이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
tsne
t-분포 확률적 이웃 임베딩
설명
예제
피셔의 붓꽃 데이터 세트는 붓꽃에 대한 4차원 측정값과 이에 대응되는 종 분류를 포함하고 있습니다. tsne를 사용해 차원을 줄여 이 데이터를 시각화합니다.
load fisheriris rng default % for reproducibility Y = tsne(meas); gscatter(Y(:,1),Y(:,2),species)
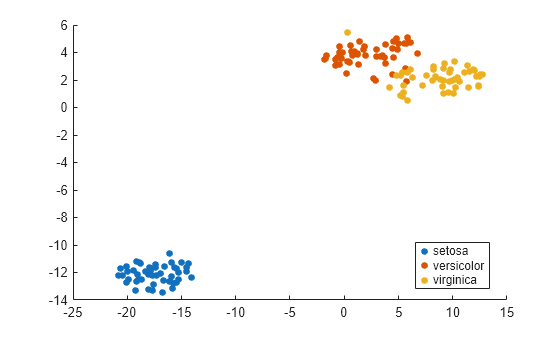
피셔의 붓꽃 데이터에서 종을 더 효과적으로 구분하려면 다양한 거리 측정법을 사용합니다.
load fisheriris rng('default') % for reproducibility Y = tsne(meas,'Algorithm','exact','Distance','mahalanobis'); subplot(2,2,1) gscatter(Y(:,1),Y(:,2),species) title('Mahalanobis') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','cosine'); subplot(2,2,2) gscatter(Y(:,1),Y(:,2),species) title('Cosine') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','chebychev'); subplot(2,2,3) gscatter(Y(:,1),Y(:,2),species) title('Chebychev') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','euclidean'); subplot(2,2,4) gscatter(Y(:,1),Y(:,2),species) title('Euclidean')

이 경우 코사인 거리 측정법, 체비쇼프 거리 측정법, 유클리드 거리 측정법은 군집을 상당히 잘 구분합니다. 그러나 마할라노비스 거리 측정법은 군집을 잘 구분하지 못합니다.
tsne는 NaN 요소를 포함하는 입력 데이터 행을 제거합니다. 따라서 플로팅하기 전에 사용자가 분류 데이터에서 이러한 행을 제거해야 합니다.
예를 들어 피셔의 붓꽃 데이터에 있는 몇 개의 임의 요소를 NaN으로 변경합니다.
load fisheriris rng default % for reproducibility meas(rand(size(meas)) < 0.05) = NaN;
tsne를 사용하여 4차원 데이터를 2차원에 임베딩합니다.
Y = tsne(meas,'Algorithm','exact');
Warning: Rows with NaN missing values in X or 'InitialY' values are removed.
임베딩에서 제거된 행의 개수를 파악합니다.
length(species)-length(Y)
ans = 22
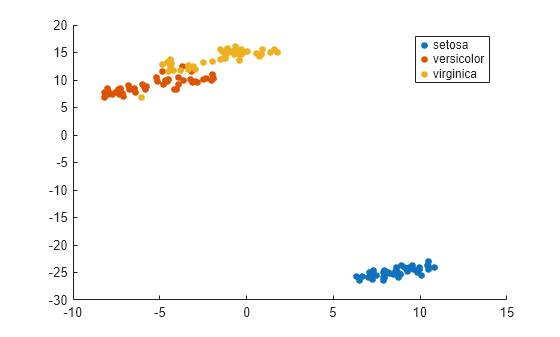
NaN 값을 가지지 않은 meas의 행을 찾아서 결과를 플로팅할 준비를 합니다.
goodrows = not(any(isnan(meas),2));
NaN 값이 없는 meas의 행에 대응하는 species의 행만 사용하여 결과를 플로팅합니다.
gscatter(Y(:,1),Y(:,2),species(goodrows))
피셔의 붓꽃 데이터의 2차원 임베딩과 3차원 임베딩을 모두 구하여 각 임베딩에 대한 손실을 비교합니다. 3차원 임베딩은 원래 데이터와 일치할 수 있는 자유도가 더 높기 때문에 손실이 낮을 가능성이 많습니다.
load fisheriris rng default % for reproducibility [Y,loss] = tsne(meas,'Algorithm','exact'); rng default % for fair comparison [Y2,loss2] = tsne(meas,'Algorithm','exact','NumDimensions',3); fprintf('2-D embedding has loss %g, and 3-D embedding has loss %g.\n',loss,loss2)
2-D embedding has loss 0.124191, and 3-D embedding has loss 0.0990884.
예상대로 3차원 임베딩의 경우 손실이 낮습니다.
임베딩을 표시합니다. RGB 색([1 0 0], [0 1 0], [0 0 1])을 사용합니다.
3차원 플롯의 경우, categorical 명령을 사용하여 종을 숫자형 값으로 변환한 후 다음과 같이 sparse 함수를 사용해 숫자형 값을 RGB 색으로 변환합니다. v가 종 데이터에 대응하는 양의 정수 1, 2 또는 3으로 구성된 벡터인 경우 명령은 다음과 같습니다.
sparse(1:numel(v),v,ones(size(v)))
위 명령은 희소 행렬이며, 이 행렬의 행은 종의 RGB 색입니다.
gscatter(Y(:,1),Y(:,2),species,eye(3))
title('2-D Embedding')
figure v = double(categorical(species)); c = full(sparse(1:numel(v),v,ones(size(v)),numel(v),3)); scatter3(Y2(:,1),Y2(:,2),Y2(:,3),15,c,'filled') title('3-D Embedding') view(-50,8)
