scatteredInterpolant
2차원 또는 3차원 산점 데이터 보간
설명
scatteredInterpolant를 사용하여 2차원 또는 3차원 산점 데이터의 데이터 세트에 보간을 수행합니다. scatteredInterpolant는 지정된 데이터 세트에 대해 보간 함수 F를 반환합니다. 2차원에서는 (xq,yq)와 같은 일련의 쿼리 점에서 F를 실행하여 보간된 값 vq = F(xq,yq)를 생성할 수 있습니다.
griddedInterpolant를 사용하여, 그리딩된 데이터에 대해 보간을 수행합니다.
생성
구문
설명
F = scatteredInterpolant
F = scatteredInterpolant(___,Method)'nearest', 'linear' 또는 'natural'을 지정합니다.
F = scatteredInterpolant(___,Method,ExtrapolationMethod)Method와 ExtrapolationMethod를 전달합니다.
입력 인수
속성
사용
설명
scatteredInterpolant를 사용하여 보간 함수 F를 생성합니다. 그런 다음, 다음 구문 중 하나를 사용하여 특정 점에서 F를 계산할 수 있습니다.
Vq = F(Pq)는 행렬 Pq의 쿼리 점에서 F를 계산합니다. Pq의 각 행은 쿼리 점의 좌표를 포함합니다.
Vq = F(Xq,Yq)와 Vq = F(Xq,Yq,Zq)는 쿼리 점을 크기가 동일한 두 개 또는 세 개의 배열로 지정합니다. F는 쿼리 점을 열 벡터로 취급합니다(예: Xq(:)).
F의Values속성이 샘플 점에서의 값 세트 하나를 나타내는 열 벡터이면Vq는 쿼리 점과 크기가 같습니다.F의Values속성이 샘플 점에서의 여러 값 세트를 나타내는 행렬이면Vq는 행렬이고 각 열은 쿼리 점에서의 서로 다른 값 세트를 나타냅니다.
예제
일부 샘플 점을 정의하고 샘플 점이 있는 위치에서 삼각 함수 값을 계산합니다. 이러한 샘플 점은 보간 함수에 대한 샘플 값이 됩니다.
t = linspace(3/4*pi,2*pi,50)'; x = [3*cos(t); 2*cos(t); 0.7*cos(t)]; y = [3*sin(t); 2*sin(t); 0.7*sin(t)]; v = repelem([-0.5; 1.5; 2],length(t));
보간 함수를 만듭니다.
F = scatteredInterpolant(x,y,v);
쿼리 위치 (xq,yq)에서 보간 함수를 실행합니다.
tq = linspace(3/4*pi+0.2,2*pi-0.2,40)'; xq = [2.8*cos(tq); 1.7*cos(tq); cos(tq)]; yq = [2.8*sin(tq); 1.7*sin(tq); sin(tq)]; vq = F(xq,yq);
결과를 플로팅합니다.
plot3(x,y,v,'.',xq,yq,vq,'.'), grid on title('Linear Interpolation') xlabel('x'), ylabel('y'), zlabel('Values') legend('Sample data','Interpolated query data','Location','Best')

샘플 산점 세트의 보간 함수를 만든 다음, 3차원 쿼리 점 세트에서 실행합니다.
임의의 점 200개를 정의하고 삼각 함수를 샘플링합니다. 이러한 샘플 점은 보간 함수에 대한 샘플 값이 됩니다.
rng default;
P = -2.5 + 5*rand([200 3]);
v = sin(P(:,1).^2 + P(:,2).^2 + P(:,3).^2)./(P(:,1).^2+P(:,2).^2+P(:,3).^2);보간 함수를 만듭니다.
F = scatteredInterpolant(P,v);
쿼리 위치 (xq,yq,zq)에서 보간 함수를 실행합니다.
[xq,yq,zq] = meshgrid(-2:0.25:2); vq = F(xq,yq,zq);
결과를 슬라이스로 플로팅합니다.
xslice = [-.5,1,2]; yslice = [0,2]; zslice = [-2,0]; slice(xq,yq,zq,vq,xslice,yslice,zslice)

샘플 점의 값을 변경하려면 Values 속성의 요소를 바꾸십시오. 원래 삼각분할은 변경되지 않기 때문에 새 보간 함수를 실행할 때 결과를 즉시 얻을 수 있습니다.
임의의 점 50개를 만들고 지수 함수를 샘플링합니다. 이러한 샘플 점은 보간 함수에 대한 샘플 값이 됩니다.
rng('default')
x = -2.5 + 5*rand([50 1]);
y = -2.5 + 5*rand([50 1]);
v = x.*exp(-x.^2-y.^2);보간 함수를 만듭니다.
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
(1.40,1.90)에서 보간 함수를 실행합니다.
F(1.40,1.90)
ans = 0.0069
보간 함수 샘플 값을 변경하고 같은 점에서 보간 함수를 다시 실행합니다.
vnew = x.^2 + y.^2; F.Values = vnew; F(1.40,1.90)
ans = 5.6491
scatteredInterpolant를 호출하기 전에 groupsummary를 사용하여 중복된 샘플 점을 제거하고 샘플 점이 결합되는 방식을 제어합니다.
샘플 점 위치로 구성된 200×3 행렬을 만듭니다. 마지막 5개 행에 중복된 점을 추가합니다.
P = -2.5 + 5*rand(200,3); P(197:200,:) = repmat(P(196,:),4,1);
샘플 점에서 난수 값으로 구성된 벡터를 만듭니다.
V = rand(size(P,1),1);
중복된 샘플 점으로 scatteredInterpolant를 사용하려고 시도하면 scatteredInterpolant는 경고를 발생시키고 V의 대응하는 값들의 평균을 구하여 하나의 고유 점을 생성합니다. 하지만, 보간 함수를 만들기 전에 groupsummary를 사용하여 중복된 점을 제거할 수 있습니다. 이는 평균이 아닌 다른 방법으로 중복 점을 결합하려는 경우에 특히 유용합니다.
groupsummary를 사용하여 중복된 샘플 점을 제거하고, 중복된 샘플 점 위치에서 V의 최댓값을 유지합니다. 샘플 점 행렬을 그룹화 변수로 지정하고 대응되는 값들을 데이터로 지정합니다.
[V_unique,P_unique] = groupsummary(V,P,@max);
그룹화 변수에는 3개의 열이 있으므로 groupsummary는 고유 그룹 P_unique를 셀형 배열로 반환합니다. 셀형 배열을 다시 행렬로 변환합니다.
P_unique = [P_unique{:}];보간 함수를 만듭니다. 이제 샘플 점들이 고유하므로 scatteredInterpolant는 경고를 발생시키지 않습니다.
I = scatteredInterpolant(P_unique,V_unique);
scatteredInterpolant가 제공하는 여러 보간 알고리즘의 결과를 비교합니다.
산점 50개로 이루어진 샘플 데이터 세트를 만듭니다. 보간 방법 간의 차이점이 명확하게 드러나도록 점 개수를 인위적으로 적게 했습니다.
x = -3 + 6*rand(50,1); y = -3 + 6*rand(50,1); v = sin(x).^4 .* cos(y);
보간 함수와 쿼리 점 그리드를 만듭니다.
F = scatteredInterpolant(x,y,v); [xq,yq] = meshgrid(-3:0.1:3);
'nearest', 'linear', 'natural' 방법을 사용하여 결과를 플로팅합니다. 보간 방법이 변경될 때마다 보간 함수를 다시 쿼리해야 업데이트된 결과를 얻을 수 있습니다.
F.Method = 'nearest'; vq1 = F(xq,yq); plot3(x,y,v,'mo') hold on mesh(xq,yq,vq1) title('Nearest Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')

F.Method = 'linear'; vq2 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq2) title('Linear') legend('Sample Points','Interpolated Surface','Location','NorthWest')
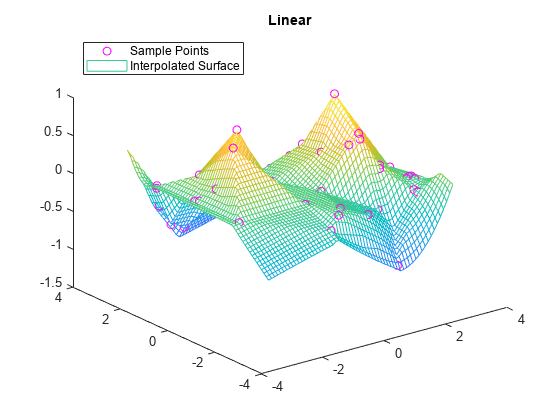
F.Method = 'natural'; vq3 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq3) title('Natural Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')
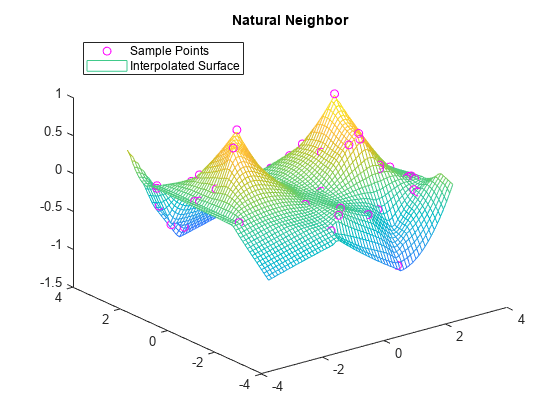
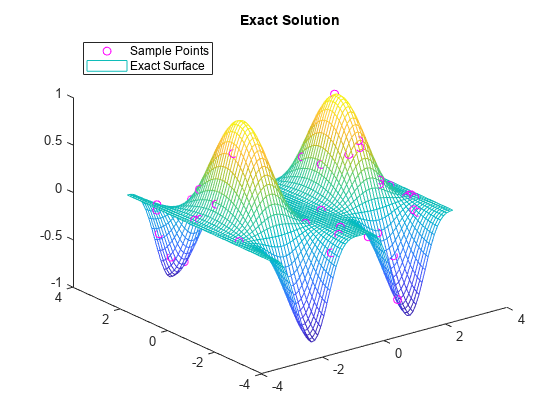
엄밀해(Exact Solution)를 플로팅합니다.
figure plot3(x,y,v,'mo') hold on mesh(xq,yq,sin(xq).^4 .* cos(yq)) title('Exact Solution') legend('Sample Points','Exact Surface','Location','NorthWest')
R2024a 이후
scatteredInterpolant가 제공하는 여러 외삽 방법의 결과를 비교합니다.
산점 50개로 이루어진 샘플 데이터 세트를 만들고 해당 위치에서 삼각 함수의 값을 계산합니다. 이러한 샘플 점은 보간 함수에 대한 샘플 값이 됩니다.
rng default
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);
v = sin(x).^4 .* cos(y);보간 함수를 만듭니다.
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
입력 데이터의 경계를 계산합니다.
C = convhull(x,y); xc = [x(C); x(C(1))]; yc = [y(C); y(C(1))]; vc = [v(C); v(C(1))];
경계 기울기를 기반으로 한 선형 외삽을 사용하여 쿼리 위치 (xq,yq)에서 보간 함수를 실행합니다. 그런 다음 보간 및 외삽 결과를 플로팅합니다.
[xq,yq] = meshgrid(-4:0.1:4); vq1 = F(xq,yq); surf(xq,yq,vq1,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + linear extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

최근접이웃 외삽을 사용하도록 보간 함수를 수정한 다음, 보간 함수를 실행하고 시각화합니다.
F.ExtrapolationMethod = "nearest"; vq2 = F(xq,yq); surf(xq,yq,vq2,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Nearest extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

보간 함수를 수정하여 보간 경계를 외삽 영역으로 확장한 다음, 보간 함수를 실행하고 시각화합니다.
F.ExtrapolationMethod = "boundary"; vq3 = F(xq,yq); surf(xq,yq,vq3,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Boundary extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

플로팅된 결과를 검토하여 외삽 방법을 비교합니다. 경계 외삽은 보간 영역과 외삽 영역 사이의 연속성을 유지하는 반면, 최근접이웃 외삽은 경계를 따라 불연속적일 수 있습니다. 경계 외삽은 외삽 영역에서 극값을 생성하지 않는 반면, 선형 외삽은 극값을 생성할 수 있습니다.
R2023b 이후
동일한 쿼리 점에서 여러 데이터 세트를 보간합니다.
샘플 점 벡터 x와 y로 표현되는 산점 50개로 이루어진 샘플 데이터 세트를 만듭니다.
rng("default")
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);여러 데이터 세트를 보간하려면 각 열이 해당 샘플 점에서의 서로 다른 함수의 값을 나타내는 행렬을 만듭니다.
s1 = sin(x).^4 .* cos(y); s2 = sin(x) + cos(y); s3 = x + y; s4 = x.^2 + y; v = [s1 s2 s3 s4];
v의 각 값 세트에 대해 보간을 수행할 위치를 나타내는 쿼리 점 벡터를 만듭니다.
xq = -3:0.1:3; yq = -3:0.1:3;
보간 함수 F를 만듭니다.
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×4 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
쿼리 위치에서 보간 함수를 실행합니다. Vq의 각 페이지는 v의 대응하는 데이터 세트에 대해 보간된 값을 포함합니다.
Vq = F({xq,yq});
size(Vq)ans = 1×3
61 61 4
각 데이터 세트에 대해 보간된 값을 플로팅합니다.
tiledlayout(2,2) nexttile plot3(x,y,v(:,1),'mo') hold on mesh(xq,yq,Vq(:,:,1)') title("sin(x).^4 .* cos(y)") nexttile plot3(x,y,v(:,2),'mo') hold on mesh(xq,yq,Vq(:,:,2)') title("sin(x) + cos(y)") nexttile plot3(x,y,v(:,3),'mo') hold on mesh(xq,yq,Vq(:,:,3)') title("x + y") nexttile plot3(x,y,v(:,4),'mo') hold on mesh(xq,yq,Vq(:,:,4)') title("x.^2 + y") lg = legend("Sample Points","Interpolated Surface"); lg.Layout.Tile = "north";

세부 정보
팁
함수
griddata또는griddatan을 사용하여 보간을 따로따로 계산하는 것보다 여러 쿼리 점에서scatteredInterpolant객체F를 실행하는 편이 더 빠릅니다. 예를 들면 다음과 같습니다.% Fast to create interpolant F and evaluate multiple times F = scatteredInterpolant(X,Y,V) v1 = F(Xq1,Yq1) v2 = F(Xq2,Yq2) % Slower to compute interpolations separately using griddata v1 = griddata(X,Y,V,Xq1,Yq1) v2 = griddata(X,Y,V,Xq2,Yq2)
보간 샘플 값 또는 보간 방법을 변경하려면 새로운
scatteredInterpolant객체를 만드는 것보다 interpolant 객체F의 속성을 업데이트하는 편이 더 효율적입니다.Values또는Method를 업데이트할 경우 입력 데이터의 기본 들로네 삼각분할은 변경되지 않으므로 새 결과를 신속히 계산할 수 있습니다.scatteredInterpolant를 통한 산점 데이터 보간은 데이터의 들로네 삼각분할을 사용하기 때문에, 보간은 샘플 점x,y,z또는P의 스케일링 문제에 민감할 수 있습니다. 스케일링 문제가 발생하는 경우normalize를 사용하여 데이터를 다시 스케일링하고 결과를 개선할 수 있습니다. 자세한 내용은 크기가 서로 다른 데이터를 정규화하기 항목을 참조하십시오.
알고리즘
scatteredInterpolant는 샘플 산점의 들로네 삼각분할을 사용하여 보간을 수행합니다. ([1])
참고 문헌
[1] Amidror, Isaac. “Scattered data interpolation methods for electronic imaging systems: a survey.” Journal of Electronic Imaging. Vol. 11, No. 2, April 2002, pp. 157–176.
확장 기능
버전 내역
R2013a에 개발됨참고 항목
griddedInterpolant | griddata | griddatan | ndgrid | meshgrid