이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
R-CNN, Fast R-CNN, Faster R-CNN 시작하기
객체 검출은 영상에서 객체를 찾고 분류하는 과정입니다. R-CNN(Regions with Convolutional Neural Networks)은 딥러닝 방식 중 하나로, 사각형 영역 제안을 컨벌루션 신경망 특징과 결합합니다. R-CNN은 2단계로 이루어진 검출 알고리즘입니다. 첫 번째 단계는 영상에서 객체가 포함되었을 수 있는 영역의 일부분을 식별합니다. 두 번째 단계는 각 영역의 객체를 분류합니다.
R-CNN 객체 검출기의 응용 분야는 다음과 같습니다.
자율 주행
스마트 감시 시스템
얼굴 인식
Computer Vision Toolbox™는 R-CNN, Fast R-CNN, Faster R-CNN 알고리즘을 이용한 객체 검출기를 제공합니다.
인스턴스 분할은 객체 검출을 확장하여 검출된 개별 객체를 픽셀 수준으로 분할합니다. Computer Vision Toolbox는 딥러닝 기반의 인스턴스 분할을 수행하는 Mask R-CNN을 지원하는 계층을 제공합니다. 자세한 내용은 Getting Started with Mask R-CNN for Instance Segmentation 항목을 참조하십시오.
R-CNN 알고리즘을 사용한 객체 검출
R-CNN(Regions with CNN)을 사용하는 객체 검출 모델은 다음과 같은 세 가지 과정을 기반으로 합니다.
영상에서 객체가 포함되었을 수 있는 영역을 찾습니다. 이러한 영역을 영역 제안이라고 합니다.
영역 제안에서 CNN 특징을 추출합니다.
추출된 특징을 사용하여 객체를 분류합니다.
R-CNN에는 세 가지 변형이 있습니다. 각 변형은 이 중 하나 이상의 과정으로 얻은 결과에 대해 최적화, 가속화 또는 향상을 시도합니다.
R-CNN
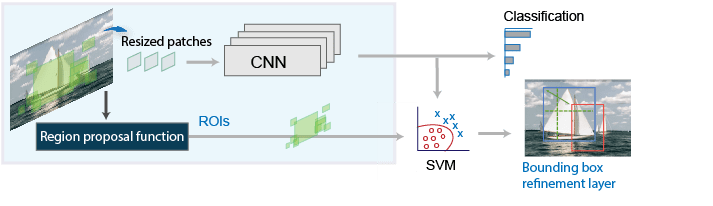
R-CNN 검출기[2]는 먼저 Edge Boxes[1]와 같은 알고리즘을 사용하여 영역 제안을 생성합니다. 영상에서 제안 영역이 잘리고 크기가 조정됩니다. 그런 다음, CNN이 잘리고 크기가 조정된 영역을 분류합니다. 마지막으로, CNN 특징을 사용하여 훈련된 SVM(서포트 벡터 머신)에 의해 영역 제안 경계 상자가 조정됩니다.
R-CNN 객체 검출기를 훈련시키려면 trainRCNNObjectDetector 함수를 사용합니다. 이 함수는 영상에서 객체를 검출하는 rcnnObjectDetector 객체를 반환합니다.
Fast R-CNN
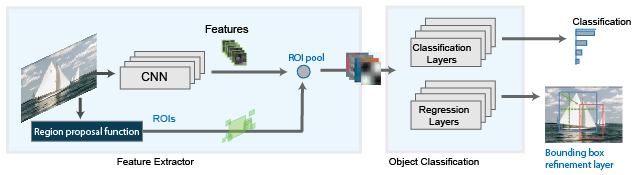
R-CNN 검출기와 마찬가지로, Fast R-CNN[3] 검출기도 Edge Boxes 같은 알고리즘을 사용하여 영역 제안을 생성합니다. 영역 제안을 자르고 크기를 조정하는 R-CNN 검출기와 달리, Fast R-CNN 검출기는 전체 영상을 처리합니다. R-CNN 검출기는 각 영역을 분류해야 하지만 Fast R-CNN은 각 영역 제안에 대응하는 CNN 특징을 풀링합니다. Fast R-CNN 검출기에서는 겹치는 영역에 대한 계산이 공유되기 때문에 Fast R-CNN은 R-CNN보다 효율성이 더 뛰어납니다.
Fast R-CNN 객체 검출기를 훈련시키려면 trainFastRCNNObjectDetector 함수를 사용합니다. 이 함수는 영상에서 객체를 검출하는 fastRCNNObjectDetector를 반환합니다.
Faster R-CNN
Faster R-CNN[4] 검출기는 Edge Boxes와 같은 외부 알고리즘을 사용하는 대신 영역 제안 신경망(RPN)을 추가하여 신경망에서 직접 영역 제안을 생성합니다. RPN은 객체 검출용 앵커 상자 방식을 사용합니다. 신경망에서 영역 제안을 생성하면 속도가 더 빠르고 데이터에 대해 더 잘 조정됩니다.
Faster R-CNN 객체 검출기를 훈련시키려면 trainFasterRCNNObjectDetector 함수를 사용합니다. 이 함수는 영상에서 객체를 검출하는 fasterRCNNObjectDetector를 반환합니다.

R-CNN 객체 검출기 비교
이 유형의 객체 검출기들은 영역 제안을 사용하여 영상 내 객체를 검출합니다. 제안 영역의 수에 따라 영상에서 객체를 검출하는 데 걸리는 시간이 정해집니다. Fast R-CNN 검출기와 Faster R-CNN 검출기는 영역의 수가 많을 때 검출 성능이 높아지도록 설계되었습니다.
| R-CNN 검출기 | 설명 |
|---|---|
trainRCNNObjectDetector |
|
trainFastRCNNObjectDetector |
|
trainFasterRCNNObjectDetector |
|
전이 학습
전이 학습이라고도 하는 사전 훈련된 CNN(컨벌루션 신경망)을 R-CNN 검출기의 기반으로 사용할 수 있습니다. 사전 훈련된 심층 신경망 (Deep Learning Toolbox) 항목을 참조하십시오. trainRCNNObjectDetector, trainFasterRCNNObjectDetector 또는 trainFastRCNNObjectDetector 함수와 함께 다음 신경망 중 하나를 사용합니다. 이러한 신경망을 사용하려면 대응하는 Deep Learning Toolbox™ 모델을 설치해야 합니다.
'
alexnet(Deep Learning Toolbox)''
vgg16(Deep Learning Toolbox)''
vgg19(Deep Learning Toolbox)''
resnet50(Deep Learning Toolbox)''
resnet101(Deep Learning Toolbox)''
inceptionv3(Deep Learning Toolbox)''
googlenet(Deep Learning Toolbox)''
inceptionresnetv2(Deep Learning Toolbox)''
squeezenet(Deep Learning Toolbox)'
사전 훈련된 영상 분류 CNN을 기반으로 사용자 지정 모델을 설계할 수도 있습니다. R-CNN, Fast R-CNN, Faster R-CNN 모델 설계하기 섹션과 심층 신경망 디자이너 (Deep Learning Toolbox) 앱을 참조하십시오.
R-CNN, Fast R-CNN, Faster R-CNN 모델 설계하기
사전 훈련된 영상 분류 CNN을 기반으로 사용자 지정 R-CNN 모델을 설계할 수 있습니다. 또는 심층 신경망 디자이너 (Deep Learning Toolbox)를 사용하여 딥러닝 신경망을 구축, 시각화하고 편집할 수 있습니다.
기본 R-CNN 모델은 사전 훈련된 신경망으로 시작합니다. 마지막 3개의 분류 계층은 검출하려는 객체 클래스에 맞춘 새 계층으로 대체됩니다.
R-CNN 객체 검출 신경망을 만드는 방법을 보여주는 예제는 Create R-CNN Object Detection Network 항목을 참조하십시오

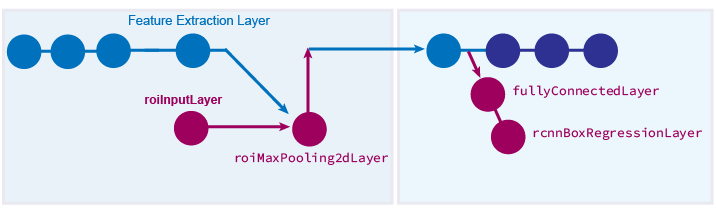
Fast R-CNN 모델은 기본 R-CNN 모델을 기반으로 합니다. 상자 오프셋 세트를 학습하여 영상에서 객체의 위치를 개선시키기 위한 상자 회귀 계층이 추가됩니다. 각 영역 제안에 대한 CNN 특징을 풀링하기 위해 ROI 풀링 계층이 신경망에 삽입됩니다.
Fast R-CNN 객체 검출 신경망을 만드는 방법을 보여주는 예제는 Create Fast R-CNN Object Detection Network 항목을 참조하십시오
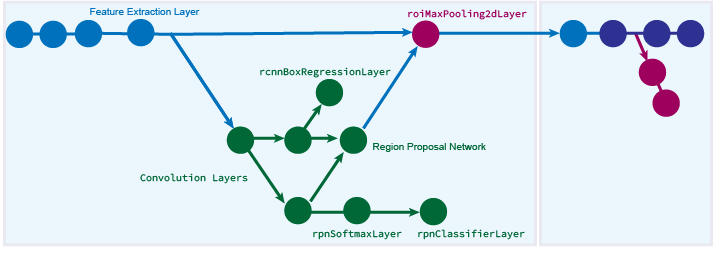
Faster R-CNN 모델은 Fast R-CNN 모델을 기반으로 합니다. 외부 알고리즘에서 제안을 가져오는 대신 영역 제안을 생성하기 위해 영역 제안 신경망이 추가됩니다.
Faster R-CNN 객체 검출 신경망을 만드는 방법을 보여주는 예제는 Create Faster R-CNN Object Detection Network 항목을 참조하십시오
딥러닝을 위해 훈련 데이터에 레이블 지정하기
영상 레이블 지정기, 비디오 레이블 지정기 또는 Ground Truth 레이블 지정기 (Automated Driving Toolbox) 앱을 사용하여 대화형 방식으로 픽셀에 레이블을 지정하고 훈련을 위해 레이블 데이터를 내보낼 수 있습니다. 또한 이러한 앱을 사용하여 객체 검출을 위해 사각형 관심 영역(ROI)에 레이블을 지정하고, 영상 분류를 위해 장면에 레이블을 지정하고, 의미론적 분할을 위해 픽셀에 레이블을 지정할 수 있습니다. 레이블 지정기에서 내보낸 ground truth 객체로부터 훈련 데이터를 만들려면 objectDetectorTrainingData 또는 pixelLabelTrainingData 함수를 사용합니다. 자세한 내용은 Training Data for Object Detection and Semantic Segmentation 항목을 참조하십시오.
참고 문헌
[1] Zitnick, C. Lawrence, and P. Dollar. "Edge boxes: Locating object proposals from edges." Computer Vision-ECCV. Springer International Publishing. Pages 391-4050. 2014.
[2] Girshick, R., J. Donahue, T. Darrell, and J. Malik. "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation." CVPR '14 Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Pages 580-587. 2014
[3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015
[4] Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." Advances in Neural Information Processing Systems . Vol. 28, 2015.
참고 항목
앱
- 영상 레이블 지정기 | Ground Truth 레이블 지정기 (Automated Driving Toolbox) | 비디오 레이블 지정기 | 심층 신경망 디자이너 (Deep Learning Toolbox)
함수
trainRCNNObjectDetector|trainFastRCNNObjectDetector|trainFasterRCNNObjectDetector|fasterRCNNObjectDetector|fastRCNNObjectDetector|rcnnObjectDetector
도움말 항목
- R-CNN 딥러닝을 사용하여 객체 검출기 훈련시키기
- Faster R-CNN 딥러닝을 사용한 객체 검출
- 객체 검출용 앵커 상자
- MATLAB의 딥러닝 (Deep Learning Toolbox)
- 사전 훈련된 심층 신경망 (Deep Learning Toolbox)