다음에 대한 결과:
The challenge:
You are given a string of lowercase letters 'a' to 'z'.
Each character represents a base-26 digit:
- 'a' = 0
1. Understand the Base-26 Conversion Process:
Let the input be s = 'aloha'.
Convert each character to a digit:
digits = double(s) - double('a');
This works because:
double('a') = 97
double('b') = 98
So:
double('a') - 97 = 0
double('l') - 97 = 11
double('o') - 97 = 14
double('h') - 97 = 7
double('a') - 97 = 0
Now you have:
[0 11 14 7 0]
2. Interpret as Base-26:
For a number with n digits:
d1 d2 d3 ... dn
Value = d1*26^(n-1) + d2*26^(n-2) + ... + dn*26^0
So for 'aloha' (5 chars):
0*26^4 + 11*26^3 + 14*26^2 + 7*26^1 + 0*26^0
MATLAB can compute this automatically.
3. Avoid loops — Use MATLAB vectorization:
You can compute the weighted sum using dot
digits = double(s) - 'a';
powers = 26.^(length(s)-1:-1:0);
result = dot(digits, powers);
This is clean, short, and vectorized.
4.Test with the examples:
char2num26('funfunfun')
→ 1208856210289
char2num26('matlab')
→ 142917893
char2num26('nasa')
→ 228956
To track the current leader after each match, you can use cumulative scores. First, calculate the cumulative sum for each player across the matches. Then, after eaayer with the highest score.
Hint: Use cumsum(S, 1) to get cumulative scores along the rows (matches). Loop through each row to keep track of the leader. If multiple players tie, pick the lowest index.
Example:
If S = [5 3 4; 2 6 2; 3 5 7], after match 3, the cumulative scores are [10 14 13]. Player 2 leads with 14 hilbs.
This method keeps your code clean and avoids repeatedly summing rows.
Congratulations to all the Cool Coders who have completed the problem set. I hope you weren't too cool to enjoy the silliness I put into the problems.
If you've solved the whole problem set, don't forget to help out your teammates with suggestions, tips, tricks, etc. But also, just for fun, I'm curious to see which of my many in-jokes and nerdy references you noticed. Many of the problems were inspired by things in the real world, then ported over into the chaotic fantasy world of Nedland.
I guess I'll start with the obvious real-world reference: @Ned Gulley (I make no comment about his role as insane despot in any universe, real or otherwise.)
Extracting the digits of a number will be useful to solve many Cody problems.
Instead of iteratively dividing by 10 and taking the remainder, the digits of a number can be easily extracted using String operations.
%Extract the digits of N
N = 1234;
d = num2str(N)-'0';
d =
1 2 3 4
Instead of looping with if-statements, use logical indexing:
A(A < 0) = 0;
One line, no loops, full clarity.
Whenever a problem repeats in cycles (like indexing or angles), mod() keeps your logic clean:
idx = mod(i-1, n) + 1;
No if-else chaos!
The toughest problem in the Cody Contest 2025 is Clueless - Lord Ned in the Game Room. Thank you Matt Tearle for such as wonderful problem. We can approach this clueless(!) tough problem systematically.
Initialize knowledge Matrix
Based on the hints provided in the problem description, we can initialize a knowledge matrix of size n*3 by m+1. The rows of the knowledge matrix represent the different cards and the columns represent the players. In the knowledge matrix, the first n rows represent category 1 cards, the next n rows, category 2 and the next category 3. We can initialize this matrix with zeros. On the go, once we know that a player holds the card, we can make that entry as 1 and if a player doesn't have the card, we can make that entry as -1.
yourcards processing
These are cards received by us.
- In the knowledge matrix, mark the entries as 1 for the cards received. These entries will be the some elements along the column pnum of the knowledge matrix.
- Mark all other entries along the column pnum as -1, as we don't receive other cards.
- Mark all other entries along the rows corresponding to the received cards as -1, as other players cannot receive the cards that are with us.
commoncards processing
These are the common cards kept open.
- In the knowledge matrix, mark the entries as 1 for the common cards. These entries will be some elements along the column (m+1) of the knowledge matrix.
- Mark all other entries along the column (m+1) as -1, as other cards are not common.
- Mark all other entries along the rows corresponding to the common cards as -1, as other players cannot receive the cards that are common.
Result -1 processing
In the turns input matrix, the result (5th column) value -1 means, the corresponding player doesn't have the 3 cards asked.
- Find all the rows with result as -1.
- For those corresponding players (1st element in each row of turns matrix), mark -1 entries in the knowledge matrix for those 3 absent cards.
pnum turns processing
These are our turns, so we get definite answers for the asked cards. Make sure to traverse only the rows corresponding to our turn.
- The results with -1 are already processed in the previous step.
- The results other than -1 means, that particular card is present with the asked player. So mark the entry as 1 for the corresponding player in the knowledge matrix.
- Mark all other entries along the row corresponding to step 2 as -1, as other players cannot receive this card.
Result 0 processing
So far, in the yourcards processing, commoncards processing, result -1 processing and pnum turns processing, we had very straightforward definite knowledge about the presence/absence of the card with a player. This step onwards, the tricky part of the problem begins.
result 0 means, any one (or more) of the asked cards are present with the asked player. We don't know exactly which card.
- For the asked player, if we have a definite no answer (-1 value in the knowledge matrix) for any two of the three asked cards, then we are sure about the card that is present with the player.
- Mark the entry as 1 for the definitely known card for the corresponding player in the knowledge matrix.
- Mark all other entries along the row corresponding to step 2 as -1, as other players cannot receive this card.
Cards per Player processing
Based on the number of cards present in the yourcards, we know the ncards, the number of cards per player.
Check along each column of the knowledge matrix, that is for each player.
- If the number of ones (definitely present cards) is equal to ncards, we can make all other entries along the column as -1, as this player cannot have any other card.
- If the sum of number of ones (definitely present cards) and the number of zeros (unknown cards) is equal to ncards, we can (i) mark the zero entries as one, as the unknown cards have become definitely present cards, (ii) mark all other entries along the column as -1, as other players cannot have any other card.
Category-wise cards checking
For each category, we must get a definite card to be present in the envelope.
- In each category (For every group of n rows of knowledge matrix), check for a row with all -1s. That is a card which is definitely not present with any of the players. Then this card will surely be present in the envelope. Add it to the output.
- If we could not find an all -1 row, then in that category, check each row for a 1 to be present. Note down the rows which doesn't have a 1. Those cards' players are still unknown. If we have only one such row (unknown card), then it must be in the envelope, as from each category one card is present in the envelope. Add it to the output.
- For the card identified in Step 2, mark all the entries along that row in the knowledge matrix as -1, as this card doesn't belong to any player.
Looping Over
In our so far steps, we could note that, the knowledge matrix got updated even after "Result 0 processing" step. This updation in the knowledge matrix may help the "Result 0 processing" step, if we perform it again. So, we can loop over the steps, "Result 0 processing", "Cards per Player processing" and "Category-wise cards checking" again. This ensures that, we will get the desired number of envelop cards (three in our case) as output.
Instead of growing arrays inside a loop, preallocate with zeros(), ones(), or nan(). It avoids memory fragmentation and speeds up Cody solutions.
A = zeros(1,1000);
Cody often hides subtle hints in example outputs — like data shape, rounding, or format. Matching those exactly saves you a lot of debugging time.
isequal() is your best friend for Cody! It compares arrays perfectly without rounding errors — much safer than == for matrix outputs.
When Cody hides test cases, test your function with random small inputs first. If it works for many edge cases, it will almost always pass the grader.
I realized that using vectorized logic instead of nested loops makes Cody problems run much faster and cleaner. Functions like any(), all(), and logical indexing can replace multiple for-loops easily !
Hi cool guys,
I hope you are coding so cool!
FYI, in Problem 61065. Convert Hexavigesimal to Decimal in Cody Contest 2025 there's a small issue with the text:
[ ... For example, the text ‘aloha’ would correspond to a vector of values [0 11 14 7 0], thus representing the base-26 value 202982 = 11*263 + 14*262 + 7*26 ...]
The bold section should be:
202982 = 11*26^3 + 14*26^2 + 7*26
Hey Cool Coders! 😎
Let’s get to know each other. Drop a quick intro below and meet your teammates! This is your chance to meet teammates, find coding buddies, and build connections that make the contest more fun and rewarding!
You can share:
- Your name or nickname
- Where you’re from
- Your favorite coding topic or language
- What you’re most excited about in the contest
Let’s make Team Cool Coders an awesome community—jump in and say hi! 🚀
Welcome to the Cody Contest 2025 and the Cool Coders team channel! 🎉
You stay calm under pressure. No panic, no chaos—just smooth problem-solving. This is your space to connect with like-minded coders, share insights, and help your team win. To make sure everyone has a great experience, please keep these tips in mind:
- Follow the Community Guidelines: Take a moment to review our community standards. Posts that don’t follow these guidelines may be flagged by moderators or community members.
- Ask Questions About Cody Problems: When asking for help, show your work! Include your code, error messages, and any details needed to reproduce your results. This helps others provide useful, targeted answers.
- Share Tips & Tricks: Knowledge sharing is key to success. When posting tips or solutions, explain how and why your approach works so others can learn your problem-solving methods.
- Provide Feedback: We value your feedback! Use this channel to report issues or share creative ideas to make the contest even better.
Have fun and enjoy the challenge! We hope you’ll learn new MATLAB skills, make great connections, and win amazing prizes! 🚀
Automating Parameter Identifiability Analysis in SimBiology
Is it possible to develop a MATLAB Live Script that automates a series of SimBiology model fits to obtain likelihood profiles? The goal is to fit a kinetic model to experimental data while systematically fixing the value of one kinetic constant (e.g., k1) and leaving the others unrestricted.
The script would perform the following:
Use a pre-configured SimBiology project where the best fit to the experimental data has already been established (including dependent/independent variables, covariates, the error model, and optimization settings).
Iterate over a defined sequence of fixed values for a chosen parameter.
For each fixed value, run the estimation to optimize the remaining parameters.
Record the resulting Sum of Squared Errors (SSE) for each run.
The final output would be a likelihood profile—a plot of SSE versus the fixed parameter value (e.g., k1)—to assess the practical identifiability of each model parameter.
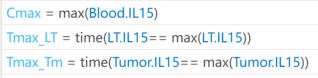
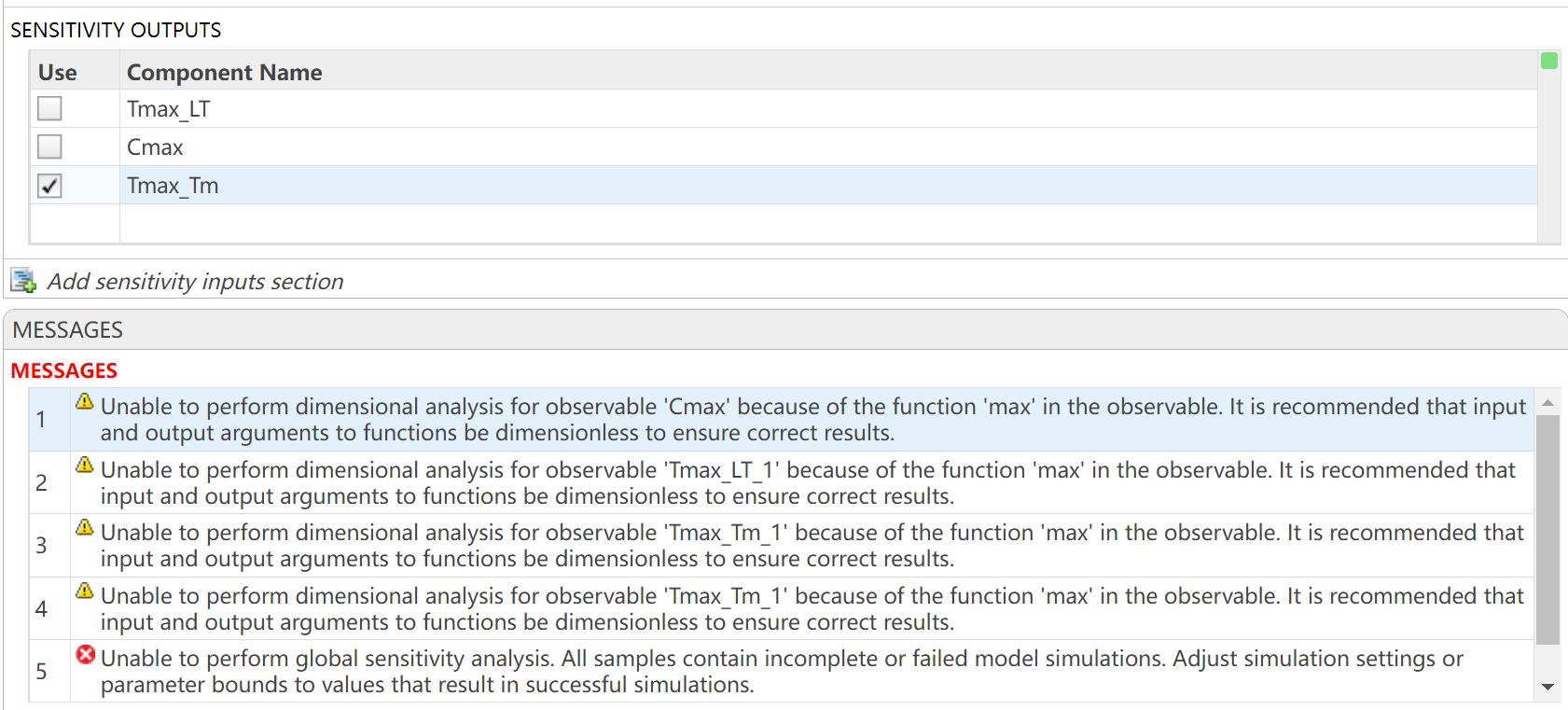
I want to observe the time (Tmax) to reach maximum drug concentration (Cmax) in my model. I have set up the OBSERVABLES as follows (figure1): Cmax = max(Blood.lL15); Tmax_LT = time(Conc_lL15_LT_nm == max(Conc_lL15_LT_nm)); Tmax_Tm = time(Conc_lL15_Tumor_nm == max(Conc_lL15_Tumor_nm)); After running the Sobol indices program for global sensitivity analysis, with inputs being some parameters and their ranges, the output for Cmax works, but there are some prompts, as shown in figure2. Additionally, when outputting Tmax, the program does not run successfully and reports some errors, as shown in figure2. How can I resolve the errors when outputting Tmax?
Hi All,
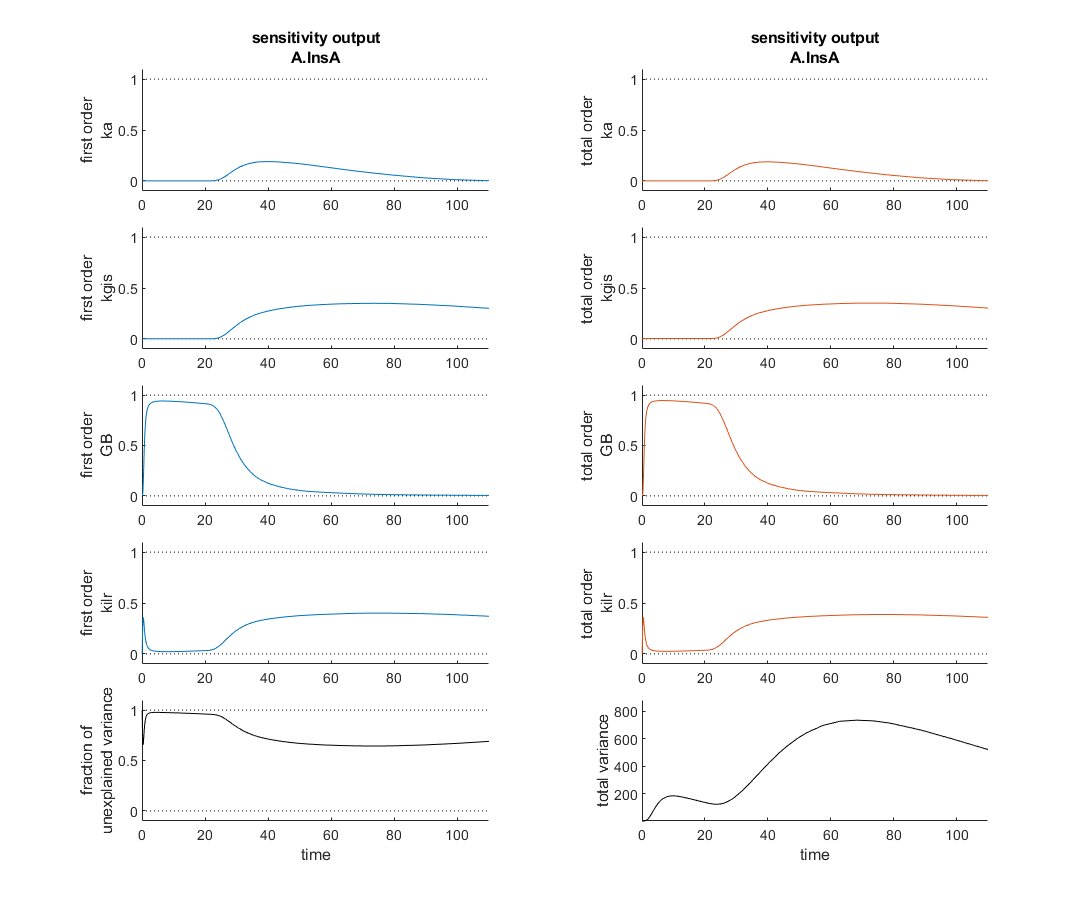
I'm currently verifying a global sensitivity analysis done in SimBiology and I'm a touch confused. This analysis was run with every parameter and compartment volume in the model. To my understanding the fraction of unexplained variance is 1 - the sum of the first order variances, therefore if the model dynamics are dominated by interparameter effects you might see a higher fraction of unexplained variance. In this analysis however, as the attached figure shows (with input at t=20 minutes), the most sensitive four parameters seem to sum, in first order sensitivities to roughly one at each time point and the total order sensitivies appear nearly identical. So how is the fraction of unexplained variance near one?
Thank you for your help!
Hi to everyone!
To simplify the explanation and the problem, I simulated the kinetics of an irreversible first-order reaction, A -> B. I implemented it in two independent compartments, R and P. I simulated the effect of a dilution in R by doubling at t= 0,1 the R volume. I programmed in P that, at t = 0.1, the instantaneous concentration of A and B would be reduced by half. I am sending an attach with the implementation of these simulations in the Simbiology interface.
When the simulations of the two compartments are plotted, it can be seen that the responses are not equal. That is, from t = 0.1 s, the reaction follow an exponential function in R with half of the initial amplitude and half of the initial value of k1. That is, the relaxation time is doubled. Meanwhile, in P, from t = 0.1, the reaction follows exponential kinetics with half the amplitude value but maintaining the initial value of k = 10. Without a doubt, the correct simulation is the latter (compartment P) where only the effect is observed in the amplitude and not in the relaxation time. Could you tell me what the error is that makes these kinetics that should be equal not be?
Thank you in advance!
Luis B.
Hi All,
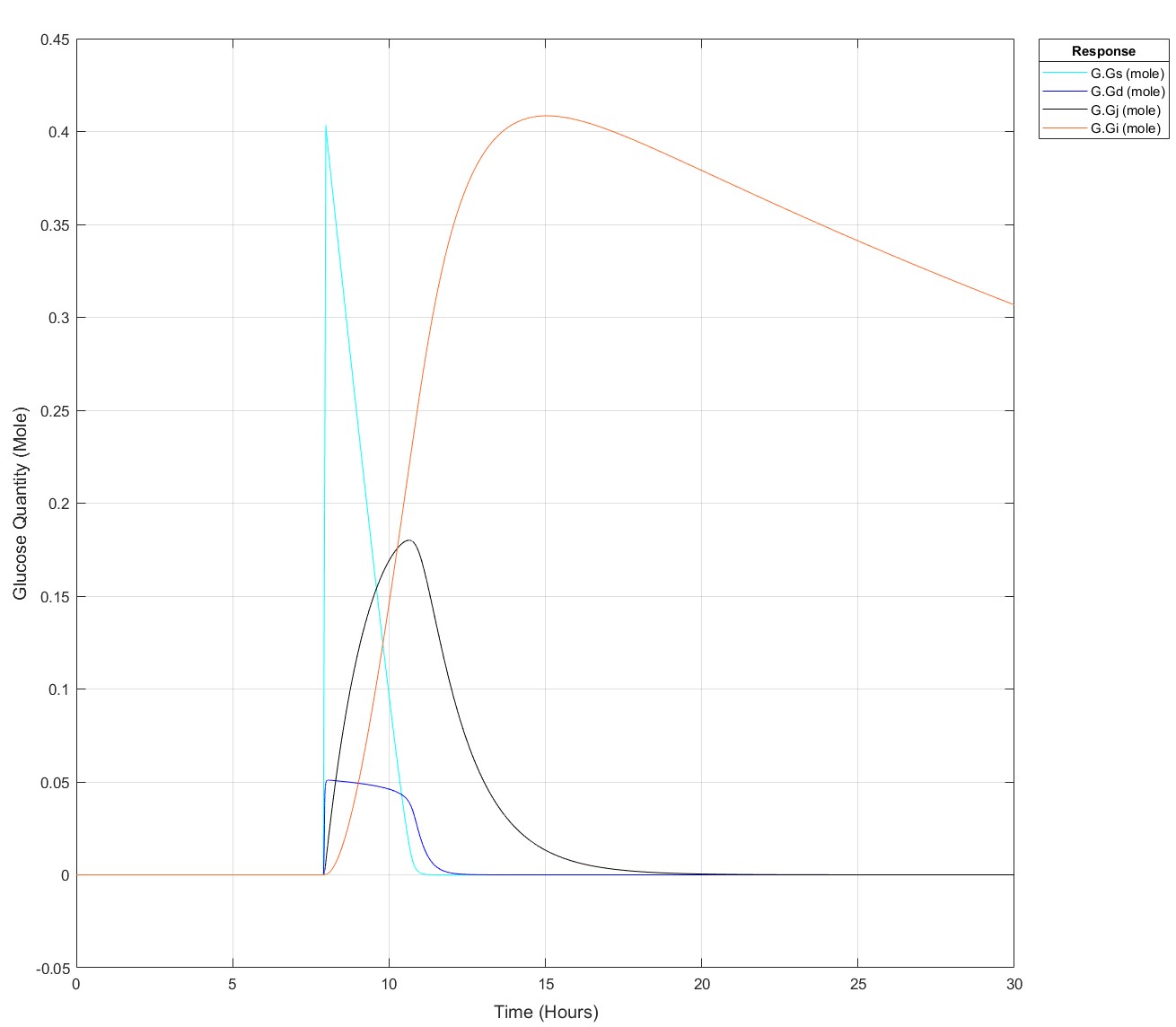
I've been producing a QSP model of glucose homeostasis for a while now for my PhD project, recently I've been able to expand it to larger time series, i.e. 2 days of data rather than a singular injection or a singular meal. My problem is as follows: If I put 75g of glucose into my stomach glucose species any later than (exactly) 8.5 hours I get an integration tolerance error. Curiosly, I can put 25g of glucose in at any time up to 15.9 hours, then any later an error. I have disabled all connections to my glucose absorption chain, i.e. stomach -> duodenum -> jenenum -> ileum -> removal, to isolate the cause of this. I had initially thought it may be because I mechanistically model liver glycogen and that does deplete over time, but I've tested enough to show that that does nothing. My next test is to isolate the glucose absorption chain into a seperate model and see if the issue persists but I'm completely baffled!
These are the equations, to my eye there's no reason why there would be such a sharp glucose quantity/time dependence, they all begin at a value of 0:
d(Gs)/dt = -(kw*(1-Gd^14/(Igd^14+Gd^14))*Gs) #Stomach glucose
d(Gd)/dt = (kw*(1-Gd^14/(Igd^14+Gd^14))*Gs) - (kdj*Gd) #Duodenal Glucose
d(Gj)/dt = (kdj*Gd) - (kji*Gj) #Jejunal Glucose
d(Gi)/dt = (kji*Gj) - (kic*Gi) #Ileal Glucose
(The sigmoidicity of gastric emptying slowing term (^14) was parameterised off of paracetamol absorption data and appears to be correct!)
Thank you for your help, best regards,
Dan
Pre-Edit: I changed the run time to 30 hours and now I can't use the 75g input any later than 7.9 hours not 8.5 hours anymore!
Edit: This is how it appears at all times prior to it failing for 75g: