mode
배열에서 최빈값
설명
M = mode(A)A의 샘플 최빈값, 즉 A에서 가장 자주 발생하는 값을 반환합니다. 발생 빈도가 같은 값이 여럿이면 mode는 그중 가장 작은 값을 반환합니다. 입력값이 복소수면, 그중 가장 작은 값이 정렬된 목록에서 첫 번째 값이 됩니다.
A가 벡터인 경우mode(A)는A의 최빈값을 반환합니다.A가 비어 있지 않은 행렬인 경우mode(A)는A의 각 열 최빈값을 포함하는 행 벡터를 반환합니다.A가 빈 0×0 행렬인 경우mode(A)는NaN을 반환합니다.A가 다차원 배열인 경우mode(A)는 크기가1이 아닌 첫 번째 배열 차원에 있는 값을 벡터로 취급하고 최빈값으로 구성된 배열을 반환합니다. 이 차원의 크기는1이 되고 다른 모든 차원의 크기는 변경되지 않습니다.A가 테이블 또는 타임테이블인 경우mode(A)는 각 변수의 최빈값을 포함하는 한 행 크기의 테이블을 반환합니다. (R2023a 이후)
예제
입력 인수
입력 배열로, 벡터, 행렬, 다차원 배열, 테이블 또는 타임테이블로 지정됩니다. A는 숫자형 배열, categorical형 배열, datetime형 배열, duration형 배열, 또는 이러한 데이터형의 변수를 갖는 테이블 또는 타임테이블일 수 있습니다.
입력 배열 A에서 NaN 또는 NaT(Not-a-Time) 값은 무시됩니다. categorical형 배열에서 정의되지 않은 값은 숫자형 배열에서 NaN과 유사합니다.
연산을 수행할 차원으로, 양의 정수 스칼라로 지정됩니다. 차원을 지정하지 않을 경우, 디폴트 값은 크기가 1이 아닌 첫 번째 배열 차원이 됩니다.
차원 dim은 길이가 1로 줄어드는 차원을 나타냅니다. size(M,dim)은 1이 되고, 다른 모든 차원의 크기는 변경되지 않습니다.
m×n 입력 행렬 A가 있다고 가정합니다.
mode(A,1)은A의 각 열에서 요소들의 최빈값을 구하고,1×n행 벡터를 반환합니다.
mode(A,2)는A의 각 행에서 요소들의 최빈값을 구하고,m×1열 벡터를 반환합니다.
dim이 ndims(A)보다 큰 경우 mode은 A를 반환합니다.
차원의 벡터로, 양의 정수로 구성된 벡터로 지정됩니다. 각 요소는 입력 배열의 차원을 나타냅니다. 지정된 연산 차원의 출력값의 길이는 1이고, 다른 모든 차원의 길이는 변경되지 않습니다.
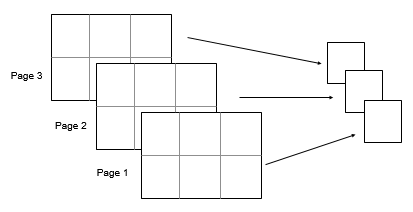
2×3×3 입력 배열 A가 있다고 가정하겠습니다. 이때 mode(A,[1 2])는 A의 각 페이지의 최빈값을 요소로 갖는 1×1×3 배열을 반환합니다.
출력 인수
팁
mode함수는 이산 데이터나 크게 반올림된 데이터에서 가장 유용합니다. 연속 확률 분포의 최빈값은 밀도 함수의 피크로 정의됩니다.mode함수를 이 분포의 샘플에 적용해 양호한 피크 추정값을 얻기는 어렵습니다. 히스토그램 또는 밀도 추정치를 계산하고 이 추정값의 피크를 계산하는 것이 더 좋습니다. 또한mode함수는 여러 개의 최빈값이 있는 분포에서 피크를 찾기에 적합하지 않습니다.
확장 기능
버전 내역
R2006a 이전에 개발됨참고 항목
mean | median | histogram | histcounts | sort