선형 회귀
데이터 준비하기
회귀 피팅을 시작하려면 피팅 함수에 필요한 형식으로 데이터를 준비해야 합니다. 모든 회귀 기법은 배열 X의 입력 데이터와 별도의 벡터 y의 응답 변수 데이터로 시작하거나, 테이블 tbl의 입력 데이터와 tbl에 열로 포함된 응답 변수 데이터로 시작합니다. 입력 데이터의 각 행은 하나의 관측값을 나타냅니다. 각 열은 하나의 예측 변수를 나타냅니다.
테이블 tbl의 경우, 다음과 같이 'ResponseVar' 이름-값 쌍을 사용하여 응답 변수를 나타냅니다.
mdl = fitlm(tbl,'ResponseVar','BloodPressure');
응답 변수는 기본적으로 마지막 열입니다.
숫자로 된 범주형 예측 변수를 사용할 수 있습니다. 범주형 예측 변수는 취할 수 있는 값이 몇 가지로 고정되어 있는 변수입니다.
숫자형 배열
X에 대해서는'Categorical'이름-값 쌍을 사용하여 범주형 예측 변수를 나타냅니다. 예를 들어, 6개 예측 변수 중에서 예측 변수2와3이 범주형임을 나타내려면 다음과 같이 하십시오.mdl = fitlm(X,y,'Categorical',[2,3]); % or equivalently mdl = fitlm(X,y,'Categorical',logical([0 1 1 0 0 0]));
테이블
tbl의 경우, 피팅 함수는 다음 데이터형이 범주형이라고 가정합니다.논리형 벡터
categorical형 벡터
문자형 배열
string형 배열
숫자형 예측 변수가 범주형임을 나타내려는 경우
'Categorical'이름-값 쌍을 사용하십시오.
누락된 숫자형 데이터는 NaN으로 나타냅니다. 누락된 다른 데이터형의 데이터를 나타내려면 누락된 그룹 값 항목을 참조하십시오.
입력 데이터와 응답 변수 데이터에 테이블 사용
Excel® 스프레드시트에서 테이블을 생성하려면 다음과 같이 하십시오.
tbl = readtable('hospital.xls', ... 'ReadRowNames',true);
작업 공간 변수에서 테이블을 생성하려면 다음과 같이 하십시오.
load carsmall
tbl = table(MPG,Weight);
tbl.Year = categorical(Model_Year);입력 데이터에 숫자형 행렬, 응답 변수 데이터에 숫자형 벡터 사용
예를 들어, 작업 공간 변수에서 숫자형 배열을 생성하려면 다음과 같이 하십시오.
load carsmall
X = [Weight Horsepower Cylinders Model_Year];
y = MPG;Excel 스프레드시트에서 숫자형 배열을 생성하려면 다음과 같이 하십시오.
[X, Xnames] = xlsread('hospital.xls'); y = X(:,4); % response y is systolic pressure X(:,4) = []; % remove y from the X matrix
sex와 같이 숫자형이 아닌 항목은 X에 나타나지 않습니다.
피팅 방법 선택하기
모델을 데이터에 피팅하는 방법으로는 다음과 같이 세 가지가 있습니다.
최소제곱 피팅
fitlm을 사용하여 데이터에 대한 모델의 최소제곱 피팅을 생성할 수 있습니다. 이 방법은 모델의 형식을 확실히 알고 있으며 주로 모델의 모수를 찾아야 하는 경우 가장 적합합니다. 이 방법은 몇 가지 모델을 탐색하려는 경우에도 유용합니다. 몇 가지 도움이 되는 기법이 있기는 해도 이 방법에서는 수동으로 데이터를 검토하여 이상값을 삭제해야 합니다(품질을 검토하고 피팅된 모델 조정하기 항목 참조).
로버스트 피팅
RobustOpts 이름-값 쌍과 함께 fitlm을 사용하여 이상값의 영향을 거의 받지 않는 모델을 생성할 수 있습니다. 로버스트 피팅은 이상값을 수동으로 삭제해야 하는 문제를 없애줍니다. 그러나 step은 로버스트 피팅과 함께 동작하지 않습니다. 즉, 로버스트 피팅을 사용하는 경우 적합한 모델에 대한 단계적 탐색을 수행할 수 없습니다.
단계적 피팅
stepwiselm을 사용하여 모델을 찾고 모수를 모델에 피팅할 수 있습니다. stepwiselm은 상수 모델과 같은 특정 모델에서 시작되며, 더 이상 향상되지 않을 때까지 최대 일치(greedy) 방식으로 매번 최적의 항을 선택하여 한 번에 하나씩 항을 추가하거나 뺍니다. 단계적 피팅을 사용하여 관련 있는 항만 갖는 적합한 모델을 찾을 수 있습니다.
결과는 시작하는 모델에 따라 달라집니다. 일반적으로, 상수 모델로 시작하면 작은 모델이 생성됩니다. 더 많은 항으로 시작하면 더 복잡하지만 평균제곱오차가 더 작은 모델이 생성될 수 있습니다. Compare Large and Small Stepwise Models 항목을 참조하십시오.
로버스트 옵션은 단계적 피팅과 함께 사용할 수 없습니다. 따라서 단계적 피팅을 수행한 후 모델에 이상값이 있는지 검토하십시오(품질을 검토하고 피팅된 모델 조정하기 항목 참조).
특정 모델 또는 모델 범위 선택하기
선형 회귀 모델을 지정하는 방법으로는 여러 가지가 있습니다. 가장 간편한 방법을 사용하십시오.
fitlm의 경우, 지정하는 모델 사양이 바로 피팅 모델이 됩니다. 모델 사양을 지정하지 않을 경우 디폴트 값은 'linear'입니다.
stepwiselm의 경우, 지정하는 모델 사양이 시작 모델이 됩니다. 여기서 단계적 절차를 거쳐 향상을 시도합니다. 모델 사양을 지정하지 않을 경우 디폴트 시작 모델은 'constant'이며, 디폴트 상한 모델은 'interactions'입니다. Upper 이름-값 쌍을 사용하여 상한 모델을 변경할 수 있습니다.
참고
모델을 선택할 수 있는 다른 방법도 있습니다(예: lasso, lassoglm, sequentialfs 또는 plsregress 사용).
간략한 이름
| 이름 | 모델 유형 |
|---|---|
'constant' | 모델에 하나의 상수(절편) 항만 있습니다. |
'linear' | 각 예측 변수에 대해 모델에 하나의 절편 항과 여러 선형 항이 있습니다. |
'interactions' | 모델에 하나의 절편 항, 여러 선형 항, 서로 다른 예측 변수 쌍의 모든 곱(즉, 제곱 항 제외)이 있습니다. |
'purequadratic' | 모델에 하나의 절편 항과 여러 선형 항 및 제곱 항이 있습니다. |
'quadratic' | 모델에 하나의 절편 항과 여러 선형 항, 상호 작용, 제곱 항이 있습니다. |
'poly | 모델이 첫 번째 예측 변수에 차수 i까지의 모든 항을 포함하고 두 번째 예측 변수에 차수 j까지의 모든 항을 포함하는 식으로 진행되는 다항식입니다. 숫자 0부터 9까지 사용하십시오. 예를 들어, 'poly2111'은 상수항과 모든 선형 항 및 곱셈 항을 가지며, 예측 변수 1의 제곱 항도 포함합니다. |
예를 들어, 행렬 예측 변수와 함께 fitlm을 사용하여 상호 작용 모델을 지정하려면 다음과 같이 하십시오.
mdl = fitlm(X,y,'interactions');stepwiselm과 예측 변수로 구성된 테이블 tbl을 사용하여 모델을 지정하기 위해 상수 모델에서 시작하고 상한을 선형 모델로 둔다고 가정해 보겠습니다. tbl에서 응답 변수가 세 번째 열에 있다고 간주합니다.
mdl2 = stepwiselm(tbl,'constant', ... 'Upper','linear','ResponseVar',3);
항 행렬
항 행렬 T는 모델의 항을 지정하는 t×(p + 1) 행렬입니다. 여기서 t는 항 개수이고, p는 예측 변수 개수이며, +1은 응답 변수에 해당합니다. T(i,j)의 값은 항 i에 포함된 변수 j의 지수입니다.
예를 들어, 3개의 예측 변수 x1, x2, x3과 응답 변수 y를 x1, x2, x3, y의 순서로 포함하는 입력값이 있다고 가정하겠습니다. T의 각 행은 하나의 항을 나타냅니다.
[0 0 0 0]— 상수항(절편)[0 1 0 0]—x2또는x1^0 * x2^1 * x3^0[1 0 1 0]—x1*x3[2 0 0 0]—x1^2[0 1 2 0]—x2*(x3^2)
각 항의 끝에 있는 0은 응답 변수를 나타냅니다. 일반적으로 항 행렬에서 0으로 구성된 열 벡터는 응답 변수의 위치를 나타냅니다. 예측 변수와 응답 변수가 각각 행렬과 열 벡터에 있는 경우 각 행의 마지막 열에 응답 변수를 나타내는 0을 포함해야 합니다.
식
모델 사양의 식은 다음 형식의 문자형 벡터 또는 string형 스칼라입니다.
',y ~ terms'
y는 응답 변수 이름입니다.terms는 다음을 포함합니다.변수 이름
+(다음 변수를 포함함)-(다음 변수를 제외함):(상호 작용, 즉 항의 곱을 정의함)*(상호 작용과 모든 낮은 차수 항을 정의함)^(예측 변수를 거듭제곱함, 이는*를 반복하는 것과 동일함, 따라서^은 낮은 차수 항도 포함함)()(항을 그룹화함)
팁
식에는 기본적으로 상수항(절편)이 포함되어 있습니다. 모델에서 상수항을 제외하려면 식에 -1을 포함시키십시오.
예제:
'y ~ x1 + x2 + x3'는 변수가 3개이며 절편이 있는 선형 모델입니다.
'y ~ x1 + x2 + x3 - 1'은 변수가 3개이며 절편이 없는 선형 모델입니다.
'y ~ x1 + x2 + x3 + x2^2'은 변수가 3개이며 절편과 x2^2 항이 있는 모델입니다.
'y ~ x1 + x2^2 + x3'는 앞의 예제와 동일합니다. x2^2이 x2 항을 포함하기 때문입니다.
'y ~ x1 + x2 + x3 + x1:x2'는 x1*x2 항을 포함합니다.
'y ~ x1*x2 + x3'는 앞의 예제와 동일합니다. x1*x2 = x1 + x2 + x1:x2이기 때문입니다.
'y ~ x1*x2*x3 - x1:x2:x3'는 삼원 상호 작용을 제외한 x1, x2, x3 간의 모든 상호 작용을 가집니다.
'y ~ x1*(x2 + x3 + x4)'는 모든 선형 항과 함께 x1과 다른 변수 각각에 대한 곱을 가집니다.
예를 들어, 행렬 예측 변수와 함께 fitlm을 사용하여 상호 작용 모델을 지정하려면 다음과 같이 하십시오.
mdl = fitlm(X,y,'y ~ x1*x2*x3 - x1:x2:x3');stepwiselm과 예측 변수로 구성된 테이블 tbl을 사용하여 모델을 지정하기 위해 상수 모델에서 시작하고 상한을 선형 모델로 둔다고 가정해 보겠습니다. tbl의 응답 변수가 'y'로 명명되고 예측 변수가 'x1', 'x2', 'x3'으로 명명되었다고 가정합니다.
mdl2 = stepwiselm(tbl,'y ~ 1','Upper','y ~ x1 + x2 + x3');
모델을 데이터에 피팅하기
피팅에 사용할 수 있는 가장 일반적인 선택적 인수는 다음과 같습니다.
fitlm에서 로버스트 회귀를 설정하려는 경우'RobustOpts'이름-값 쌍을'on'으로 설정합니다.stepwiselm에서 적절한 상한 모델을 지정합니다(예:'Upper'를'linear'로 설정).'CategoricalVars'이름-값 쌍을 사용하여 범주형인 변수를 나타냅니다. 열 번호로 구성된 벡터를 제공합니다(예: 예측 변수1과6이 범주형임을 지정하려면[1 6]제공). 또는, 해당 변수가 범주형임을 나타내는1요소를 사용하여 데이터 열의 개수와 길이가 같은 논리형 벡터를 제공합니다. 7개의 예측 변수가 있고 예측 변수1과6이 범주형인 경우logical([1,0,0,0,0,1,0])을 지정합니다.테이블인 경우
'ResponseVar'이름-값 쌍을 사용하여 응답 변수를 지정합니다. 디폴트 값은 배열의 마지막 열입니다.
예를 들면 다음과 같습니다.
mdl = fitlm(X,y,'linear', ... 'RobustOpts','on','CategoricalVars',3); mdl2 = stepwiselm(tbl,'constant', ... 'ResponseVar','MPG','Upper','quadratic');
품질을 검토하고 피팅된 모델 조정하기
모델을 피팅한 후 결과를 검토하고 조정합니다.
모델 표시
선형 회귀 모델은 모델 이름을 입력하거나 disp(mdl)을 입력하는 경우 여러 진단을 표시합니다. 이 표시는 피팅된 모델이 데이터를 적절히 나타내는지 여부를 확인할 수 있는 기본적인 정보 몇 가지를 제공합니다.
예를 들어, 5개 예측 변수 중 2개가 없고 절편 항이 없는 상태로 생성된 데이터에 선형 모델을 피팅해 보겠습니다.
X = randn(100,5); y = X*[1;0;3;0;-1] + randn(100,1); mdl = fitlm(X,y)
mdl =
Linear regression model:
y ~ 1 + x1 + x2 + x3 + x4 + x5
Estimated Coefficients:
Estimate SE tStat pValue
_________ ________ ________ __________
(Intercept) 0.038164 0.099458 0.38372 0.70205
x1 0.92794 0.087307 10.628 8.5494e-18
x2 -0.075593 0.10044 -0.75264 0.45355
x3 2.8965 0.099879 29 1.1117e-48
x4 0.045311 0.10832 0.41831 0.67667
x5 -0.99708 0.11799 -8.4504 3.593e-13
Number of observations: 100, Error degrees of freedom: 94
Root Mean Squared Error: 0.972
R-squared: 0.93, Adjusted R-Squared: 0.926
F-statistic vs. constant model: 248, p-value = 1.5e-52
이 경우 다음과 같은 결과가 생성됩니다.
Estimate열에 각 계수에 대해 추정된 값이 표시됩니다. 이러한 값은 실제 값[0;1;0;3;0;-1]에 상당히 가깝습니다.계수 추정값에 대한 표준 오차 열이 있습니다.
예측 변수 1, 3, 5에 대해 보고된
pValue(정규 오차 가정에 따라 t 통계량(tStat)에서 도출됨)가 매우 작습니다. 이 3개의 예측 변수가 응답 변수 데이터y를 생성하는 데 사용되었습니다.(Intercept),x2,x4의pValue가 0.01보다 훨씬 더 큽니다. 이 3개의 예측 변수가 응답 변수 데이터y를 생성하는 데 사용되지 않았습니다., 수정된 및 F 통계량이 표시됩니다.
분산분석(ANOVA)
피팅된 모델의 품질을 검토하려면 분산분석표를 참조하십시오. 예를 들어, 5개 예측 변수를 갖는 선형 모델에 anova를 사용해 보겠습니다.
tbl = anova(mdl)
tbl=6×5 table
SumSq DF MeanSq F pValue
_______ __ _______ _______ __________
x1 106.62 1 106.62 112.96 8.5494e-18
x2 0.53464 1 0.53464 0.56646 0.45355
x3 793.74 1 793.74 840.98 1.1117e-48
x4 0.16515 1 0.16515 0.17498 0.67667
x5 67.398 1 67.398 71.41 3.593e-13
Error 88.719 94 0.94382
이 테이블은 모델 표시 화면과 다소 다른 결과를 제공합니다. 이 테이블은 x2와 x4의 효과가 유의미하지 않다는 것을 명확히 보여줍니다. 목표에 따라 모델에서 x2와 x4를 제거해 보십시오.
진단 플롯
진단 플롯은 이상값을 식별하고 모델 또는 피팅에 존재하는 다른 문제를 살펴보는 데 도움이 됩니다. 예를 들어, carsmall 데이터를 불러오고 MPG 모델을 Cylinders(범주형)와 Weight에 대한 함수로 만들어 보겠습니다.
load carsmall tbl = table(Weight,MPG,Cylinders); tbl.Cylinders = categorical(tbl.Cylinders); mdl = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2');
데이터와 모델에 대한 지렛대값 플롯을 생성합니다.
plotDiagnostics(mdl)
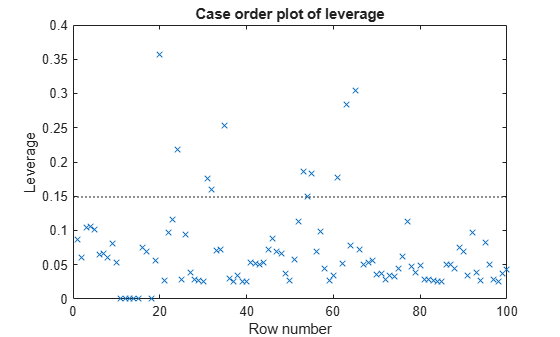
높은 지렛대값을 갖는 몇 개의 점이 있습니다. 그러나, 이 플롯은 높은 지렛대값을 갖는 점이 이상값인지 여부를 표시하지 않습니다.
쿡의 거리(Cook’s Distance)가 큰 점을 찾습니다.
plotDiagnostics(mdl,'cookd')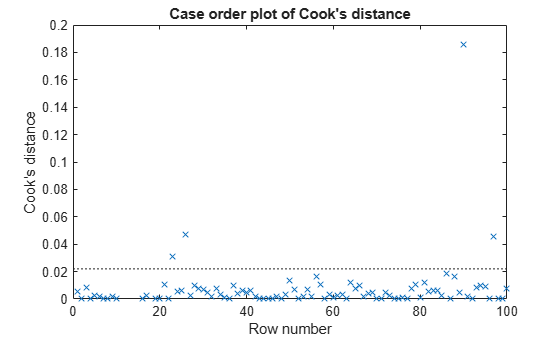
쿡의 거리가 큰 점이 하나 있습니다. 이 점을 식별한 후 모델에서 제거합니다. 데이터 커서를 사용하여 이상값을 클릭해 이를 식별하거나 다음과 같이 프로그래밍 방식으로 이를 식별할 수 있습니다.
[~,larg] = max(mdl.Diagnostics.CooksDistance); mdl2 = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2','Exclude',larg);
잔차 — 훈련 데이터에 대한 모델 품질
모델이나 데이터에서 오차, 이상값 또는 상관관계를 파악하는 데 도움이 되는 잔차 플롯이 여러 개 있습니다. 가장 단순한 잔차 플롯은 잔차 범위와 빈도를 보여주는 디폴트 히스토그램 플롯과, 잔차의 분포가 분산이 일치하는 정규분포와 어떻게 비교되는지를 보여주는 확률 플롯입니다.
다음과 같이 잔차를 검토합니다.
plotResiduals(mdl)
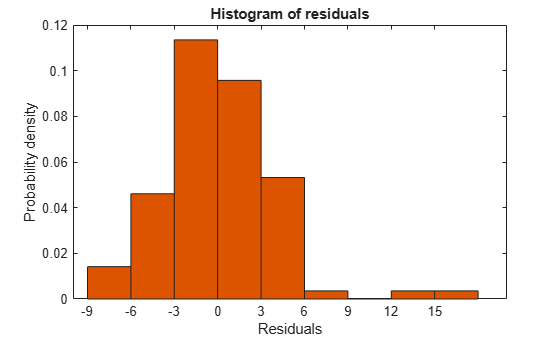
12보다 큰 관측값이 잠재적인 이상값입니다.
plotResiduals(mdl,'probability')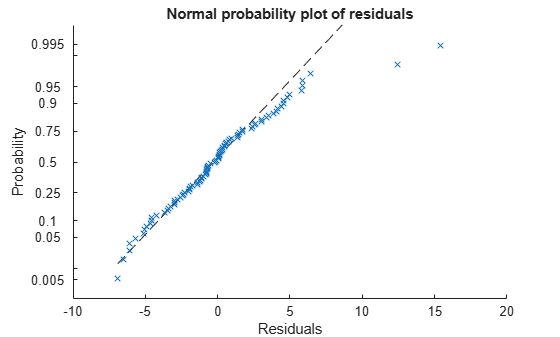
이 플롯에도 두 개의 잠재적인 이상값이 보입니다. 그 외에는, 확률 플롯이 거의 직선처럼 보입니다. 즉, 정규분포된 잔차에 대한 적절한 피팅이라고 할 수 있습니다.
다음과 같이 이 두 개의 이상값을 식별하여 데이터에서 제거할 수 있습니다.
outl = find(mdl.Residuals.Raw > 12)
outl = 2×1
90
97
이상값을 제거하기 위해 Exclude 이름-값 쌍을 사용합니다.
mdl3 = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2','Exclude',outl);
mdl2의 잔차 플롯을 검토합니다.
plotResiduals(mdl3)
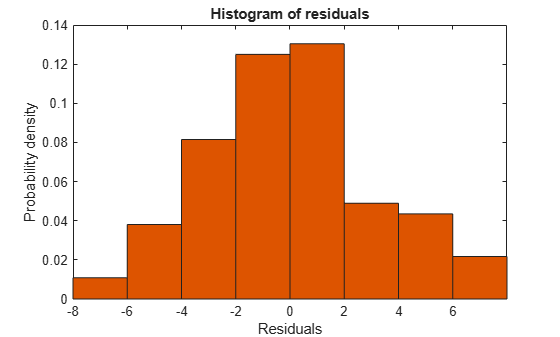
새 잔차 플롯은 특별히 눈에 띄는 문제 없이 상당히 대칭적인 것처럼 보입니다. 그러나, 잔차 사이에 일부 계열 상관이 있을 수 있습니다. 새 플롯을 생성하여 이러한 효과가 존재하는지 확인합니다.
plotResiduals(mdl3,'lagged')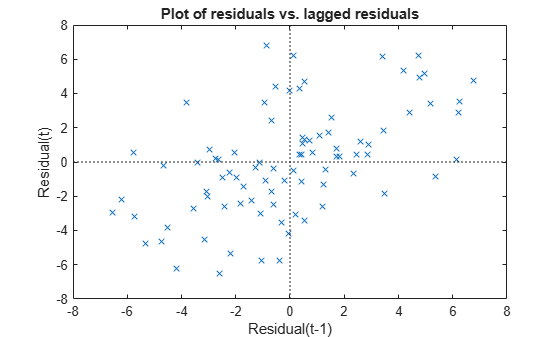
산점도 플롯을 보면 다른 두 사분면보다 오른쪽 위 사분면과 왼쪽 아래 사분면에 더 많은 십자 표식이 있습니다. 이는 잔차 사이에 양의 계열 상관이 있음을 나타냅니다.
또 다른 잠재적인 문제는 큰 관측값에 대해 잔차가 큰 경우에 발생합니다. 현재 모델에 이러한 문제가 있는지 확인합니다.
plotResiduals(mdl3,'fitted')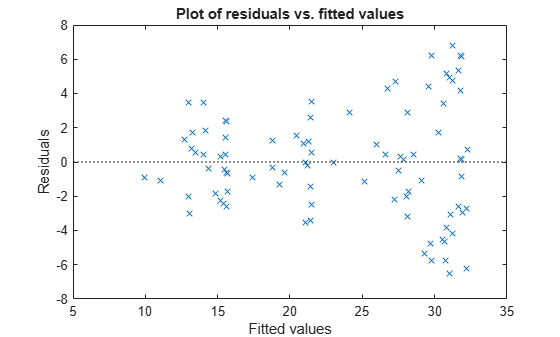
피팅된 값이 클수록 잔차가 커지는 경향이 있습니다. 아마도 모델 오차가 측정값에 비례할 것입니다.
예측 변수 효과를 파악할 수 있는 플롯
이 예제에서는 이용 가능한 다양한 플롯을 사용하여 각 예측 변수가 회귀 모델에 미치는 효과를 파악하는 방법을 보여줍니다.
응답 변수에 대한 슬라이스 플롯을 검토합니다. 이 플롯은 각 예측 변수의 효과를 개별적으로 표시합니다.
plotSlice(mdl)
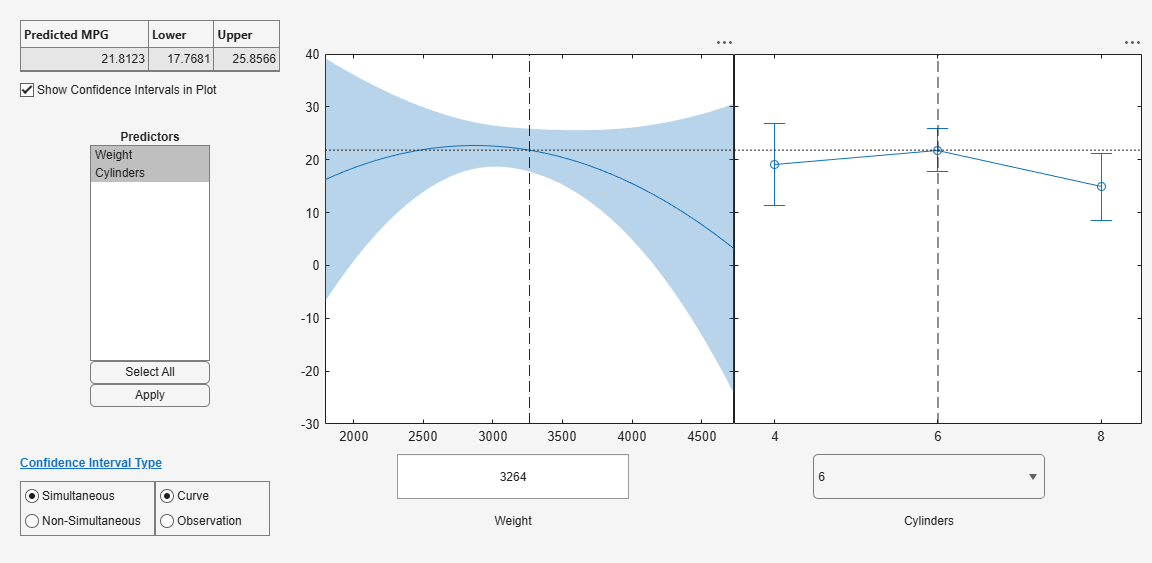
개별 예측 변수 값을 끌어서 놓을 수 있습니다. 이러한 예측 변수 값은 파란색 세로 파선으로 표시되어 있습니다. 또한 동시 신뢰한계와 비동시 신뢰한계 중에서 선택할 수도 있습니다. 이는 빨간색 곡선 파선으로 표시되어 있습니다.
효과 플롯을 사용하여 예측 변수가 응답 변수에 미치는 효과를 나타내는 다른 뷰를 표시합니다.
plotEffects(mdl)
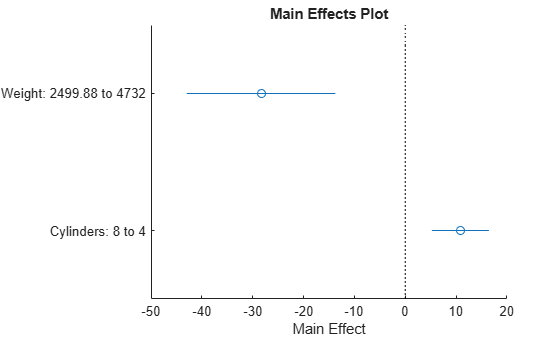
이 플롯은 Weight를 약 2500에서 4732로 변경하면 MPG가 30(상부 파란색 원의 위치) 정도 감소한다는 것을 보여줍니다. 또한, 기통 개수를 8에서 4로 변경하면 MPG가 10(하부 파란색 원) 정도 상승한다는 것도 보여줍니다. 파란색 가로선은 이러한 예측값에 대한 신뢰구간을 나타냅니다. 예측값은 한 예측 변수가 변경될 때 다른 예측 변수에 대한 평균을 구하는 방식으로 얻습니다. 두 예측 변수 간에 상관관계가 있는 이러한 경우에는 결과를 해석할 때 주의해야 합니다.
한 예측 변수가 변경될 때 다른 예측 변수에 대한 평균을 구하는 방법으로 이에 대한 효과를 확인하는 대신, 상호 작용 플롯에서 결합 상호 작용을 검토합니다.
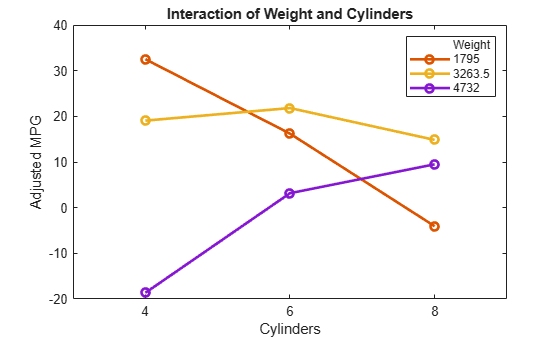
plotInteraction(mdl,'Weight','Cylinders')
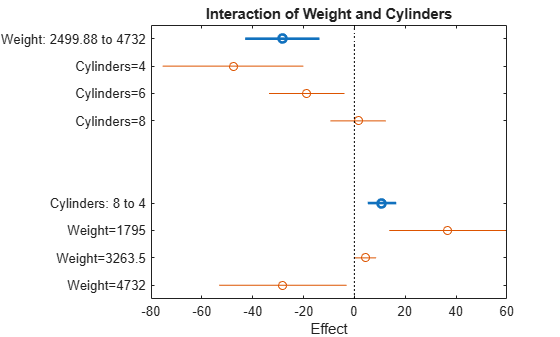
상호 작용 플롯은 한 예측 변수가 고정된 상태에서 다른 예측 변수를 변경할 때 이것이 미치는 효과를 보여줍니다. 이 경우, 이 플롯은 훨씬 더 많은 정보를 제공합니다. 예를 들어, 여기서는 상대적으로 가벼운 자동차(Weight = 1795)에서 기통 수를 줄이면 주행 거리가 늘어나지만, 상대적으로 무거운 자동차(Weight = 4732)에서 기통 수를 줄이면 주행 거리가 줄어든다는 것을 보여줍니다.
이 상호 작용에 대해 더 자세히 살펴보려면 예측값이 포함된 상호 작용 플롯을 살펴보십시오. 이 플롯은 한 예측 변수를 고정된 상태로 유지하면서 다른 예측 변수를 변경하여 이것이 미치는 효과를 곡선으로 플로팅합니다. 고정된 여러 개수의 기통에 대한 상호 작용을 살펴보십시오.
plotInteraction(mdl,'Cylinders','Weight','predictions')
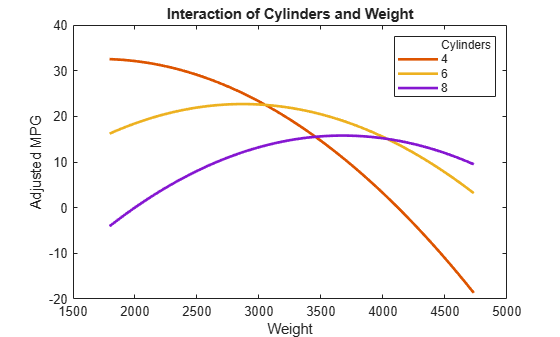
이제, 고정된 여러 무게 수준과의 상호 작용을 살펴보십시오.
plotInteraction(mdl,'Weight','Cylinders','predictions')
항 효과를 파악할 수 있는 플롯
이 예제에서는 이용 가능한 다양한 플롯을 사용하여 회귀 모델에서 각 항의 효과를 파악하는 방법을 보여줍니다.
추가 변수로 Weight^2을 사용하여 추가 변수 플롯을 생성합니다.
plotAdded(mdl,'Weight^2')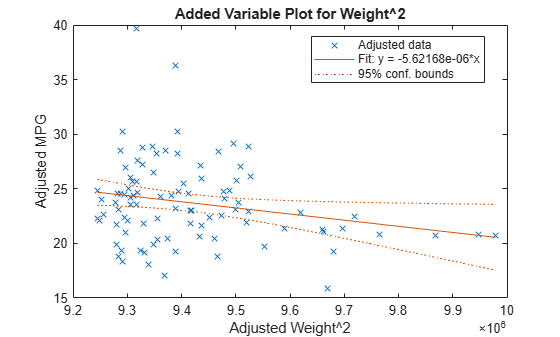
이 플롯은 Weight^2과 MPG를 모두 Weight^2이 아닌 다른 항에 피팅한 결과를 보여줍니다. plotAdded를 사용하는 이유는 Weight^2을 추가하여 모델에서 추가로 얻게 되는 개선 사항이 무엇인지 파악하기 위해서입니다. 이러한 점들에 대한 직선 피팅의 계수는 전체 모델에서 Weight^2에 대한 계수입니다. Weight^2 예측 변수는 계수 테이블 표시에서 확인할 수 있듯이 유의성 경계값(pValue < 0.05)을 약간 초과합니다. 플롯에서도 이를 확인할 수 있습니다. 신뢰한계가 가로선(상수 y)을 포함하지 못하는 것으로 보이므로 기울기가 0인 모델은 데이터와 일치하지 않습니다.
모델 전체에 대한 추가 변수 플롯을 생성합니다.
plotAdded(mdl)
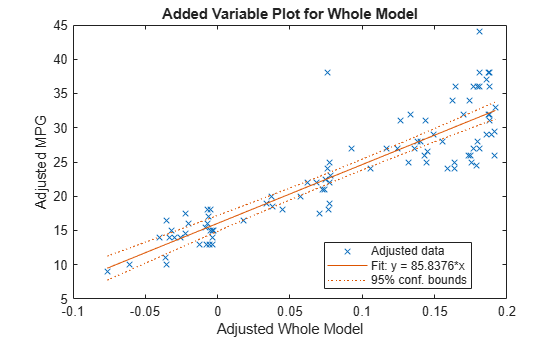
모델이 전체적으로 매우 유의미하므로, 신뢰한계 내에 가로선을 포함하기는 어렵습니다. 직선의 기울기는 최적 피팅 방향으로 놓여 있는 예측 변수에 대한 피팅의 기울기입니다. 즉, 계수 벡터의 노름(Norm)입니다.
모델 변경하기
모델을 변경하는 방법으로는 두 가지가 있습니다.
step— 한 번에 하나의 항을 더하거나 뺍니다. 여기서step은 추가하거나 제거할 가장 중요한 항을 선택합니다.addTerms및removeTerms— 지정된 항을 추가하거나 제거합니다. 특정 모델 또는 모델 범위 선택하기에 설명된 형식 중 하나로 항을 지정합니다.
stepwiselm을 사용하여 모델을 생성한 경우, 서로 다른 상부 또는 하부 모델을 지정하는 경우에만 step을 적용할 수 있습니다. RobustOpts를 사용하여 모델을 피팅하는 경우에는 step을 적용할 수 없습니다.
carbig 데이터에서 가져온 주행 거리에 대한 선형 모델을 예로 들어 보겠습니다.
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,'linear','ResponseVar','MPG')
mdl =
Linear regression model:
MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ ________ __________
(Intercept) 45.251 2.456 18.424 7.0721e-55
Acceleration -0.023148 0.1256 -0.1843 0.85388
Displacement -0.0060009 0.0067093 -0.89441 0.37166
Horsepower -0.043608 0.016573 -2.6312 0.008849
Weight -0.0052805 0.00081085 -6.5123 2.3025e-10
Number of observations: 392, Error degrees of freedom: 387
Root Mean Squared Error: 4.25
R-squared: 0.707, Adjusted R-Squared: 0.704
F-statistic vs. constant model: 233, p-value = 9.63e-102
최대 10개 스텝까지 step을 사용하여 모델을 개선해 봅니다.
mdl1 = step(mdl,'NSteps',10)1. Adding Displacement:Horsepower, FStat = 87.4802, pValue = 7.05273e-19
mdl1 =
Linear regression model:
MPG ~ 1 + Acceleration + Weight + Displacement*Horsepower
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ _______ __________
(Intercept) 61.285 2.8052 21.847 1.8593e-69
Acceleration -0.34401 0.11862 -2.9 0.0039445
Displacement -0.081198 0.010071 -8.0623 9.5014e-15
Horsepower -0.24313 0.026068 -9.3265 8.6556e-19
Weight -0.0014367 0.00084041 -1.7095 0.088166
Displacement:Horsepower 0.00054236 5.7987e-05 9.3531 7.0527e-19
Number of observations: 392, Error degrees of freedom: 386
Root Mean Squared Error: 3.84
R-squared: 0.761, Adjusted R-Squared: 0.758
F-statistic vs. constant model: 246, p-value = 1.32e-117
단 한 번의 변경 후에 step이 중지됩니다.
모델을 단순화하기 위해 mdl1에서 Acceleration 항과 Weight 항을 제거합니다.
mdl2 = removeTerms(mdl1,'Acceleration + Weight')mdl2 =
Linear regression model:
MPG ~ 1 + Displacement*Horsepower
Estimated Coefficients:
Estimate SE tStat pValue
__________ _________ _______ ___________
(Intercept) 53.051 1.526 34.765 3.0201e-121
Displacement -0.098046 0.0066817 -14.674 4.3203e-39
Horsepower -0.23434 0.019593 -11.96 2.8024e-28
Displacement:Horsepower 0.00058278 5.193e-05 11.222 1.6816e-25
Number of observations: 392, Error degrees of freedom: 388
Root Mean Squared Error: 3.94
R-squared: 0.747, Adjusted R-Squared: 0.745
F-statistic vs. constant model: 381, p-value = 3e-115
mdl2는 Displacement와 Horsepower만 사용하며, Adjusted R-Squared 메트릭의 mdl1만큼 데이터에 거의 적합한 피팅을 가집니다.
새 데이터에 대한 응답 변수를 예측하거나 시뮬레이션하기
LinearModel 객체는 새 데이터에 대한 응답 변수를 예측하거나 시뮬레이션하는 세 가지 함수(predict, feval, random)를 제공합니다.
predict
predict 함수를 사용하여 예측하고 예측값에 대한 신뢰구간을 구합니다.
carbig 데이터를 불러오고 Acceleration, Displacement, Horsepower, Weight 예측 변수에 대한 응답 변수 MPG의 디폴트 선형 모델을 만듭니다.
load carbig
X = [Acceleration,Displacement,Horsepower,Weight];
mdl = fitlm(X,MPG);최솟값, 평균값, 최댓값에서 예측 변수로 구성된 3행 배열을 생성합니다. X에는 NaN 값이 몇 개 포함되어 있으므로 mean 함수에 대해 "omitnan" 옵션을 지정하십시오. min 함수와 max 함수는 기본적으로 계산에서 NaN 값을 제외합니다.
Xnew = [min(X);mean(X,"omitnan");max(X)];모델 응답 변수의 예측값과 이 예측값에 대한 신뢰구간을 구합니다.
[NewMPG, NewMPGCI] = predict(mdl,Xnew)
NewMPG = 3×1
34.1345
23.4078
4.7751
NewMPGCI = 3×2
31.6115 36.6575
22.9859 23.8298
0.6134 8.9367
평균 응답 변수의 신뢰한계가 최소 응답 변수 또는 최대 응답 변수의 신뢰한계보다 좁습니다.
feval
feval 함수를 사용하여 응답 변수를 예측합니다. 테이블에서 모델을 생성하는 경우, feval이 predict보다 응답 변수를 예측하는 데 더 편리한 경우가 많습니다. 새 예측 변수 데이터가 생겼을 때 테이블이나 행렬을 만들지 않고 feval로 전달할 수 있습니다. 그러나, feval은 신뢰한계를 제공하지 않습니다.
carbig 데이터 세트를 불러오고 예측 변수 Acceleration, Displacement, Horsepower, Weight에 대한 응답 변수 MPG의 디폴트 선형 모델을 만듭니다.
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,"linear",ResponseVar="MPG");
예측 변수의 평균값에 대한 모델 응답 변수를 예측합니다.
NewMPG = feval(mdl,mean(Acceleration,"omitnan"),mean(Displacement,"omitnan"),mean(Horsepower,"omitnan"),mean(Weight,"omitnan"))
NewMPG = 23.4078
random
random 함수를 사용하여 응답 변수를 시뮬레이션합니다. random 함수는 새 랜덤 응답 변수 값을 시뮬레이션합니다. 이 값은 평균 예측값에 훈련 데이터와 동일한 분산을 갖는 확률 교란을 더한 값과 같습니다.
carbig 데이터를 불러오고 Acceleration, Displacement, Horsepower, Weight 예측 변수에 대한 응답 변수 MPG의 디폴트 선형 모델을 만듭니다.
load carbig
X = [Acceleration,Displacement,Horsepower,Weight];
mdl = fitlm(X,MPG);최솟값, 평균값, 최댓값에서 예측 변수로 구성된 3행 배열을 생성합니다.
Xnew = [min(X);mean(X,"omitnan");max(X)];어느 정도의 임의성을 포함하는 예측된 새 모델 응답 변수를 생성합니다.
rng("default") % for reproducibility NewMPG = random(mdl,Xnew)
NewMPG = 3×1
36.4178
31.1958
-4.8176
MPG의 음수 값은 합당하지 않아 보이므로 두 번 더 예측을 시도합니다.
NewMPG = random(mdl,Xnew)
NewMPG = 3×1
37.7959
24.7615
-0.7783
NewMPG = random(mdl,Xnew)
NewMPG = 3×1
32.2931
24.8628
19.9715
확실히, Xnew의 세 번째(최댓값) 행에 대한 예측은 신뢰할 수 없습니다.
피팅된 모델 공유하기
아래의 mdl과 같은 선형 회귀 모델이 있다고 가정하겠습니다.
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,'linear','ResponseVar','MPG');
다음과 같은 방법으로 이 모델을 다른 사람들과 공유할 수 있습니다.
모델의 정보를 표시합니다.
mdl
mdl =
Linear regression model:
MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ ________ __________
(Intercept) 45.251 2.456 18.424 7.0721e-55
Acceleration -0.023148 0.1256 -0.1843 0.85388
Displacement -0.0060009 0.0067093 -0.89441 0.37166
Horsepower -0.043608 0.016573 -2.6312 0.008849
Weight -0.0052805 0.00081085 -6.5123 2.3025e-10
Number of observations: 392, Error degrees of freedom: 387
Root Mean Squared Error: 4.25
R-squared: 0.707, Adjusted R-Squared: 0.704
F-statistic vs. constant model: 233, p-value = 9.63e-102
모델 정의와 계수를 제공합니다.
mdl.Formula
ans = MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
mdl.CoefficientNames
ans = 1×5 cell
{'(Intercept)'} {'Acceleration'} {'Displacement'} {'Horsepower'} {'Weight'}
mdl.Coefficients.Estimate
ans = 5×1
45.2511
-0.0231
-0.0060
-0.0436
-0.0053
참고 항목
fitlm | anova | stepwiselm | predict | LinearModel | plotResiduals | lasso | sequentialfs