Phase I: Modeling Steady State Conditions | Fault Detection and Diagnosis in Chemical and Petrochemical Processes, Part 2
From the series: Fault Detection and Diagnosis in Chemical and Petrochemical Processes
The goal of process monitoring is to ensure that the planned operations are successful. You can achieve this goal by recognizing process upsets and faults using data-driven measures, such as PCA. These measures are derived directly from process data and aid in fault detection and diagnosis by transforming the high dimensional data into a lower dimension, and thereby capturing important information in the process.
Create a PCA model to describe the normal variability in the operation of a methanol-ethanol distillation column. Building an effective monitoring system requires a good data set that represents the steady-state, normal operating conditions. Use an application developed in MATLAB® by GIEM as an aid for understanding the PCA-based MSPC strategy.
Published: 21 Jan 2021
Welcome back. In the previous video we had a brief introduction to applied multivariate analysis. In this video I will show you the first phase of the demonstration, which is modeling the steady state conditions. A chemical production unit has multiple process sensors, and the traditional way to look at process data has been to look at it in a univariate method. You look at every process variable individually. Perhaps you like to look at them in a simple chart. And most process disturbance allow for that.
Regardless, this is the traditional way of monitoring the process. In almost all cases, this monitoring is done after the fact. Say a process that did occur or you want to create a daily report. That is when you seriously look at the data. This happens because it is difficult to keep monitoring every process variable all of the time. We add operator alarms for when a limit is triggered but those happen when a process upset has already occurred.
Most process variables are correlated, so it is very hard for a process engineer to determine which process variables are the most important ones. Also, while we do have feedback control analysis at most plants, they cannot compensate for many types of disturbances. For instance, what you can see here is that a process upset has occurred. We see the process data after it has been processed without any annoyance. This is a relatively simple fault and here you can figure it out. But in general, we won't have advanced funding for these kinds of things.
As a process engineer, if you look at this, you ask yourself two questions. When is the fault occurring and which process variable is responsible for it? Fault detection and diagnosis algorithms seek to answer those questions. Principal component analysis or PCA is a multi-data analysis method that is the popular method for fault detection and diagnosis. Ideally, as a result of applying these algorithms, you end up with something like what you see on the screen here.
You have an algorithm finding you to the exact kind of process [INAUDIBLE]. And not only that, but also telling you which variable is responsible for the upset. Now, this is a powerful algorithm for that purpose. This is especially effective because there is an abundance of data in processes that feeds directly to the strength of the data-driven approaches.
Now let us dive into the demo. The demo that I will be talking about today is actually one that is made by the Community. This is made by Politécnico de Valencia, specifically a research group there called Multivariate Statistical Engineering Group, GIEM for short. And you can download and use it for free from MATLAB [INAUDIBLE]. If you Google for a benchmark software for MSPC or just MATLAB MSPC, you will be able to find this.
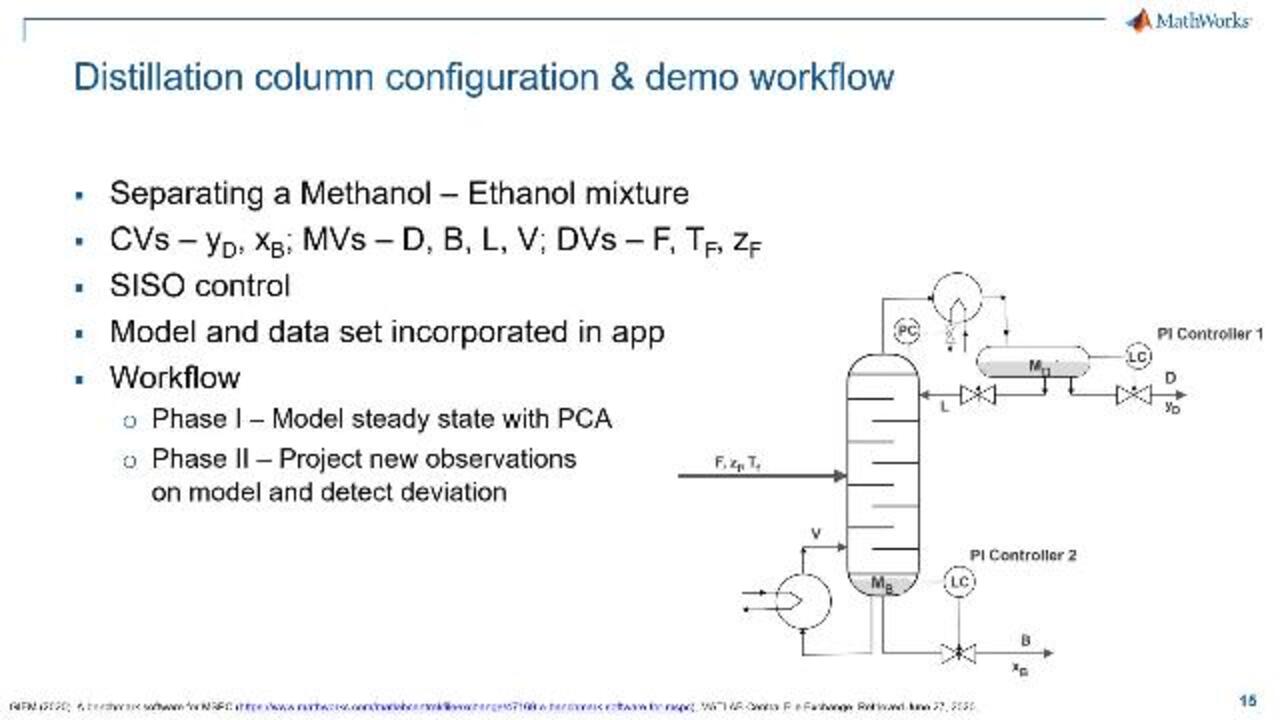
The unit that we will be looking at is a distillation column. This is purifying a methanol-ethanol mixture. The controlled variables are YD and XB, which represent the quality variables in the top and bottom respectively. The manipulated variables are the [INAUDIBLE] flow rate, bottom flow rate, reflux and method flow rate back to the column.
The disturbance variables are the feed flow rate, and pressure of the feed, and the quality of the feed. It also has two simple [INAUDIBLE] loops with single input, single output control. In this case, the column has already been modeled intuitively by the authors. And not only that, but they have also incorporated the data set into the app.
That also consists of two main steps. Phase one, with a data-driven model of the normal operating conditions of the steady state operations using PCA. And phase two is where you extract the model by projecting the new stream data or current operations onto the model and detecting the faults. The idea is that the PCA model now understands what a steady state looks like, it recalls the signature and any deviation from this as it applies as a fault.
In order to model the operating conditions, you need access to historical data. This data set is one in which the process has been operating in steady state in a MATLAB [INAUDIBLE]. Occasionally, this historical in-control data set is not directly available but has to be extracted from historical databases in an isolated fashion. In my case, I don't have historical data. So the creators of this app, they have very nicely incorporated a Simulink model of the distillation column into the app. And that is how we assume the data.
Now, let us go to the app. You start the application model in dispatch. So this is the main interface of the application. You can see that the interactive view right here, we load the example specs. So this is the main interface to produce the simulated data. You input the simulation time, the sample time, and choose to add the [INAUDIBLE]. And you select one of three operating points.
Also, we can change the values of the disturbance variables every few minutes to simulate a disturbance. In this particular case, what we are seeing is that there are three properties, such as the temperature, quality and the feed flow rate can change with a maximum of 5% every 10 minutes. Because simulation of the model will take some time, the authors have conveniently already done this for us and incorporated this data set into the app. Let us see what that looks like.
So this is what the process data looks like. Each of these represents a particular process variable. For instance, this is the quality of the feed, this is the temperature, and the feed flow rate, and so on and so forth. We had to specify a simulation time of 300 points and we can see 200 points here. Remember that this corresponds to a simulation time of 600 seconds because sampling time is 30 seconds.
So now that we have normal operating conditions or steady state conditions, we want to create a PCA model based on these normal operating conditions. But before we do that, we need to reduce the data set to build a model. There are 300 points to build a model, but we don't need all 300 points because this will increase the computing requirements. So we need to select an appropriate number of observations that represent the information in the entire data set. And also reduces the computational effort.
And that is what this [INAUDIBLE] approach is doing here, the algorithm that has the PCA model based on the smallest data set. The way it does that is by first selecting a random subset, fitting the PCA model to that, computing the percentage of all those control points, and then it compares it to a threshold. If it is below the threshold of 5%, then the data set is selected. Otherwise, these steps are repeated.
In this particular app, all these steps have been condensed into one particular button. So if you click on PCA and automatic selection, the entire process, the entire algorithm that I just showed you before, is being done over here. So once we see that it has finished running through this process, we can see the end result of this algorithm.
And that is demonstrated by the red star over here. So this is telling me that you can create a model that is a representative of the entire 300 data points by instead using a much smaller data set of 154 points instead. The red dash line represents our threshold for the acceptable number of all the control points. So at 154 observations, a percentage of all those control points is less than 5%. So that is why it is acceptable and it has auto selected.
So now we build a PCA model, and we do so by clicking on the specific button. So now we build a PCA model by clicking on this button. And this chart is telling me how much information I have captured in the principal components. You can see here that I have captured more than 93% of the variance or the information in my original data set in these three principal components.
Next, we need to compute the control limits. This is captured in the SPE chart and the Hotelling T squared chart. A little bit of background about these charts. SPE statistic gives a measure of the distance of the samples from the processing within the plane defined reference principal components. The SPE number looks at the distance of an observation to the model. A high T squared statistic first indicates that a sample is exhibiting an extreme variation but was accounted for by the PCA model.
Let us look at what that looks like for our model. So these charts are actually very easy to interpret. The red straight line indicates 90% confidence interval, and the dash line indicates 95% confidence interval. Since in this case, we assumed the principal component allows this model to recognize the steady state condition, you don't see any fault here.
So now we have successfully captured the steady state information in the model and the control charts. We have successfully trained our model to recognize normal operating conditions. Now our model is ready to capture any deviation from these normal conditions. And that brings us to phase two, which is model exploitation.

Featured Product
Statistics and Machine Learning Toolbox
Up Next:

Related Videos:





웹사이트 선택
번역된 콘텐츠를 보고 지역별 이벤트와 혜택을 살펴보려면 웹사이트를 선택하십시오. 현재 계신 지역에 따라 다음 웹사이트를 권장합니다: United States
또한 다음 목록에서 웹사이트를 선택하실 수도 있습니다.
미주
- América Latina (Español)
- Canada (English)
- United States (English)
유럽
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)