boxchart
상자 차트(상자 플롯)
구문
설명
벡터 및 행렬 데이터
boxchart(는 행렬 ydata)ydata의 각 열에 대한 상자 차트 또는 상자 플롯을 만듭니다. ydata가 벡터인 경우 boxchart는 상자 차트를 한 개 만듭니다.
각 상자 차트에는 중앙값, 하위 사분위수와 상위 사분위수, 이상값(사분위 범위를 사용하여 계산됨), 이상값이 아닌 최솟값과 최댓값에 대한 정보가 표시됩니다. 자세한 내용은 상자 차트(상자 플롯) 항목을 참조하십시오.
boxchart(는 xgroupdata,ydata)xgroupdata의 고유한 값에 따라 벡터 ydata의 데이터를 그룹화하고, 데이터의 각 그룹을 별개의 상자 차트로 플로팅합니다. xgroupdata는 x축을 따라 각 상자 차트의 위치를 결정합니다. ydata는 벡터여야 하고, xgroupdata는 ydata와 길이가 같아야 합니다.
boxchart(___,'GroupByColor',는 색을 사용하여 상자 차트들을 구분합니다. cgroupdata)xgroupdata(지정된 경우)와 cgroupdata의 고유한 값의 조합에 따라 벡터 ydata의 데이터가 그룹화되고, 데이터의 각 그룹은 별개의 상자 차트로 플로팅됩니다. 그런 다음 벡터 cgroupdata가 각 상자 차트의 색을 결정합니다. ydata는 벡터여야 하고, cgroupdata는 ydata와 길이가 같아야 합니다. 위에 열거된 구문에 나와 있는 입력 인수를 조합하여 'GroupByColor' 이름-값 쌍 인수를 지정합니다.
테이블 데이터
추가 옵션
boxchart(___,는 하나 이상의 이름-값 쌍의 인수를 사용하여 추가 차트 옵션을 지정합니다. 예를 들어, Name,Value)'Notch','on'을 지정하여 노치로 샘플 중앙값을 비교할 수 있습니다. 다른 모든 입력 인수 다음에 이름-값 쌍 인수를 지정합니다. 속성 목록은 BoxChart Properties 항목을 참조하십시오.
b = boxchart(___)BoxChart 객체를 반환합니다. cgroupdata를 지정하지 않으면 b는 한 개의 객체를 포함합니다. 이를 지정하면 b는 cgroupdata의 고유한 값 각각에 대응하는 객체들로 구성된 벡터를 포함합니다. 상자 차트를 생성한 후에 속성을 설정하려면 b를 사용하십시오. 속성 목록은 BoxChart Properties 항목을 참조하십시오.
예제
나이로 이루어진 벡터에서 상자 차트를 한 개 만듭니다. 상자 차트를 사용하여 나이 분포를 시각화합니다.
patients 데이터 세트를 불러옵니다. Age 변수에는 환자 100명의 나이가 들어 있습니다. 상자 차트를 만들어 나이 분포를 시각화합니다.
load patients boxchart(Age) ylabel('Age (years)')
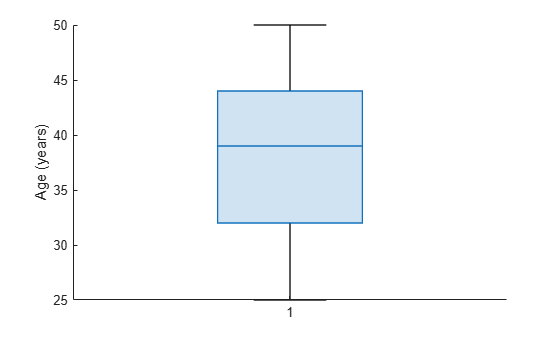
환자 나이의 중앙값인 39세가 상자 내에 선으로 표시됩니다. 하위 사분위수와 상위 사분위수인 32세와 44세가 상자의 하단 가장자리와 상단 가장자리로 각각 표시됩니다. 상자의 위와 아래로 연장되는 선, 즉 수염(whisker)에는 나이가 가장 어린 환자와 나이가 가장 많은 환자에 해당하는 끝점이 있습니다. 나이가 가장 어린 환자는 25세이고, 나이가 가장 많은 환자는 50세입니다. 데이터 세트에 이상값(작은 원으로 표현됨)이 포함되어 있지 않습니다.
데이터팁을 사용하여 데이터 통계량의 요약을 가져올 수 있습니다. 상자 차트 위에 커서를 올려놓으면 데이터팁이 표시됩니다.
상자 차트를 사용하여 마방진의 열과 행을 따라 값의 분포를 비교합니다.
행 10개와 열 10개를 갖는 마방진을 생성합니다.
Y = magic(10)
Y = 10×10
92 99 1 8 15 67 74 51 58 40
98 80 7 14 16 73 55 57 64 41
4 81 88 20 22 54 56 63 70 47
85 87 19 21 3 60 62 69 71 28
86 93 25 2 9 61 68 75 52 34
17 24 76 83 90 42 49 26 33 65
23 5 82 89 91 48 30 32 39 66
79 6 13 95 97 29 31 38 45 72
10 12 94 96 78 35 37 44 46 53
11 18 100 77 84 36 43 50 27 59
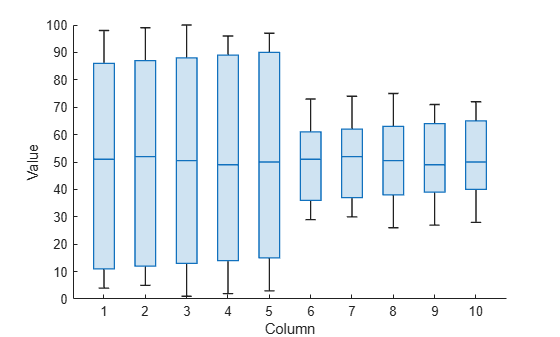
마방진의 각 열에 대한 상자 차트를 만듭니다. 각 열은 유사한 중앙값(약 50)을 갖습니다. 하지만 Y의 처음 5개 열은 Y의 마지막 5개 열보다 사분위 범위가 큽니다. 사분위 범위는 상위 사분위수(상자의 상단 가장자리)와 하위 사분위수(상자의 하단 가장자리) 사이의 거리입니다.
boxchart(Y) xlabel('Column') ylabel('Value')
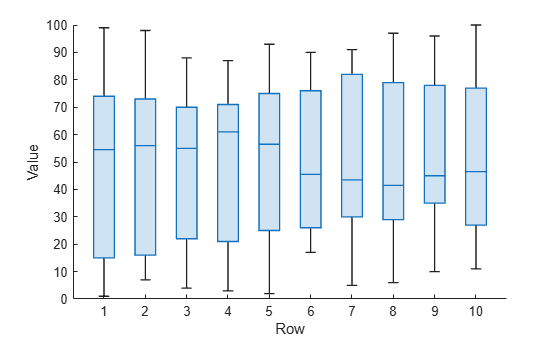
마방진의 각 행에 대한 상자 차트를 만듭니다. 각 행은 유사한 사분위 범위를 갖지만, 행의 중앙값은 서로 다릅니다.
boxchart(Y') xlabel('Row') ylabel('Value')
R2025a 이후
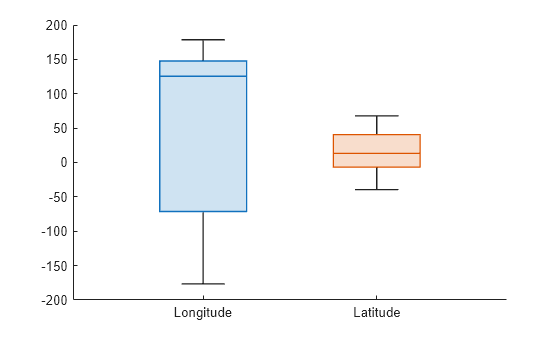
tsunami 데이터 세트를 테이블로 불러옵니다. 변수 Longitude와 Latitude에 대한 상자 차트를 만들고 변수 이름을 사용하여 그룹에 레이블을 지정합니다.
tbl = readtable("tsunamis.xlsx"); boxchart(tbl,["Longitude","Latitude"]) xticklabels(["Longitude","Latitude"])
R2025a 이후
지진이 발생한 달에 따라 지진의 크기를 플로팅합니다. 지진 크기로 구성된 벡터와, 각 지진이 발생한 달을 나타내는 그룹화 변수를 사용합니다. 각 데이터 그룹에 대한 상자 차트를 만들고 그 차트를 x축상의 지정된 위치에 놓습니다.
쓰나미 데이터 세트를 작업 공간에 테이블로 읽어옵니다. 데이터 세트에는 지진에 대한 정보와 쓰나미의 기타 원인이 들어 있습니다. 처음 8개 행을 표시합니다. 월, 원인 및 지진 크기 열로 구성된 테이블이 표시됩니다.
tsunamis = readtable('tsunamis.xlsx'); tsunamis(1:8,["Month","Cause","EarthquakeMagnitude"])
ans=8×3 table
Month Cause EarthquakeMagnitude
_____ __________________ ___________________
10 {'Earthquake' } 7.6
8 {'Earthquake' } 6.9
12 {'Volcano' } NaN
3 {'Earthquake' } 8.1
3 {'Earthquake' } 4.5
5 {'Meteorological'} NaN
11 {'Earthquake' } 9
3 {'Earthquake' } 5.8
지진으로 발생한 쓰나미에 대한 데이터를 포함하는 테이블 earthquakes를 만듭니다.
unique(tsunamis.Cause)
ans = 8×1 cell
{0×0 char }
{'Earthquake' }
{'Earthquake and Landslide'}
{'Landslide' }
{'Meteorological' }
{'Unknown Cause' }
{'Volcano' }
{'Volcano and Landslide' }
idx = contains(tsunamis.Cause,'Earthquake');
earthquakes = tsunamis(idx,:);해당 쓰나미가 발생한 달을 기준으로 지진 크기를 그룹화합니다. 각 달에 대해 별도의 상자 차트를 표시합니다. 예를 들어 boxchart는 4번째, 5번째, 8번째 지진 크기와 기타 정보를 사용하여 세 번째 달에 해당하는 세 번째 상자 차트를 만듭니다.
boxchart(earthquakes,"Month","EarthquakeMagnitude") xlabel('Month') ylabel('Earthquake Magnitude')
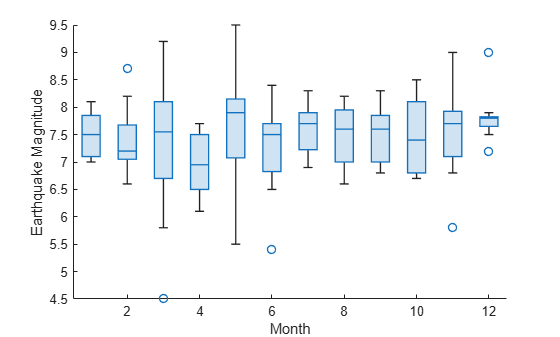
참고로, 월 값이 숫자형이므로 x축 눈금자도 숫자형입니다.
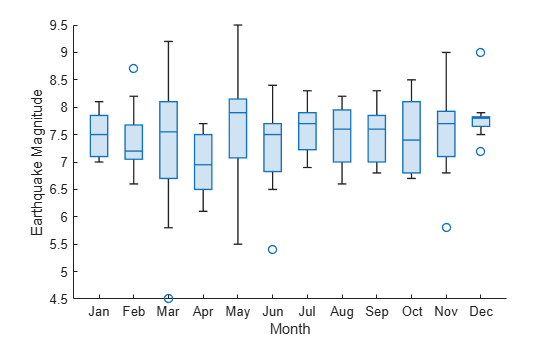
보다 설명적인 월 이름을 위해 earthquakes.Month 변수를 categorical형 변수로 변환합니다.
monthOrder = ["Jan","Feb","Mar","Apr","May","Jun","Jul", ... "Aug","Sep","Oct","Nov","Dec"]; earthquakes.Months = categorical(earthquakes.Month,1:12,monthOrder);
이전과 동일한 상자 차트를 만듭니다. 이제 x축 눈금자는 categorical형이며, Months의 범주 순서에 따라 상자 차트 순서가 정해집니다.
boxchart(earthquakes,"Months","EarthquakeMagnitude") xlabel('Month') ylabel('Earthquake Magnitude')
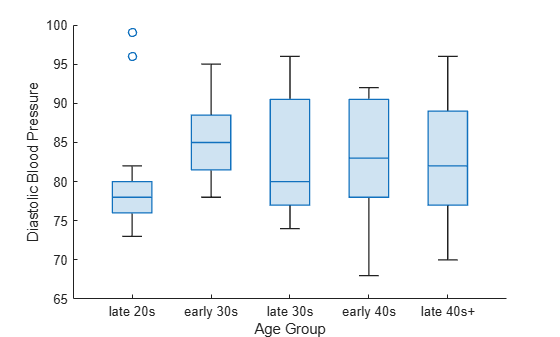
나이를 기준으로 환자를 그룹화하고, 각 연령 그룹에 대해 확장기 혈압 값의 상자 차트를 만듭니다.
patients 데이터 세트를 불러옵니다. Age 변수와 Diastolic 변수에는 환자 100명의 나이와 확장기 혈압 수준이 들어 있습니다.
load patients환자를 5개의 연령 Bin으로 그룹화합니다. 최소 연령과 최고 연령을 찾은 다음, 그 사이의 범위를 5개 연령 Bin으로 나눕니다. discretize 함수를 사용하여 Age 변수의 값을 비닝합니다. bins의 Bin 이름을 사용합니다. 결과로 생성되는 groupAge 변수는 categorical형 변수입니다.
min(Age)
ans = 25
max(Age)
ans = 50
binEdges = 25:5:50;
bins = {'late 20s','early 30s','late 30s','early 40s','late 40s+'};
groupAge = discretize(Age,binEdges,'categorical',bins);각 연령 그룹에 대한 상자 차트를 만듭니다. 각 상자 차트에 해당 그룹 환자의 확장기 혈압 값이 표시됩니다.
boxchart(groupAge,Diastolic) xlabel('Age Group') ylabel('Diastolic Blood Pressure')
두 그룹화 변수를 사용하여 데이터를 그룹화한 후 결과로 생성된 상자 차트를 배치하고 색을 지정합니다.
2015년 1월부터 2016년 7월까지의 평균 일일 온도가 포함된 표본 파일 TemperatureData.csv를 불러옵니다. 파일을 테이블로 읽어 들입니다.
tbl = readtable('TemperatureData.csv');tbl.Month 변수를 categorical형 변수로 변환합니다. 범주의 순서를 지정합니다.
monthOrder = {'January','February','March','April','May','June','July', ...
'August','September','October','November','December'};
tbl.Month = categorical(tbl.Month,monthOrder);각 해의 월별 온도 분포를 나타내는 상자 차트를 만듭니다. tbl.Month를 위치 그룹화 변수로 지정합니다. 'GroupByColor' 이름-값 쌍의 인수를 사용하여 tbl.Year를 색 그룹화 변수로 지정합니다. tbl에 2016년의 일부 월에 대한 데이터가 포함되어 있지 않습니다.
boxchart(tbl.Month,tbl.TemperatureF,'GroupByColor',tbl.Year) ylabel('Temperature (F)') legend
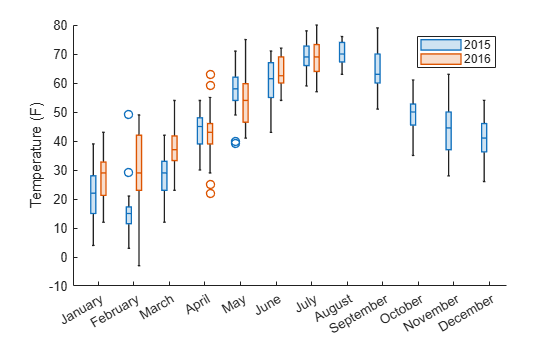
이 Figure에서 여러 해의 특정 월에 대한 온도 분포를 쉽게 비교할 수 있습니다. 예를 들어, 2월의 온도는 2015년보다 2016년에 훨씬 더 변화가 컸다는 것을 알 수 있습니다.
상자 차트를 만들고 hold on을 사용하여 상자 차트에 평균값을 플로팅합니다.
patients 데이터 세트를 불러옵니다. 범주 Poor, Fair, Good, Excellent가 자연적인 순서를 가지므로, SelfAssessedHealthStatus를 순서형 categorical형 변수로 변환합니다.
load patients healthOrder = {'Poor','Fair','Good','Excellent'}; SelfAssessedHealthStatus = categorical(SelfAssessedHealthStatus, ... healthOrder,'Ordinal',true);
자가 검진한 건강 상태에 따라 환자를 그룹화하고, 그룹마다 환자의 평균 몸무게를 구합니다.
meanWeight = groupsummary(Weight,SelfAssessedHealthStatus,'mean');상자 차트를 사용하여 각 환자 그룹의 몸무게를 비교합니다. 상자 차트에 평균 몸무게를 플로팅합니다.
boxchart(SelfAssessedHealthStatus,Weight) hold on plot(meanWeight,'-o') hold off legend(["Weight Data","Weight Mean"])
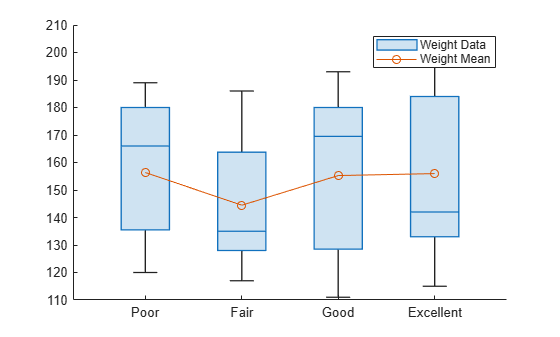
노치를 사용하여 중앙값이 서로 현저히 다른지 확인할 수 있습니다.
patients 데이터 세트를 불러옵니다. 위치에 따라 환자를 나눕니다. 각 환자 그룹에 대해 몸무게로 구성된 상자 차트를 만듭니다. 각 상자에 점점 가늘어지는 형태의 음영 처리된 영역(노치라고 함)이 포함되도록 'Notch','on'을 지정합니다. 노치가 겹치지 않는 상자 차트는 5%의 유의수준에서 서로 다른 중앙값을 갖습니다.
load patients boxchart(categorical(Location),Weight,'Notch','on') ylabel('Weight (lbs)')
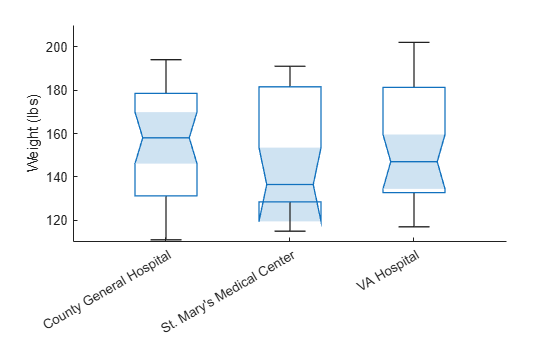
이 예제에서는 노치 3개가 겹쳐, 3개의 몸무게 중앙값이 크게 다르지 않음을 알 수 있습니다.
tiledlayout 함수와 nexttile 함수를 사용하여 한 쌍의 상자 차트를 나란히 표시합니다.
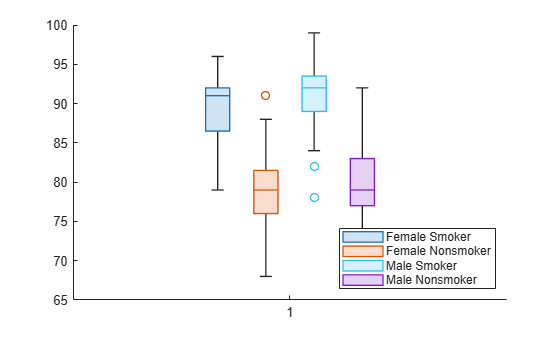
patients 데이터 세트를 불러옵니다. Smoker를 1과 0이 아니라 설명적 범주 이름 Smoker와 Nonsmoker를 갖는 categorical형 변수로 변환합니다.
load patients Smoker = categorical(Smoker,logical([1 0]),{'Smoker','Nonsmoker'});
tiledlayout 함수를 사용하여 1×2 타일 형식 차트 레이아웃을 만듭니다. nexttile 함수를 호출하여 레이아웃 내에 첫 번째 좌표축 세트 ax1을 만듭니다. 첫 번째 좌표축 세트에 수축기 혈압 값에 대한 상자 차트 두 개가 표시됩니다. 하나는 흡연자에 대한 것이고 다른 하나는 비흡연자에 대한 것입니다. nexttile 함수를 호출하여 타일 형식 차트 레이아웃 내에 두 번째 좌표축 세트 ax2를 만듭니다. 두 번째 좌표축 세트에서 확장기 혈압에 대해 동일한 작업을 수행합니다.
tiledlayout(1,2) % Left axes ax1 = nexttile; boxchart(ax1,Systolic,'GroupByColor',Smoker) ylabel(ax1,'Systolic Blood Pressure') legend % Right axes ax2 = nexttile; boxchart(ax2,Diastolic,'GroupByColor',Smoker) ylabel(ax2,'Diastolic Blood Pressure') legend
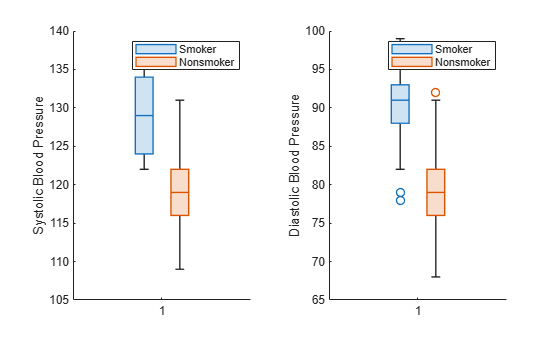
색으로 구분되는 상자 차트 세트(BoxChart 객체로 구성된 벡터로 반환됨)를 만듭니다. 해당 벡터를 사용하여 특정 상자 차트의 색을 변경합니다.
patients 데이터 세트를 불러옵니다. Gender와 Smoker를 categorical형 변수로 변환합니다. 1과 0이 아닌 설명적 범주 이름 Smoker와 Nonsmoker를 지정합니다.
load patients Gender = categorical(Gender); Smoker = categorical(Smoker,logical([1 0]),{'Smoker','Nonsmoker'});
Gender 및 Smoker 변수를 하나의 그룹화 변수 cgroupdata로 결합합니다. 성별과 흡연 상태로 구성된 각 쌍에 대해 확장기 혈압 수준의 분포를 표시하는 상자 차트를 만듭니다. b는 각 데이터 그룹에 하나씩 대응하는 BoxChart 객체들로 구성된 벡터입니다.
cgroupdata = Gender.*Smoker;
b = boxchart(Diastolic,'GroupByColor',cgroupdata)b = 4×1 BoxChart array: BoxChart BoxChart BoxChart BoxChart
legend('Location','southeast')
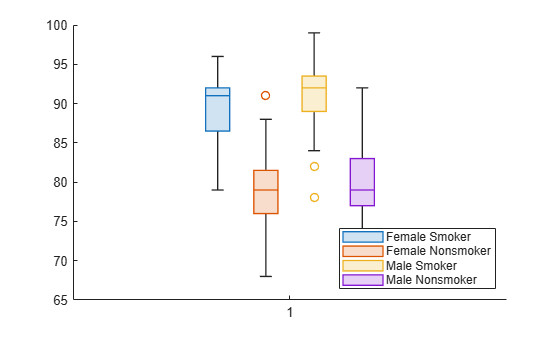
SeriesIndex 속성을 사용하여 세 번째 상자 차트의 색을 업데이트합니다. SeriesIndex 속성을 업데이트하면 상자 면 색과 이상값 마커 색이 모두 변경됩니다.
b(3).SeriesIndex = 6;
여러 이상값이 포함된 정전 데이터에서 상자 데이터를 만들고, BoxChart 객체의 속성을 변경하여 정전 데이터를 시각적으로 더 구별하기 쉽게 만듭니다. 이상값 항목에 대한 인덱스를 찾습니다.
정전 데이터를 작업 공간에 테이블로 읽어옵니다. 테이블의 처음 몇 개 행을 표시합니다.
outages = readtable('outages.csv');
head(outages) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-01-23 00:49 530.14 2.1204e+05 NaT {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'West' } 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 {'equipment fault'}
{'West' } 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 {'equipment fault'}
각 정전의 영향을 받은 고객 수를 나타내는 outages.Customers 값에서 BoxChart 객체 b를 만듭니다. boxchart는 NaN 값이 있는 항목은 무시합니다.
b = boxchart(outages.Customers);
ylabel('Number of Customers')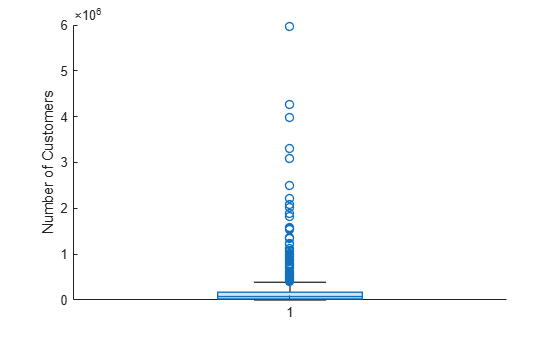
플롯에 여러 개의 이상값이 포함되어 있습니다. 이상값을 더 잘 확인할 수 있도록 이상값을 지터링하고 이상값 마커 스타일을 변경합니다. BoxChart 객체의 JitterOutliers 속성을 'on'으로 설정하면, 마커가 완전히 중첩되지 않도록 이상값 마커의 위치가 가로로 임의로 변경됩니다. 이상값 자체와 이상값의 세로 위치는 변경되지 않습니다.
b.JitterOutliers = 'on'; b.MarkerStyle = '.';
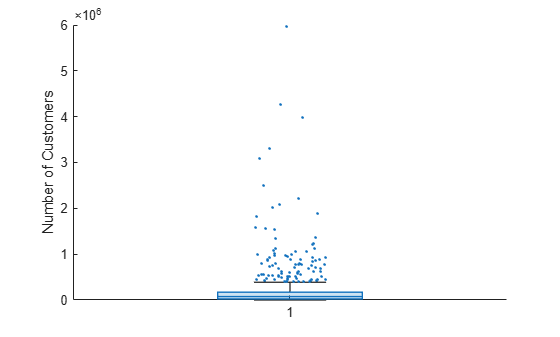
이제 이상값의 분포를 훨씬 더 쉽게 확인할 수 있습니다.
이상값 인덱스를 찾기 위해 isoutlier 함수를 사용합니다. boxchart 이상값 정의에 일치시키기 위해 이상값 계산을 위한 'quartiles' 방법을 지정합니다. 인덱스를 사용하여 outages 데이터의 서브셋이 포함된 outliers 테이블을 만듭니다. isoutlier를 통해 96개의 이상값이 식별되었습니다.
idx = isoutlier(outages.Customers,'quartiles');
outliers = outages(idx,:);
size(outliers,1)ans = 96
모든 이상값으로 인해 상자 차트의 분위수를 확인하기가 어렵습니다. 분위수를 조사하기 위해 y축 제한을 변경합니다.
ylim([0 4e5])
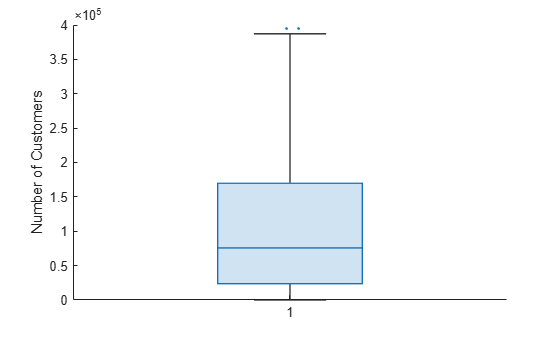
입력 인수
이름-값 인수
선택적 인수 쌍을 Name1=Value1,...,NameN=ValueN으로 지정합니다. 여기서 Name은 인수 이름이고 Value는 대응값입니다. 이름-값 인수는 다른 인수 뒤에 와야 하지만, 인수 쌍의 순서는 상관없습니다.
예: boxchart([rand(10,4); 4*rand(1,4)],'BoxFaceColor',[0 0.5 0],'MarkerColor',[0 0.5 0])은 녹색 상자와 녹색 이상값을 갖는 상자 차트를 만듭니다(해당하는 경우).
참고
여기에 나와 있는 BoxChart 속성은 일부에 불과합니다. 전체 목록을 보려면 BoxChart Properties 항목을 참조하십시오.
몇몇의 흔한 색은 이름으로 지정할 수도 있습니다. 다음 표에는 명명된 색 옵션과 그에 해당하는 RGB 3색 및 16진수 색 코드가 나와 있습니다.
| 색 이름 | 짧은 이름 | RGB 3색 | 16진수 색 코드 | 모양 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
"none" | 해당 없음 | 해당 없음 | 해당 없음 | 색 없음 |








다음 표에는 라이트 테마와 다크 테마에서 플롯의 디폴트 색 팔레트가 나열되어 있습니다.
| 팔레트 | 팔레트 색 |
|---|---|
R2025a 이전: 대부분의 플롯은 기본적으로 이 색을 사용합니다. |
|
|
|


orderedcolors 함수와 rgb2hex 함수를 사용하여 이러한 팔레트의 RGB 3색과 16진수 색 코드를 가져올 수 있습니다. 예를 들어, "gem" 팔레트의 RGB 3색을 가져와서 16진수 색 코드로 변환해 보겠습니다.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);R2023b 이전: RGB = get(groot,"FactoryAxesColorOrder")를 사용하여 RGB 3색을 가져옵니다.
R2024a 이전: H = compose("#%02X%02X%02X",round(RGB*255))를 사용하여 16진수 색 코드를 가져옵니다.
예: b = boxchart(rand(10,1),'BoxFaceColor','red')
예: b.BoxFaceColor = [0 0.5 0.5];
예: b.BoxFaceColor = '#EDB120';
R2025a 이후
색 그룹 레이아웃으로, "grouped" 또는 "overlaid"로 지정됩니다. 기본적으로 각 색 그룹의 상자 차트는 나란히 플로팅됩니다. 각 상자 차트의 너비는 cgroupdata에 지정된 색의 개수(즉, 색 데이터의 고유한 값의 개수)에 반비례합니다.
ColorGroupLayout="overlaid"를 지정하면 다음이 적용됩니다.
각 색 그룹의 상자 차트가 서로 겹쳐서 플로팅됩니다.
ColorGroupWidth의 값은 무시됩니다.BoxWidth를 지정하여 겹쳐진 색 그룹 간의 간격을 조정할 수 있습니다.
데이터형: string | char
이상값 스타일로, 다음 표에 나열된 옵션 중 하나로 지정됩니다.
| 마커 | 설명 | 결과로 생성되는 마커 |
|---|---|---|
"o" | 원 |
|
"+" | 플러스 기호 |
|
"*" | 별표 |
|
"." | 점 |
|
"x" | 십자 |
|
"_" | 가로선 |
|
"|" | 세로선 |
|
"square" | 정사각형 |
|
"diamond" | 다이아몬드 |
|
"^" | 위쪽 방향 삼각형 |
|
"v" | 아래쪽 방향 삼각형 |
|
">" | 오른쪽 방향 삼각형 |
|
"<" | 왼쪽 방향 삼각형 |
|
"pentagram" | 펜타그램 |
|
"hexagram" | 헥사그램 |
|
"none" | 마커 없음 | 해당 없음 |















예: b = boxchart([rand(10,1);2],'MarkerStyle','x')
예: b.MarkerStyle = 'x';
출력 인수
세부 정보
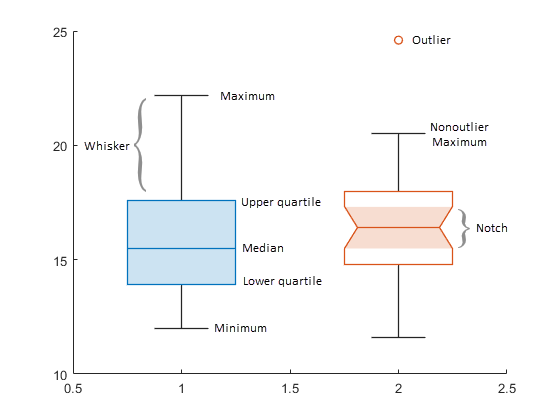
상자 차트, 즉 상자 플롯은 데이터 샘플에 대한 요약 통계량을 시각적으로 표현합니다. 숫자형 데이터가 주어진 경우 대응하는 상자 차트에는 중앙값, 하위 사분위수와 상위 사분위수, 이상값(사분위 범위를 사용하여 계산됨), 이상값이 아닌 최솟값과 최댓값에 대한 정보가 표시됩니다.
각 상자 내의 선은 샘플 중앙값입니다.
median함수를 사용하여 중앙값을 계산할 수 있습니다.각 상자의 상단 가장자리와 하단 가장자리는 각각 상위 사분위수와 하위 사분위수입니다. 상단 가장자리와 하단 가장자리의 거리는 사분위 범위(IQR)입니다.
사분위를 계산하는 방법에 대한 자세한 내용은
quantile항목을 참조하십시오. 여기서 상위 사분위수는 0.75 사분위수에 해당하고 하위 사분위수는 0.25 사분위수에 해당합니다.이상값은 상자의 상단 또는 하단으로부터 1.5 · IQR을 초과해 떨어져 있는 값입니다. 기본적으로
boxchart는'o'기호를 사용하여 각 이상값을 표시합니다. 이상값 계산은isoutlier함수에'quartiles'메서드를 사용한 계산과 유사합니다.수염은 각 상자의 위와 아래로 확장된 선입니다. 한 수염은 상위 사분위수를 이상값이 아닌 최댓값(이상값이 아닌 최대 데이터 값)에 연결하고, 다른 수염은 하위 사분위수를 이상값이 아닌 최솟값(이상값이 아닌 최소 데이터 값)에 연결합니다.
노치를 사용하면 여러 상자 차트 간의 샘플 중앙값을 쉽게 비교할 수 있습니다.
'Notch','on'을 지정하면boxchart함수는 각 중앙값 주위에 점점 가늘어지는 형태의 음영 처리된 영역을 만듭니다. 노치가 겹치지 않는 상자 차트는 5%의 유의수준에서 서로 다른 중앙값을 갖습니다. 유의수준은 정규분포라는 가정을 기반으로 하지만, 중앙값 비교는 그 밖의 다른 분포에서 더 견고합니다.노치 영역의 상단 가장자리와 하단 가장자리는 각각 과 에 해당합니다. 여기서 m은 중앙값이고, IQR은 사분위 범위이며, n은
NaN값을 제외한 데이터 점의 개수입니다.
팁
데이터팁을 사용하여
BoxChart객체의 데이터를 살펴볼 수 있습니다. 일부 옵션은 라이브 편집기에서 사용할 수 없습니다.2가지 유형의 데이터팁을
BoxChart객체에 추가할 수 있습니다. 하나는 각 상자 차트에 대한 데이터팁이고 다른 하나는 각 이상값에 대한 데이터팁입니다. 일반적인 데이터팁은 상자 차트를 클릭하는 위치에 관계없이 이상값이 아닌 최댓값에 표시됩니다.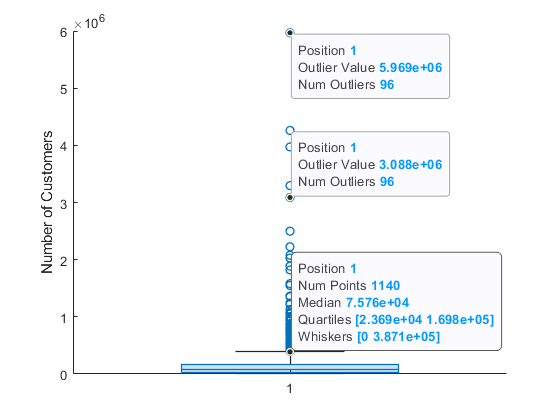
참고
표시되는
Num Points값은 대응하는ydata의NaN값을 포함하지만,boxchart는 상자 차트 통계량을 계산하기 전에NaN값을 무시합니다.datatip함수를 사용하여 데이터팁을BoxChart객체에 더 추가할 수 있지만, 데이터팁에 대한 인덱싱이 다른 차트와 다릅니다.boxchart는 먼저 인덱스를 상자 차트에 할당한 다음, 인덱스를 이상값에 할당합니다. 예를 들어BoxChart객체b가 상자 차트 두 개와 이상값 한 개를 표시하는 경우datatip(b,'DataIndex',3)은 이상값 점에 데이터팁을 만듭니다.