik. “Normalized cuts and image segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Vol. 22, 2000, pp. 888–905.
[3] Ng, A.Y., M. Jordan, and Y. Weiss. “On spectral clustering: Analysis and an algorithm.” In Proceedings of the Advances in Neural Information Processing Systems 14. MIT Press, 2001, pp. 849–856.
Version History
Introduced in R2019b