이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
dbscan
잡음이 있는 응용 사례의 밀도 기반 공간 군집화(DBSCAN)
구문
설명
예제
DBSCAN을 디폴트 유클리드 거리 측정법과 함께 사용하여 2차원 원형 데이터 세트를 군집화합니다. 또한 이 데이터 세트를 DBSCAN과 제곱 유클리드 거리 측정법을 사용하여 군집화한 결과와, k-평균 군집화와 제곱 유클리드 거리 측정법을 사용하여 군집화한 결과를 비교합니다.
두 개의 잡음 있는 원을 포함하는 합성 데이터를 생성합니다.
rng('default') % For reproducibility % Parameters for data generation N = 300; % Size of each cluster r1 = 0.5; % Radius of first circle r2 = 5; % Radius of second circle theta = linspace(0,2*pi,N)'; X1 = r1*[cos(theta),sin(theta)]+ rand(N,1); X2 = r2*[cos(theta),sin(theta)]+ rand(N,1); X = [X1;X2]; % Noisy 2-D circular data set
데이터 세트를 시각화합니다.
scatter(X(:,1),X(:,2))
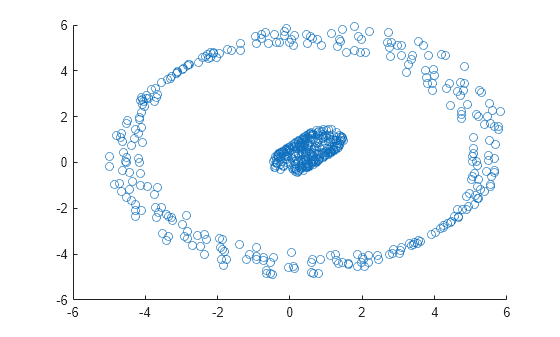
이 플롯은 데이터 세트에 2개의 고유한 군집이 포함되어 있음을 나타냅니다.
데이터에 대해 DBSCAN 군집화를 수행합니다. epsilon 값을 1로 지정하고 minpts 값을 5로 지정합니다.
idx = dbscan(X,1,5); % The default distance metric is Euclidean distance군집화를 시각화합니다.
gscatter(X(:,1),X(:,2),idx);
title('DBSCAN Using Euclidean Distance Metric')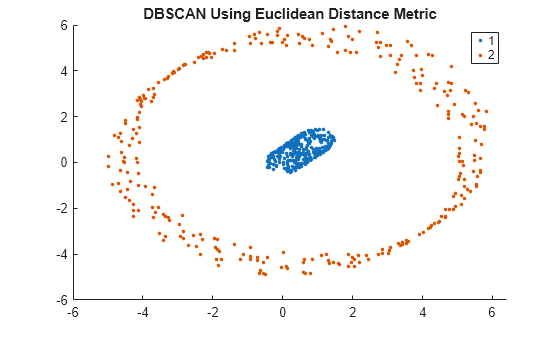
DBSCAN은 유클리드 거리 측정법을 사용하여 데이터 세트에서 2개의 군집을 올바르게 식별합니다.
제곱 유클리드 거리 측정법을 사용하여 DBSCAN 군집화를 수행합니다. epsilon 값을 1로 지정하고 minpts 값을 5로 지정합니다.
idx2 = dbscan(X,1,5,'Distance','squaredeuclidean');
군집화를 시각화합니다.
gscatter(X(:,1),X(:,2),idx2);
title('DBSCAN Using Squared Euclidean Distance Metric')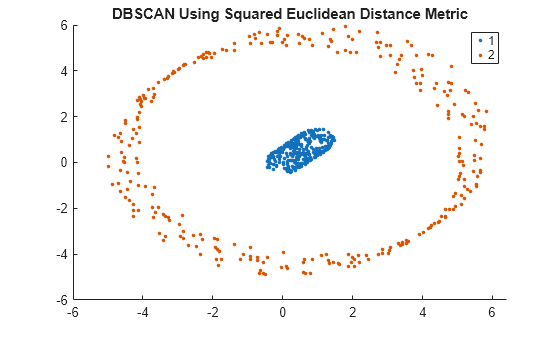
DBSCAN은 제곱 유클리드 거리 측정법을 사용하여 데이터 세트에서 2개의 군집을 올바르게 식별합니다.
제곱 유클리드 거리 측정법을 사용하여 k-평균 군집화를 수행합니다. k = 2로 군집 개수를 지정합니다.
kidx = kmeans(X,2); % The default distance metric is squared Euclidean distance군집화를 시각화합니다.
gscatter(X(:,1),X(:,2),kidx);
title('K-Means Using Squared Euclidean Distance Metric')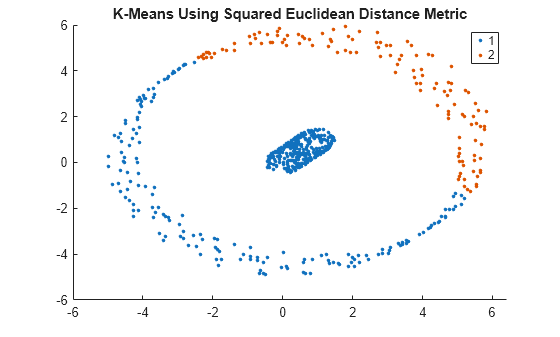
k-평균 군집화는 제곱 유클리드 거리 측정법을 사용하면 데이터 세트에서 2개의 군집을 올바르게 식별하지 못합니다.
관측값 간의 쌍별 거리 행렬을 dbscan 함수의 입력값으로 사용하여 DBSCAN 군집화를 수행하고 이상값과 핵심점의 개수를 찾습니다. 데이터 세트는 차량 주변 물체의 좌표를 포함하는 라이다 스캔(3차원 점의 집합으로 저장됨)입니다.
물체의 x, y, z 좌표를 불러옵니다.
load('lidar_subset.mat')
loc = lidar_subset;차량 주위의 환경을 강조 표시하기 위해 관심 영역을 차량의 왼쪽과 오른쪽에 20m 및 차량의 앞과 뒤에 20m 간격을 갖는 도로의 표면 위 영역으로 설정합니다.
xBound = 20; % in meters yBound = 20; % in meters zLowerBound = 0; % in meters
데이터를 지정된 영역 내의 점만 포함하도록 자릅니다.
indices = loc(:,1) <= xBound & loc(:,1) >= -xBound ... & loc(:,2) <= yBound & loc(:,2) >= -yBound ... & loc(:,3) > zLowerBound; loc = loc(indices,:);
데이터를 2차원 산점도 플롯으로 시각화합니다. 차량을 강조 표시하기 위해, 플롯에 주석을 추가합니다.
scatter(loc(:,1),loc(:,2),'.'); annotation('ellipse',[0.48 0.48 .1 .1],'Color','red')

점 집합(빨간색 원)의 중심에는 차량의 지붕과 후드가 있습니다. 그 외 모든 점은 장애물입니다.
pdist2 함수를 사용하여 관측값 간의 쌍별 거리 행렬 D를 미리 계산합니다.
D = pdist2(loc,loc);
쌍별 거리와 함께 dbscan을 사용하여 데이터를 군집화합니다. epsilon 값을 2로 지정하고 minpts 값을 50으로 지정합니다.
[idx, corepts] = dbscan(D,2,50,'Distance','precomputed');
결과를 시각화하고 특정 군집을 강조 표시하기 위해 그림에 주석을 추가합니다.
numGroups = length(unique(idx)); gscatter(loc(:,1),loc(:,2),idx,hsv(numGroups)); annotation('ellipse',[0.54 0.41 .07 .07],'Color','red') grid

산점도에서 볼 수 있듯이, dbscan은 11개의 군집을 식별하고 차량을 별도의 군집에 배치합니다.
dbscan이 빨간 원 안의 점 그룹(3,–4 중심)을 플롯의 남동쪽 사분면에 있는 점 그룹과 동일한 군집(그룹 7)에 할당했습니다. 원래 기대한 것은 이들 그룹이 서로 다른 군집에 배치되는 것이었습니다. 큰 군집을 나누고 점들을 더 세분화하려면 더 작은 epsilon 값을 사용해 볼 수 있습니다.
이 함수는 또한 데이터에서 일부 이상값(idx 값이 –1인 경우)을 식별합니다. dbscan이 이상값으로 식별하는 점의 개수를 구합니다.
sum(idx == -1)
ans = 412
dbscan은 19,070개의 관측값 중 412개를 이상값으로 식별합니다.
dbscan이 핵심점으로 식별하는 점의 개수를 구합니다. corepts 값이 1이면 핵심점을 나타냅니다.
sum(corepts == 1)
ans = 18446
dbscan은 18,446개의 관측값을 핵심점으로 식별합니다.
예제를 더 보려면 Determine Values for DBSCAN Parameters 항목을 참조하십시오.
입력 인수
이름-값 인수
출력 인수
세부 정보
팁
다수의
epsilon값을 반복 처리할 때 속도를 높이려면D를dbscan의 입력값으로 전달해 보십시오. 이 방식을 사용하면 함수가 반복의 모든 점에서 거리를 계산할 필요가 없습니다.pdist2를 사용하여D를 미리 계산하는 경우,pdist2의'Smallest'또는'Largest'이름-값 쌍 인수를 지정하여D의 열을 선택하거나 정렬하지 마십시오.dbscan은D가 정사각 행렬이어야 하기 때문에 n개보다 적은 거리를 선택하면 오류가 발생합니다.D의 각 열에서 거리를 정렬하면D의 해석에 손실이 발생하고dbscan함수에서 사용할 경우 의미 없는 결과가 나올 수 있습니다.효율적인 메모리 사용을 위해,
D가 클 경우에는D를 숫자형 행렬이 아닌 논리형 행렬로dbscan에 전달해 보십시오. 기본적으로, MATLAB®은 숫자형 행렬의 각 값은 8바이트(64비트)를 사용하여 저장하고, 논리형 행렬의 각 값은 1바이트(8비트)를 사용하여 저장합니다.minpts의 값을 선택하려면 입력 데이터의 차원 수에 1을 더한 것보다 크거나 같은 값을 고려하십시오[1]. 예를 들어, n×p 행렬X의 경우'minpts'를 p+1과 같거나 더 큰 값을 설정합니다.epsilon의 값을 선택할 때 가능한 한 가지 전략은X에 대한 k-거리 그래프를 생성하는 것입니다.X의 각 점에 대해 k번째로 가까운 점까지의 거리를 구하고, 정렬된 점을 이 거리에 따라 플로팅합니다. 일반적으로 그래프에는 무릎(knee)이 포함됩니다. 무릎에 해당하는 거리는 점이 이상값(잡음) 영역으로 벗어나기 시작하는 영역이기 때문에 일반적으로epsilon으로 선택하는 데 적합합니다[1].
알고리즘
DBSCAN은 데이터에서 군집과 잡음을 발견하도록 설계된 밀도 기반 군집화 알고리즘입니다. 알고리즘은 핵심점, 경계점, 잡음점이라는 세 종류의 점을 식별합니다[1].
dbscan함수는epsilon및minpts에 지정된 값에 따라 다음과 같이 알고리즘을 구현합니다.입력 데이터 세트
X에서 첫 번째 레이블이 없는 관측값 x1을 현재 점으로 선택하고, 첫 번째 군집 레이블 C를 1로 초기화합니다.현재 점의 엡실론 이웃
epsilon내에 있는 점 집합을 구합니다. 이 점들이 이웃입니다.이웃 개수가
minpts보다 적으면 현재 점을 잡음점(또는 이상값)으로 레이블 지정합니다. 4단계로 이동합니다.참고
dbscan은 나중에 잡음점이X의 다른 점에서epsilon과minpts로 설정된 제약 조건을 충족하면, 해당 잡음점을 군집에 재할당할 수 있습니다. 이렇게 점을 재할당하는 과정은 군집의 경계점에서 발생합니다.그렇지 않으면, 현재 점을 군집 C에 속하는 핵심점으로 레이블 지정합니다.
각 이웃(새로운 현재 점)에 대해 반복 처리하고, 현재 군집 C에 속한다고 레이블 지정할 수 있는 새로운 이웃이 더 이상 발견되지 않을 때까지 2단계를 반복합니다.
X에서 레이블 지정되어 있지 않는 다음 점을 현재 점으로 선택하고 군집 개수를 1만큼 늘립니다.X의 모든 점이 레이블 지정될 때까지 2~4단계를 반복합니다.
두 군집이 서로 다른 밀도를 가지면서 가까이 있는 경우, 즉 두 경계점(각 군집에서 하나씩) 사이의 거리가
epsilon보다 작으면dbscan은 두 군집을 하나로 병합할 수 있습니다.모든 유효한 군집이 언제나 최소
minpts개의 관측값을 포함하는 것은 아닙니다. 예를 들어,dbscan은 가까이 있는 두 군집에 속한 경계점을 식별할 수 있습니다. 이런 상황에서 알고리즘은 첫 번째로 발견된 군집에 경계점을 할당합니다. 결과적으로 두 번째 군집은 여전히 유효한 군집이지만,minpts개보다 적은 관측값을 가질 수 있습니다.
참고 문헌
[1] Ester, M., H.-P. Kriegel, J. Sander, and X. Xiaowei. “A density-based algorithm for discovering clusters in large spatial databases with noise.” In Proceedings of the Second International Conference on Knowledge Discovery in Databases and Data Mining, 226-231. Portland, OR: AAAI Press, 1996.
확장 기능
버전 내역
R2019a에 개발됨