Faster R-CNN 딥러닝을 사용한 객체 검출
이 예제에서는 Faster R-CNN(Regions with Convolutional Neural Networks) 객체 검출기를 훈련시키는 방법을 다룹니다.
딥러닝은 강건한 객체 검출기를 훈련시키는 데 사용할 수 있는 강력한 머신러닝 기법입니다. Faster R-CNN과 YOLO(You Only Look Once) v2를 비롯하여 객체 검출을 위한 다양한 딥러닝 기법이 있습니다. 이 예제에서는 trainFasterRCNNObjectDetector 함수를 사용하여 Faster R-CNN 차량 검출기를 훈련시킵니다. 자세한 내용은 객체 검출 항목을 참조하십시오.
사전 훈련된 검출기 다운로드하기
훈련이 완료될 때까지 기다릴 필요가 없도록 사전 훈련된 검출기를 다운로드합니다. 검출기를 직접 훈련시키려면 doTraining 변수를 true로 설정하십시오.
doTraining = false; if ~doTraining && ~exist("fasterRCNNResNet50EndToEndVehicleExample.mat","file") disp("Downloading pretrained detector (118 MB)..."); pretrainedURL = "https://www.mathworks.com/supportfiles/vision/data/fasterRCNNResNet50EndToEndVehicleExample.mat"; websave("fasterRCNNResNet50EndToEndVehicleExample.mat",pretrainedURL); end
Downloading pretrained detector (118 MB)...
데이터 세트 불러오기
이 예제에서는 295개의 영상을 포함하는 규모가 작은 레이블 지정된 데이터셋을 사용합니다. 이러한 영상의 많은 부분은 Caltech Cars 1999 및 2001 데이터 세트에서 가져온 것으로, Pietro Perona가 만들었으며 허락 하에 사용되었습니다. 각 영상에는 차량에 대해 레이블 지정된 건수가 한 건 또는 두 건 있습니다. 작은 데이터셋은 Faster R-CNN 훈련 절차를 살펴보기에 유용하지만, 실전에서 강건한 검출기를 훈련시키려면 레이블이 지정된 영상이 더 많이 필요합니다. 차량 영상의 압축을 풀고 차량 ground truth 데이터를 불러옵니다.
unzip vehicleDatasetImages.zip data = load("vehicleDatasetGroundTruth.mat"); vehicleDataset = data.vehicleDataset;
차량 데이터는 2열 테이블에 저장되어 있습니다. 첫 번째 열은 영상 파일 경로를 포함하고, 두 번째 열은 차량 경계 상자를 포함합니다.
데이터셋을 훈련 세트, 검증 세트, 테스트 세트로 분할합니다. 데이터의 60%를 훈련용으로, 데이터의 10%를 검증용으로, 나머지를 훈련된 검출기의 테스트용으로 선택합니다.
rng(0) shuffledIndices = randperm(height(vehicleDataset)); idx = floor(0.6 * height(vehicleDataset)); trainingIdx = 1:idx; trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:); validationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) ); validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:); testIdx = validationIdx(end)+1 : length(shuffledIndices); testDataTbl = vehicleDataset(shuffledIndices(testIdx),:);
imageDatastore와 boxLabelDatastore를 사용하여 훈련과 평가 과정에서 영상 및 레이블 데이터를 불러오기 위한 데이터저장소를 만듭니다.
imdsTrain = imageDatastore(trainingDataTbl{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,"vehicle"));
imdsValidation = imageDatastore(validationDataTbl{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validationDataTbl(:,"vehicle"));
imdsTest = imageDatastore(testDataTbl{:,"imageFilename"});
bldsTest = boxLabelDatastore(testDataTbl(:,"vehicle"));영상 데이터저장소와 상자 레이블 데이터저장소를 결합합니다.
trainingData = combine(imdsTrain,bldsTrain); validationData = combine(imdsValidation,bldsValidation); testData = combine(imdsTest,bldsTest);
상자 레이블과 함께 훈련 영상 중 하나를 표시합니다.
data = read(trainingData);
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Faster R-CNN 검출 신경망 만들기
Faster R-CNN 객체 검출 신경망은 하나의 특징 추출 신경망과 그 뒤에 오는 2개의 하위 신경망으로 구성됩니다. 특징 추출 신경망은 일반적으로 ResNet-50, Inception v3과 같은 사전 훈련된 CNN입니다. 특징 추출 신경망 뒤에 오는 첫 번째 하위 신경망은 사물 제안(영상에서 사물이 존재할 가능성이 있는 영역)을 생성하도록 훈련된 영역 제안 신경망(RPN)입니다. 두 번째 하위 신경망은 각 사물 제안의 실제 클래스를 예측하도록 훈련됩니다.
특징 추출 신경망은 일반적으로 사전 훈련된 CNN입니다(자세한 내용은 사전 훈련된 심층 신경망 (Deep Learning Toolbox) 참조). 이 예제에서는 특징 추출에 ResNet-50을 사용합니다. 응용 사례의 요구 사항에 따라 MobileNet v2나 ResNet-18과 같은 여타 사전 훈련된 신경망도 사용할 수 있습니다.
fasterRCNNLayers를 사용하여, 사전 훈련된 특징 추출 신경망이 주어졌을 때 자동으로 Faster R-CNN 신경망을 만듭니다. fasterRCNNLayers를 사용할 때는 Faster R-CNN 신경망을 파라미터화하는 다음과 같은 몇 개의 입력값을 지정해야 합니다.
신경망 입력 크기
앵커 상자
특징 추출 신경망
먼저 신경망 입력 크기를 지정합니다. 신경망 입력 크기를 선택할 때는 신경망 자체를 실행하는 데 필요한 최소 크기, 훈련 영상의 크기, 그리고 선택한 크기에서 데이터를 처리할 때 발생하는 계산 비용을 고려해야 합니다. 가능하다면, 훈련 영상의 크기와 가깝고 신경망에서 요구되는 입력 크기보다 큰 신경망 입력 크기를 선택하십시오. 예제를 실행하는 데 소요되는 계산 비용을 줄이려면 신경망을 실행하는 데 필요한 최소 크기인 [224 224 3]으로 신경망 입력 크기를 지정하십시오.
inputSize = [224 224 3];
이 예제에서 사용되는 훈련 영상은 224×224보다 크고 크기가 다양하므로 훈련 전 전처리 단계에서 영상을 크기 조정해야 합니다.
다음으로, estimateAnchorBoxes를 사용하여 훈련 데이터의 사물 크기를 기반으로 앵커 상자를 추정합니다. 훈련 전 이루어지는 영상 크기 조정을 고려하기 위해 앵커 상자 추정에 사용하는 훈련 데이터를 크기 조정하십시오. transform을 사용하여 훈련 데이터를 전처리한 후에 앵커 상자의 개수를 정의하고 앵커 상자를 추정합니다.
preprocessedTrainingData = transform(trainingData, @(data)preprocessData(data,inputSize)); numAnchors = 3; anchorBoxes = estimateAnchorBoxes(preprocessedTrainingData,numAnchors)
anchorBoxes = 3×2
38 29
150 125
80 77
앵커 상자 선택에 관한 자세한 내용은 Estimate Anchor Boxes from Training Data(Computer Vision Toolbox™) 및 객체 검출용 앵커 상자 항목을 참조하십시오.
이제 resnet50을 사용하여 사전 훈련된 ResNet-50 모델을 불러옵니다.
featureExtractionNetwork = resnet50;
"activation_40_relu"를 특징 추출 계층으로 선택합니다. 이 특징 추출 계층은 16배만큼 다운샘플링된 특징 맵을 출력합니다. 이 정도의 다운샘플링은 공간 분해능과 추출된 특징의 강도 사이를 적절히 절충한 값입니다. 신경망의 더 아래쪽에서 추출된 특징은 더 강한 영상 특징을 인코딩하나 공간 분해능이 줄어들기 때문입니다. 최적의 특징 추출 계층을 선택하려면 경험적 분석이 필요합니다. analyzeNetwork를 사용하여 신경망 내에 있는 다른 잠재적 특징 추출 계층의 이름을 찾을 수 있습니다.
featureLayer = "activation_40_relu";검출할 클래스의 개수를 정의합니다.
numClasses = width(vehicleDataset)-1;
Faster R-CNN 객체 검출 신경망을 만듭니다.
lgraph = fasterRCNNLayers(inputSize,numClasses,anchorBoxes,featureExtractionNetwork,featureLayer);
analyzeNetwork 또는 Deep Learning Toolbox™의 심층 신경망 디자이너를 사용하여 신경망을 시각화할 수 있습니다.
Faster R-CNN 신경망 아키텍처를 더욱 세부적으로 제어해야 하는 경우에는 심층 신경망 디자이너를 사용하여 Faster R-CNN 검출 신경망을 직접 설계하십시오. 자세한 내용은 R-CNN, Fast R-CNN, Faster R-CNN 시작하기 항목을 참조하십시오.
데이터 증강
데이터 증강은 훈련 중에 원본 데이터를 무작위로 변환함으로써 신경망 정확도를 개선하는 데 사용됩니다. 데이터 증강을 사용하면 레이블이 지정된 훈련 샘플의 개수를 늘리지 않고도 훈련 데이터에 다양성을 더할 수 있습니다.
transform을 사용하여 영상과 영상에 해당하는 상자 레이블을 가로 방향으로 무작위로 뒤집어서 훈련 데이터를 증강합니다. 테스트 데이터와 검증 데이터에는 데이터 증강이 적용되지 않는다는 것에 유의하십시오. 이상적인 경우라면 테스트 데이터와 검증 데이터가 원본 데이터를 대표하므로 편향되지 않은 평가를 위해 수정되지 않은 상태로 남겨 두는 것이 좋습니다.
augmentedTrainingData = transform(trainingData,@augmentData);
동일한 영상을 여러 차례 읽어 들이고 증강된 훈련 데이터를 표시합니다.
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedTrainingData); augmentedData{k} = insertShape(data{1},"rectangle",data{2}); reset(augmentedTrainingData); end figure montage(augmentedData,BorderSize=10)

훈련 데이터 전처리하기
증강된 훈련 데이터와 검증 데이터를 전처리하여 훈련에 사용할 수 있도록 준비합니다.
trainingData = transform(augmentedTrainingData,@(data)preprocessData(data,inputSize)); validationData = transform(validationData,@(data)preprocessData(data,inputSize));
전처리된 데이터를 읽어 들입니다.
data = read(trainingData);
영상과 경계 상자를 표시합니다.
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Faster R-CNN 훈련시키기
trainingOptions를 사용하여 신경망 훈련 옵션을 지정합니다. "ValidationData"를 전처리된 검증 데이터로 설정합니다. "CheckpointPath"를 임시 위치로 설정합니다. 이렇게 하면 훈련 과정 도중에 부분적으로 훈련된 검출기를 저장할 수 있습니다. 정전이나 시스템 장애 등으로 인해 훈련이 중단될 경우, 저장된 검사 지점에서 훈련을 재개할 수 있습니다.
options = trainingOptions("sgdm",... MaxEpochs=10,... MiniBatchSize=2,... InitialLearnRate=1e-3,... CheckpointPath=tempdir,... ValidationData=validationData);
doTraining이 true인 경우, trainFasterRCNNObjectDetector를 사용하여 Faster R-CNN 객체 검출기를 훈련시킵니다. 그렇지 않은 경우에는 사전 훈련된 신경망을 불러옵니다.
if doTraining % Train the Faster R-CNN detector. % * Adjust NegativeOverlapRange and PositiveOverlapRange to ensure % that training samples tightly overlap with ground truth. [detector, info] = trainFasterRCNNObjectDetector(trainingData,lgraph,options, ... NegativeOverlapRange=[0 0.3], ... PositiveOverlapRange=[0.6 1]); else % Load pretrained detector for the example. pretrained = load("fasterRCNNResNet50EndToEndVehicleExample.mat"); detector = pretrained.detector; end
이 예제는 12GB의 메모리가 탑재된 Nvidia(TM) Titan X GPU에서 검증되었습니다. 신경망을 훈련시키는 데는 약 20분 정도가 소요되었습니다. 훈련 시간은 사용하는 하드웨어에 따라 달라집니다.
짧게 확인해 보려면 하나의 테스트 영상에 대해 검출기를 실행하십시오. 훈련 영상의 크기와 같게 영상을 크기 조정하는 것을 잊지 마십시오.
I = imread(testDataTbl.imageFilename{3});
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I);결과를 표시합니다.
I = insertObjectAnnotation(I,"rectangle",bboxes,scores);
figure
imshow(I)
테스트 세트를 사용하여 검출기 평가하기
훈련된 객체 검출기를 대규모 영상 세트를 대상으로 평가하여 성능을 측정합니다. Computer Vision Toolbox™에는 평균 정밀도, 로그-평균 미검출율과 같은 통상적인 메트릭을 측정해 주는 객체 검출기 평가 함수(evaluateObjectDetection)가 있습니다. 이 예제에서는 평균 정밀도를 메트릭으로 사용하여 성능을 평가합니다. 평균 정밀도는 검출기가 올바른 분류를 수행하는 능력(정밀도)과 모든 관련 사물을 찾는 능력(재현율)을 통합하여 하나의 수치로 나타냅니다.
훈련 데이터와 동일한 전처리 변환을 테스트 데이터에 적용합니다.
testData = transform(testData,@(data)preprocessData(data,inputSize));
모든 테스트 영상에 대해 검출기를 실행합니다. 가능한 한 많은 객체를 검출하려면 검출 임계값을 낮은 값으로 설정하십시오. 이렇게 하면 전체 재현율 값 범위에서 검출기 정밀도를 평가하는 데 도움이 됩니다.
detectionResults = detect(detector,testData,... Threshold=0.2,... MiniBatchSize=4);
메트릭으로 평균 정밀도를 사용하여 객체 검출기를 평가합니다.
metrics = evaluateObjectDetection(detectionResults,testData); [precision,recall] = precisionRecall(metrics,ClassName="vehicle"); AP = averagePrecision(metrics,ClassName="vehicle");
정밀도-재현율(PR) 곡선은 각기 다른 재현율 수준에서의 검출기의 정밀도를 나타냅니다. 이상적인 정밀도는 모든 재현율 수준에서 1입니다. 더 많은 데이터를 사용하면 평균 정밀도를 개선하는 데 도움이 될 수 있으나 더 많은 훈련 시간이 필요할 수 있습니다. PR 곡선을 플로팅합니다.
figure
plot(recall{:},precision{:})
xlabel("Recall")
ylabel("Precision")
grid on
title(sprintf("Average Precision = %.2f", AP))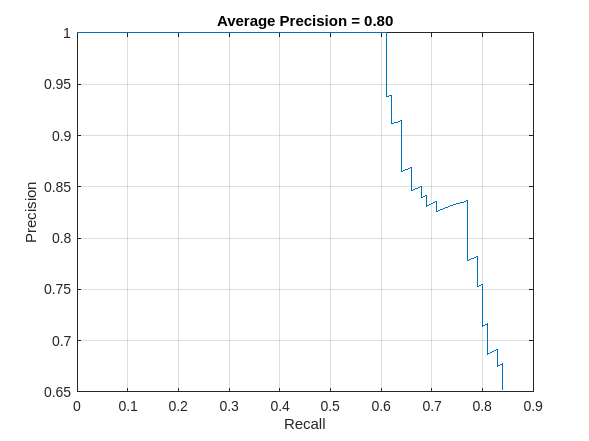
지원 함수
function data = augmentData(data) % Randomly flip images and bounding boxes horizontally. tform = randomAffine2d("XReflection",true); sz = size(data{1}); rout = affineOutputView(sz,tform); data{1} = imwarp(data{1},tform,"OutputView",rout); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to open this function. data{2} = helperSanitizeBoxes(data{2}); % Warp boxes. data{2} = bboxwarp(data{2},tform,rout); end function data = preprocessData(data,targetSize) % Resize image and bounding boxes to targetSize. sz = size(data{1},[1 2]); scale = targetSize(1:2)./sz; data{1} = imresize(data{1},targetSize(1:2)); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to open this function. data{2} = helperSanitizeBoxes(data{2}); % Resize boxes. data{2} = bboxresize(data{2},scale); end
참고 문헌
[1] Ren, S., K. He, R. Gershick, and J. Sun. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." IEEE Transactions of Pattern Analysis and Machine Intelligence. Vol. 39, Issue 6, June 2017, pp. 1137-1149.
[2] Girshick, R., J. Donahue, T. Darrell, and J. Malik. "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation." Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, June 2014, pp. 580-587.
[3] Girshick, R. "Fast R-CNN." Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile, Dec. 2015, pp. 1440-1448.
[4] Zitnick, C. L., and P. Dollar. "Edge Boxes: Locating Object Proposals from Edges." European Conference on Computer Vision. Zurich, Switzerland, Sept. 2014, pp. 391-405.
[5] Uijlings, J. R. R., K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders. "Selective Search for Object Recognition." International Journal of Computer Vision. Vol. 104, Number 2, Sept. 2013, pp. 154-171.
참고 항목
trainingOptions (Deep Learning Toolbox) | fasterRCNNObjectDetector | trainFasterRCNNObjectDetector | detect | insertObjectAnnotation | evaluateObjectDetection
도움말 항목
- 딥러닝을 사용한 객체 검출 시작하기
- Choose an Object Detector
- R-CNN 딥러닝을 사용하여 객체 검출기 훈련시키기
- MATLAB의 딥러닝 (Deep Learning Toolbox)