크기가 서로 다른 데이터를 정규화하기
이 예제에서는 정규화를 사용하여 griddata로 산점 데이터 보간 결과를 향상시키는 방법을 보여줍니다. 경우에 따라 정규화는 보간 결과를 향상시킬 수도 있지만, 해의 정확도에 좋지 않은 영향을 미칠 수도 있습니다. 정규화를 사용할지 여부는 보간되는 데이터의 특성에 따라 판단하시기 바랍니다.
이점: 독립 변수들이 서로 다른 단위와 서로 크게 다른 범위를 갖는 경우 데이터를 정규화하면 보간 결과가 향상될 수 있습니다. 이 경우, 입력값을 비슷한 크기로 스케일링하면 보간의 수치적 특성을 향상시킬 수 있습니다. 예를 들어,
x가 500에서 3500까지의 엔진 속도를 나타내고(RPM 단위)y가 0에서 1까지의 엔진 부하를 나타내는 경우에는 정규화를 하는 것이 유용할 것입니다.x의 범위와y의 범위는 차이가 꽤 크며, 단위도 다릅니다.주의: 독립 변수의 단위가 같은 경우에는 해당 변수의 범위가 다르더라도 데이터를 정규화할 때 주의하십시오. 데이터의 단위가 같으면 정규화가 방향성 편향을 추가하여 해를 왜곡합니다. 이는 기본 삼각분할에 영향을 미치고 궁극적으로 보간의 정확도에도 좋지 않은 영향을 미칩니다. 예를 들어,
x와y가 모두 위치를 나타내고 미터 단위를 사용하는 경우에는 정규화가 잘못될 수 있습니다. 정동쪽 10m는 정북쪽 10m와 공간적으로 동일하므로x와y를 균일하지 않게 스케일링하는 것은 권장되지 않습니다.
y의 값이 x의 값보다 훨씬 더 큰 샘플 데이터를 생성해 보겠습니다. x와 y의 단위가 서로 다르다고 간주하겠습니다.
x = rand(1,500)/100; y = 2.*(rand(1,500)-0.5).*90; z = (x.*1e2).^2;
샘플 데이터를 사용하여 쿼리 점의 그리드를 생성합니다. 그리드의 샘플 데이터를 보간하고 결과를 플로팅합니다.
X = linspace(min(x),max(x),25); Y = linspace(min(y),max(y),25); [xq, yq] = meshgrid(X,Y); zq = griddata(x,y,z,xq,yq); plot3(x,y,z,'mo') hold on mesh(xq,yq,zq) xlabel('x') ylabel('y') hold off
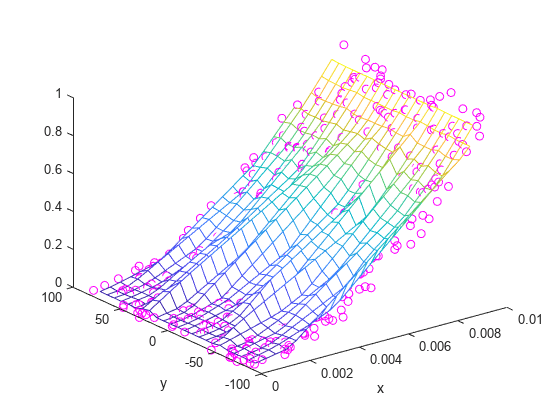
griddata를 사용하여 생성된 결과는 매끄럽지 않고 잡음이 있어 보입니다. 이러한 결과는 독립 변수의 범위가 다르기 때문인데, 한 변수의 크기가 조금만 변경되어도 다른 변수의 크기가 크게 변경될 수 있습니다.
x와 y의 단위가 서로 다르므로, 비슷한 크기를 갖도록 이를 정규화하면 결과를 향상시키는 데 도움이 됩니다. z-점수를 사용하여 샘플 점을 정규화하고 griddata를 사용하여 보간을 다시 생성합니다.
% Normalize Sample Points x = normalize(x); y = normalize(y); % Regenerate Grid X = linspace(min(x),max(x),25); Y = linspace(min(y),max(y),25); [xq, yq] = meshgrid(X,Y); % Interpolate and Plot zq = griddata(x,y,z,xq,yq); plot3(x,y,z,'mo') hold on mesh(xq,yq,zq)

이 예에서는 샘플 점을 정규화하면 griddata가 더 매끄러운 해를 계산할 수 있습니다.