회귀 학습기의 모델 성능 시각화 및 평가하기
회귀 학습기 앱에서 회귀 모델을 훈련시킨 후 모델 메트릭을 기반으로 모델을 비교하고, 응답 플롯에 결과를 시각화하거나 실제 응답과 예측된 응답을 비교해 플로팅하여 결과를 시각화하고, 잔차 플롯을 사용하여 모델을 평가할 수 있습니다.
k겹 교차 검증을 사용하는 경우 앱은 k 검증 겹의 결합된 관측값 세트를 사용하여 모델 메트릭(예: RMS 오차 또는 RMSE)을 계산합니다. 앱은 검증 겹의 관측값에 대한 예측을 수행하고, 해당 예측값을 플롯에 표시합니다. 앱은 또한 검증 겹의 관측값을 사용하여 잔차를 계산합니다.
데이터를 앱으로 가져오면 앱은 기본적으로 교차 검증을 자동으로 사용합니다. 다른 검증 방식을 선택하려면 Select Validation Scheme in Classification Learner or Regression Learner 항목을 참조하십시오.
홀드아웃 검증을 사용하는 경우, 앱은 검증 세트의 관측값을 사용하여 예측을 수행하고 모델 메트릭을 계산합니다. 앱은 해당 예측을 플롯에 사용하고 예측을 기반으로 잔차도 계산합니다.
재대입 검증을 사용하는 경우, 앱은 전체 모델을 훈련하는 데 사용되는 동일한 훈련 데이터 세트를 사용하여 예측을 수행하고 모델 메트릭을 계산합니다.
모델 창에서 성능 검사하기
회귀 학습기에서 모델을 훈련시킨 후 모델 창에서 전반적인 점수가 가장 우수한 모델을 확인합니다. 가장 높은 RMSE(검증)가 상자에 강조 표시됩니다. 이 점수는 검증 세트의 RMSE(RMS 오차)입니다. 점수는 훈련된 모델의 성능을 새로운 데이터에 대해 추정합니다. 점수를 참고하면 가장 적합한 모델을 선택하는 데 도움이 됩니다.

전반적인 점수가 가장 높은 모델이 목표에 가장 적합한 모델이 아닐 수도 있습니다. 경우에 따라 전반적인 점수가 약간 낮은 모델이 목표에 가장 적합한 모델일 수 있습니다. 과적합을 방지하고, 데이터 수집이 어렵거나 비용이 많이 드는 일부 예측 변수를 제외하고 싶을 수도 있습니다.
요약 탭과 모델 창에서 모델 메트릭 보기
모델 요약 탭과 모델 창에서 모델 메트릭을 보고, 이러한 메트릭을 사용하여 모델을 평가하고 비교할 수 있습니다. 또는 결과 비교 플롯과 결과값 테이블 탭을 사용하여 모델을 비교할 수 있습니다. 자세한 내용은 결과 비교 플롯에서 모델 정보와 결과 보기 항목과 테이블 뷰에서 모델 정보와 결과 비교하기 항목을 참조하십시오.
훈련 결과 메트릭은 검증 세트에서 계산됩니다. 테스트 결과 메트릭은 테스트 세트에서 계산됩니다(표시되는 경우). 자세한 내용은 Test Trained Models in Classification Learner or Regression Learner 항목을 참조하십시오.
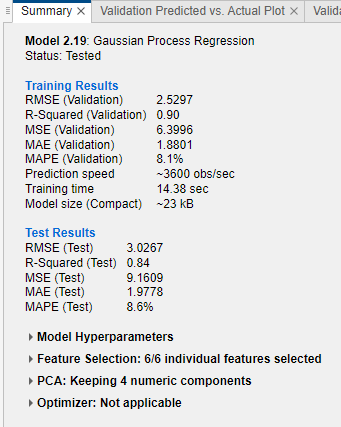
모델 메트릭
| 통계량 | 설명 | 팁 |
|---|---|---|
| RMSE | RMS 오차. RMSE는 항상 양수이며 RMSE의 단위는 응답 변수의 단위와 일치합니다. | 더 작은 RMSE 값을 찾으십시오. |
| 결정계수(R2) | 결정계수. 앱은 일반(수정되지 않은) R2 값을 계산합니다. R2은 항상 1보다 작으며 보통 0보다 큽니다. 응답 변수가 상수이면서 훈련 응답 변수의 평균값인 모델을 훈련된 모델과 비교합니다. 모델이 이 상수 모델보다 성능이 떨어지면 R2은 음수입니다. R2 통계량은 대부분의 비선형 회귀 모델에 유용한 메트릭이 아닙니다. 자세한 내용은 Rsquared를 참조하십시오. | 1에 가까운 R2을 찾으십시오. |
| MSE | 평균제곱오차. MSE는 RMSE의 제곱입니다. | 더 작은 MSE 값을 찾으십시오. |
| MAE | 평균절대오차. MAE는 항상 양수이며 RMSE와 유사하지만 이상값에 덜 민감합니다. | 더 작은 MAE 값을 찾으십시오. |
| MAPE | 평균절대백분율오차. MAPE는 항상 음수가 아니며 예측 오차가 응답 변수와 어떻게 비교되는지를 나타냅니다. 자세한 내용은 평균절대백분율오차 항목을 참조하십시오. | 더 작은 MAPE 값을 찾으십시오. |
| 예측 속도 | 검증 데이터 세트에 대한 예측 시간을 기반으로 기대되는 새 데이터 예측 속도 | 앱 내부와 외부의 배경 프로세스가 이 추정값에 영향을 미칠 수 있으므로 더 잘 비교될 수 있도록 유사한 조건에서 모델을 훈련시키십시오. |
| 훈련 시간 | 모델을 훈련하는 데 소요된 시간 | 앱 내부와 외부의 배경 프로세스가 이 추정값에 영향을 미칠 수 있으므로 더 잘 비교될 수 있도록 유사한 조건에서 모델을 훈련시키십시오. |
| 모델 크기(간소) | 간소 모델로 내보낸 경우(즉, 훈련 데이터 없이 내보낸 경우) 머신러닝 모델 객체의 크기. 모델을 작업 공간으로 내보낼 때, 내보내는 구조체에 모델 객체와 추가 필드가 포함됩니다. 앱은 whos 함수가 반환하는 모델 객체의 크기(단위: 바이트)를 표시합니다. learnersize 함수는 whos를 호출하기 전에 모델 객체에서 gather를 호출하기 때문에 일부 모델 유형에 대해서는 다른 크기를 반환할 수도 있다는 점에 유의하십시오. | 타깃 애플리케이션의 메모리 요구 사항에 맞는 모델 크기 값을 찾으십시오. |
| 모델 크기(Coder) | MATLAB® Coder™에 의해 생성된 C/C++ 코드에서 모델의 대략적인 크기(단위: 바이트). 앱은 type="coder"로 지정된 learnersize 함수가 반환하는 크기(단위: 바이트)를 표시합니다. 코드 생성 시 지원되지 않는 모델 유형의 경우 코더 모델 크기는 NaN입니다. | 지원되는 모델 유형 목록은 Export Regression Model to MATLAB Coder to Generate C/C++ Code 항목을 참조하십시오. |
모델 창에서 다양한 모델 메트릭을 기반으로 모델을 정렬할 수 있습니다. 정렬을 위한 메트릭을 선택하려면 모델 창의 맨 위에 있는 정렬 기준 목록을 사용합니다. 일부 메트릭은 모델 창에서 모델 정렬을 위해 사용할 수 없습니다. 결과값 테이블에서 다른 메트릭을 기준으로 모델을 정렬할 수 있습니다(테이블 뷰에서 모델 정보와 결과 비교하기 항목 참조).
또한 모델 창에서 원하지 않는 모델을 목록에서 삭제할 수도 있습니다. 삭제할 모델을 선택하고 창의 오른쪽 위에 있는 선택한 모델을 삭제합니다 버튼을 클릭하거나 모델을 마우스 오른쪽 버튼으로 클릭하고 삭제를 선택합니다. 마지막 남은 모델은 모델 창에서 삭제할 수 없습니다.
테이블 뷰에서 모델 정보와 결과 비교하기
요약 탭이나 모델 창을 사용하여 모델 메트릭을 비교하는 대신 결과값 테이블을 사용할 수 있습니다. 학습 탭의 플롯 및 결과 섹션에서 결과값 테이블을 클릭합니다. 결과값 테이블에서 훈련 결과와 테스트 결과를 기준으로 모델을 정렬하는 것은 물론, 옵션(예: 모델 유형, 선택한 특징, PCA 등)을 기준으로 모델을 정렬할 수도 있습니다. 예를 들어, RMS 오차를 기준으로 모델을 정렬하려면 RMSE(검증) 열 헤더에서 정렬 화살표를 클릭합니다. 위쪽 화살표는 모델이 가장 낮은 RMSE에서 가장 높은 RMSE 순으로 정렬됨을 나타냅니다.
테이블 열 옵션을 더 보려면 테이블의 오른쪽 위에 있는 "표시할 열 선택" 버튼  을 클릭합니다. "표시할 열 선택" 대화 상자에서 결과값 테이블에 표시할 열의 체크박스를 선택합니다. 새로 선택한 열은 오른쪽의 테이블에 추가됩니다.
을 클릭합니다. "표시할 열 선택" 대화 상자에서 결과값 테이블에 표시할 열의 체크박스를 선택합니다. 새로 선택한 열은 오른쪽의 테이블에 추가됩니다.

결과값 테이블 내에서 테이블 열이 원하는 순서로 나타나도록 수동으로 끌어서 놓을 수 있습니다.
즐겨찾기 열을 사용하여 일부 모델을 즐겨찾기로 표시할 수 있습니다. 즐겨찾기로 선택된 모델은 결과값 테이블과 모델 창에서 일관되게 유지됩니다. 다른 열과 달리 즐겨찾기 열과 모델 번호 열은 테이블에서 제거할 수 없습니다.
테이블에서 행을 제거하려면 행 내의 항목을 마우스 오른쪽 버튼으로 클릭하고 행 숨기기(또는 행이 강조 표시된 경우 선택한 행 숨기기)를 클릭합니다. 연속 행을 제거하려면 첫 번째 행 내의 항목을 클릭하고 Shift 키를 누른 다음 제거하려는 마지막 행 내의 항목을 클릭합니다. 그런 다음 강조 표시된 항목 중 하나를 마우스 오른쪽 버튼으로 클릭하고 선택한 행 숨기기를 클릭합니다. 제거된 모든 행을 복원하려면 테이블의 아무 항목이나 마우스 오른쪽 버튼으로 클릭하고 모든 행 표시를 클릭합니다. 복원된 행은 테이블 맨 아래에 추가됩니다.
테이블의 정보를 내보내려면 테이블의 오른쪽 위에 있는 내보내기 버튼  중 하나를 사용합니다. 테이블을 작업 공간으로 내보낼지 파일로 내보낼지 선택합니다. 내보낸 테이블에는 표시된 행과 열만 포함됩니다.
중 하나를 사용합니다. 테이블을 작업 공간으로 내보낼지 파일로 내보낼지 선택합니다. 내보낸 테이블에는 표시된 행과 열만 포함됩니다.
결과 비교 플롯에서 모델 정보와 결과 보기
결과 비교 플롯에서 모델 정보와 결과를 볼 수 있습니다. 학습 탭 또는 테스트 탭의 플롯 및 결과 섹션에서 결과 비교를 클릭합니다. 또는 결과값 테이블 탭에서 결과 플로팅 버튼을 클릭합니다. 플롯은 모델에 대한 검증 RMSE를 가장 낮은 RMSE 값에서 가장 높은 RMSE 값 순서로 정렬한 막대 차트를 표시합니다. 데이터 정렬 아래에 있는 정렬 기준 목록을 사용하여 다른 훈련 결과와 테스트 결과를 기준으로 모델을 정렬할 수 있습니다. 동일한 유형의 모델을 그룹화하려면 모델 유형별로 그룹화를 선택합니다. 동일한 색을 모든 모델 유형에 할당하려면 모델 유형별로 채색을 선택 해제합니다.

선택 아래에 있는 체크박스를 사용하여 표시할 모델 유형을 선택합니다. 플롯에서 막대를 마우스 오른쪽 버튼으로 클릭하고 모델 숨기기를 선택하여 표시된 모델을 숨깁니다.
또한 필터링 및 그룹화 아래에 있는 필터 버튼을 클릭하여 표시되는 모델을 선택하고 필터링할 수 있습니다. 모델 필터링 및 선택 대화 상자에서 메트릭 선택을 클릭하고 이 대화 상자 상단의 모델 테이블에서 표시할 메트릭을 선택합니다. 이 테이블 내에서 테이블 열이 원하는 순서로 나타나도록 끌어서 놓을 수 있습니다. 테이블을 정렬하려면 테이블 헤더의 정렬 화살표를 클릭합니다. 메트릭 값을 기준으로 모델을 필터링하려면 먼저 필터링 기준 열에서 메트릭을 선택합니다. 그런 다음 모델 필터링 테이블에서 조건을 선택하고, 값 필드에 값을 입력하고, 필터 적용을 클릭합니다. 모델 테이블에서 선택 사항이 업데이트됩니다. 필터 추가 버튼을 클릭하여 추가 조건을 지정할 수 있습니다. 확인을 클릭하여 업데이트된 플롯을 표시합니다.

플로팅할 다른 메트릭을 데이터 플로팅 아래에 있는 X 목록과 Y 목록에서 선택합니다. X 또는 Y에 대해 Model Number를 선택하지 않으면 앱은 산점도 플롯을 표시합니다.

결과 비교 플롯을 Figure로 내보내려면 Export Plots in Regression Learner App 항목을 참조하십시오.
결과값 테이블을 작업 공간으로 내보내려면 플롯 내보내기를 클릭하고 플롯 데이터 내보내기를 선택합니다. 결과 메트릭 플롯 데이터 내보내기 대화 상자에서, 내보내는 변수의 이름을 편집하고(필요한 경우) 확인을 클릭합니다. 앱은 결과값 테이블을 포함하는 구조체형 배열을 생성합니다.
응답 플롯에서 데이터와 결과 탐색하기
예측된 응답과 레코드 번호를 비교하여 표시하는 응답 플롯을 사용해 회귀 모델 결과를 봅니다. 회귀 모델을 훈련시키고 나면 자동으로 해당 모델의 응답 플롯이 열립니다. "모두" 모델을 훈련시키는 경우 첫 번째 모델의 응답 플롯이 열립니다. 다른 모델의 응답 플롯을 보려면 모델 창에서 모델을 선택합니다. 학습 탭의 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 응답 변수를 클릭합니다. 홀드아웃 검증 또는 교차 검증을 사용하는 경우, 예측된 응답 변수 값은 홀드아웃(검증) 관측값에 대한 예측입니다. 즉, 소프트웨어는 해당 관측값을 제외하고 훈련된 모델을 사용하여 각 예측을 얻습니다.
결과를 살펴보려면 오른쪽 컨트롤을 사용합니다. 가능한 작업:
예측된 응답 및/또는 실제 응답을 플로팅합니다. 플롯의 체크박스를 사용하여 선택합니다.
오차 체크박스를 선택하여 예측된 응답과 실제 응답 사이에 세로선으로 그려진 예측 오차를 표시합니다.
X축에서 x축에 플로팅할 변수를 선택합니다. 레코드 번호 또는 예측 변수 중 하나를 선택할 수 있습니다.
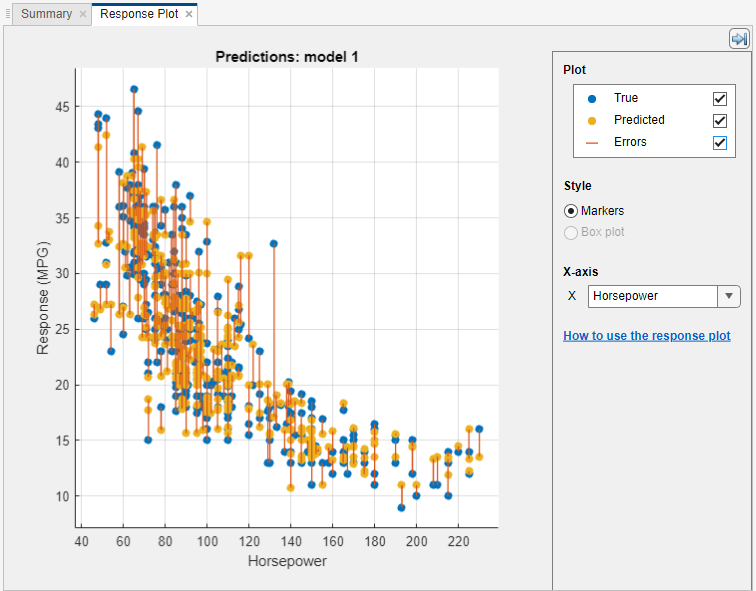
스타일에서 응답 변수를 마커로 플로팅하거나 상자 플롯으로 플로팅합니다. x축에 있는 변수에 고유한 값이 거의 없는 경우에만 상자 플롯을 선택할 수 있습니다.
상자 플롯에는 응답 변수의 일반적인 값과 가능한 이상값이 표시됩니다. 중앙에 있는 표시는 중앙값을 나타내고, 상자의 아래쪽 가장자리와 위쪽 가장자리는 각각 25번째 백분위수와 75번째 백분위수입니다. 수염(Whisker)이라고 부르는 세로선은 상자에서 시작하여 이상값으로 간주되지 않는 최대 또는 최소 데이터 점까지 확장됩니다. 이상값은
"o"기호를 사용하여 개별적으로 플로팅됩니다. 상자 플롯에 대한 자세한 내용은boxchart를 참조하십시오.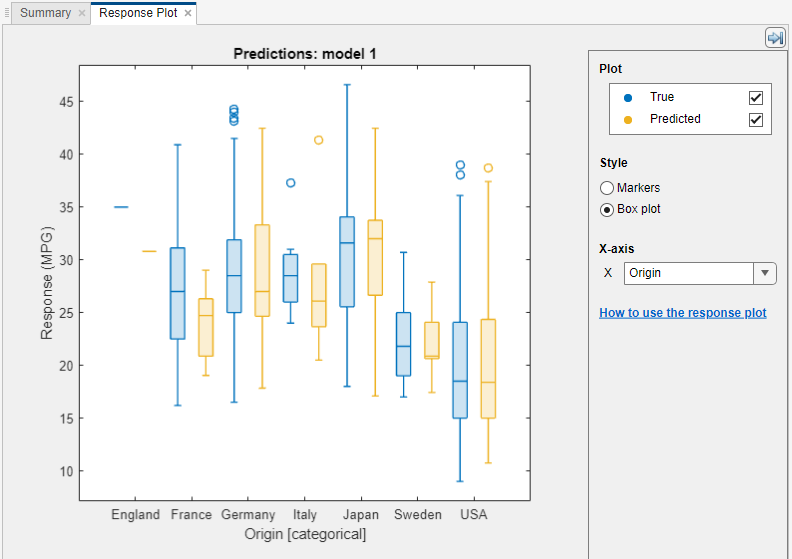
앱에서 만든 응답 플롯을 Figure로 내보내려면 Export Plots in Regression Learner App 항목을 참조하십시오.
예측된 응답 대 실제 응답 플로팅하기
예측 대 실제 플롯을 사용하여 모델 성능을 검사합니다. 회귀 모델이 서로 다른 응답 변수 값에 대해 얼마나 잘 예측하는지 파악하려면 이 플롯을 사용합니다. 모델을 훈련시킨 후 예측 대 실제 플롯을 보려면 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 예측 대 실제(검증)를 클릭합니다.
플롯을 열면 모델의 예측된 응답이 실제 응답에 대해 플로팅됩니다. 완벽한 회귀 모델의 예측된 응답은 실제 응답과 같으므로 모든 점이 대각선 위에 놓입니다. 선에서 임의의 점까지의 세로 거리는 해당 점에 대한 예측의 오차입니다. 양호한 모델은 오차가 작으며, 따라서 예측이 선 근처에 흩어져 있습니다.
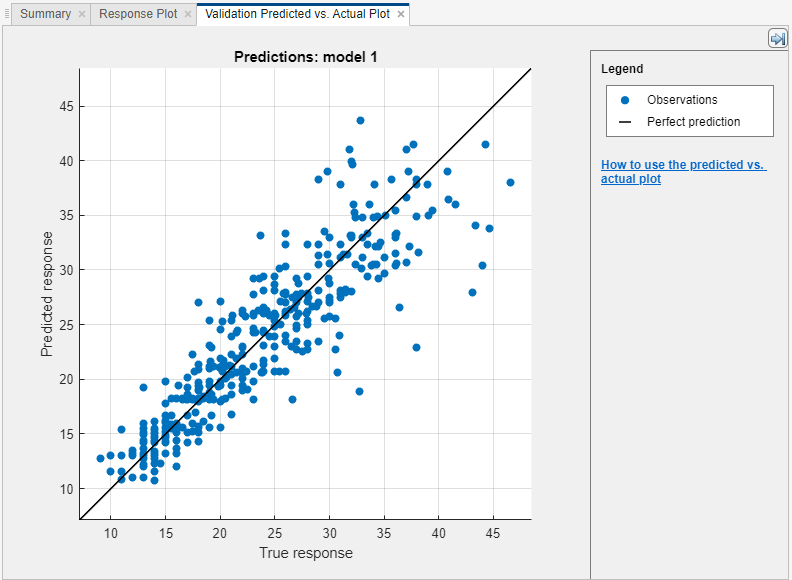
일반적으로 양호한 모델은 점이 대각선 주변에 대략 대칭적으로 흩어져 있습니다. 플롯에서 명확한 패턴을 볼 수 있으면 모델을 개선하는 것이 가능할 수 있습니다. 다른 모델 유형을 훈련시키거나, 모델을 복제하고 모델 요약 탭의 모델 하이퍼파라미터 옵션을 조정하여 현재 모델 유형을 보다 유연하게 만들어 보십시오. 모델을 개선할 수 없는 경우 데이터가 더 많이 필요하거나 중요한 예측 변수가 누락되었을 수 있습니다.
앱에서 만든 예측 대 실제 플롯을 Figure로 내보내려면 Export Plots in Regression Learner App 항목을 참조하십시오.
잔차 플롯을 사용하여 모델 평가하기
잔차 플롯을 사용하여 모델 성능을 검사합니다. 모델을 훈련시킨 후 잔차 플롯을 보려면 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 잔차(검증)를 클릭합니다. 잔차 플롯은 예측된 응답과 실제 응답 간의 차이를 표시합니다. X축에서 x축에 플로팅할 변수를 선택합니다. 실제 응답, 예측된 응답, 레코드 번호, 하나의 예측 변수 중에서 선택합니다.
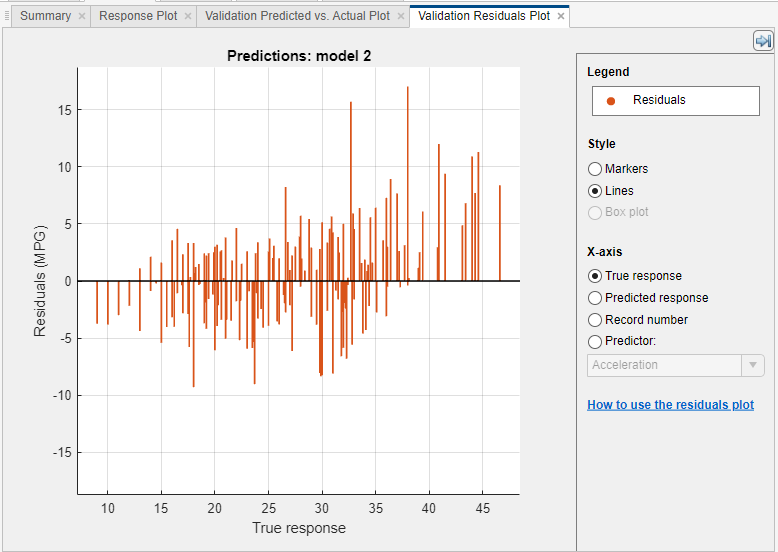
일반적으로 양호한 모델은 잔차가 0 주변에 대략 대칭적으로 흩어져 있습니다. 잔차에서 명확한 패턴을 볼 수 있으면 모델을 개선하는 것이 가능할 수 있습니다. 다음과 같은 패턴을 찾습니다.
잔차가 0 주변에 대칭적으로 분포하지 않습니다.
플롯에서 잔차의 크기가 왼쪽에서 오른쪽으로 크게 변합니다.
이상값, 즉 나머지 잔차보다 훨씬 큰 잔차가 발생합니다.
잔차에 명확한 비선형 패턴이 나타납니다.
다른 모델 유형을 훈련시키거나, 모델을 복제하고 모델 요약 탭의 모델 하이퍼파라미터 옵션을 조정하여 현재 모델 유형을 보다 유연하게 만들어 보십시오. 모델을 개선할 수 없는 경우 데이터가 더 많이 필요하거나 중요한 예측 변수가 누락되었을 수 있습니다.
앱에서 만든 잔차 플롯을 Figure로 내보내려면 Export Plots in Regression Learner App 항목을 참조하십시오.
레이아웃을 변경하여 모델 플롯 비교하기
학습 탭의 플롯 및 결과 섹션에서 플롯 옵션을 사용하여 회귀 학습기에서 훈련된 모델의 결과를 시각화합니다. 플롯의 레이아웃을 재배열하여 여러 모델 간에 결과를 비교할 수 있습니다. 레이아웃 버튼을 클릭하면 나타나는 옵션을 사용하거나 플롯을 끌어서 놓거나 모델 플롯 탭의 오른쪽에 있는 문서 동작 버튼  을 클릭하면 제공되는 옵션을 선택하십시오.
을 클릭하면 제공되는 옵션을 선택하십시오.
예를 들어 회귀 학습기에서 두 모델을 훈련시킨 후 각 모델에 대한 플롯을 표시하고, 다음 절차 중 하나를 사용하여 플롯을 비교할 수 있도록 플롯 레이아웃을 변경합니다.
플롯 및 결과 섹션에서 레이아웃을 클릭하고 모델 비교를 선택합니다.
두 번째 모델 탭 이름을 클릭한 다음, 두 번째 모델 탭을 오른쪽에 끌어서 놓습니다.
모델 플롯 탭의 오른쪽 끝에 있는 문서 동작 버튼
을 클릭합니다. 모두 타일 형식으로 배열옵션을 선택하고 1×2 레이아웃을 지정합니다.
참고로 플롯 오른쪽 위에 있는 "플롯 옵션을 숨깁니다" 버튼  을 클릭하여 플롯을 위한 더 많은 공간을 만들 수 있습니다.
을 클릭하여 플롯을 위한 더 많은 공간을 만들 수 있습니다.
테스트 데이터 세트를 사용하여 모델 성능 평가하기
회귀 학습기에서 모델을 훈련시킨 후 앱의 테스트 데이터 세트에서 모델 성능을 평가할 수 있습니다. 자세한 내용은 Test Trained Models in Classification Learner or Regression Learner 항목을 참조하십시오.