predict
Predict labels using k-nearest neighbor classification model
Description
label = predict(mdl,X)X, based on the trained k-nearest
neighbor classification model mdl. See Predicted Class Label.
[
also returns:label,score,cost]
= predict(mdl,X)
A matrix of classification scores (
score) indicating the likelihood that a label comes from a particular class. For k-nearest neighbor, scores are posterior probabilities. See Posterior Probability.A matrix of expected classification cost (
cost). For each observation inX, the predicted class label corresponds to the minimum expected classification costs among all classes. See Expected Cost.
Examples
Create a k-nearest neighbor classifier for Fisher's iris data, where k = 5. Evaluate some model predictions on new data.
Load the Fisher iris data set.
load fisheriris
X = meas;
Y = species;Create a classifier for five nearest neighbors. Standardize the noncategorical predictor data.
mdl = fitcknn(X,Y,'NumNeighbors',5,'Standardize',1);
Predict the classifications for flowers with minimum, mean, and maximum characteristics.
Xnew = [min(X);mean(X);max(X)]; [label,score,cost] = predict(mdl,Xnew)
label = 3×1 cell
{'versicolor'}
{'versicolor'}
{'virginica' }
score = 3×3
0.4000 0.6000 0
0 1.0000 0
0 0 1.0000
cost = 3×3
0.6000 0.4000 1.0000
1.0000 0 1.0000
1.0000 1.0000 0
The second and third rows of the score and cost matrices have binary values, which means all five nearest neighbors of the mean and maximum flower measurements have identical classifications.
Train k-nearest neighbor classifiers for various k values, and compare the decision boundaries of the classifiers.
Load the fisheriris data set.
load fisheririsThe data set contains length and width measurements from the sepals and petals of three species of iris flowers. Remove the sepal lengths and widths, and all observed setosa irises.
inds = ~strcmp(species,'setosa');
X = meas(inds,3:4);
species = species(inds); Create a binary label variable y. The label is 1 for a virginica iris and 0 for versicolor.
y = strcmp(species,'virginica');Train the k-nearest neighbor classifier. Specify 5 as the number of nearest neighbors to find, and standardize the predictor data.
EstMdl = fitcknn(X,y,'NumNeighbors',5,'Standardize',1)
EstMdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [0 1]
ScoreTransform: 'none'
NumObservations: 100
Distance: 'euclidean'
NumNeighbors: 5
Properties, Methods
EstMdl is a trained ClassificationKNN classifier. Some of its properties appear in the Command Window.
Plot the decision boundary, which is the line that distinguishes between the two iris species based on their features.
x1 = min(X(:,1)):0.01:max(X(:,1)); x2 = min(X(:,2)):0.01:max(X(:,2)); [x1G,x2G] = meshgrid(x1,x2); XGrid = [x1G(:),x2G(:)]; pred = predict(EstMdl,XGrid); figure gscatter(XGrid(:,1),XGrid(:,2),pred,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 5-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off

The partition between the red and blue regions is the decision boundary. If you change the number of neighbors k, then the boundary changes.
Retrain the classifier using k = 1 (default value for NumNeighbors of fitcknn) and k = 20.
EstMdl1 = fitcknn(X,y); pred1 = predict(EstMdl1,XGrid); EstMdl20 = fitcknn(X,y,'NumNeighbors',20); pred20 = predict(EstMdl20,XGrid); figure gscatter(XGrid(:,1),XGrid(:,2),pred1,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 1-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off
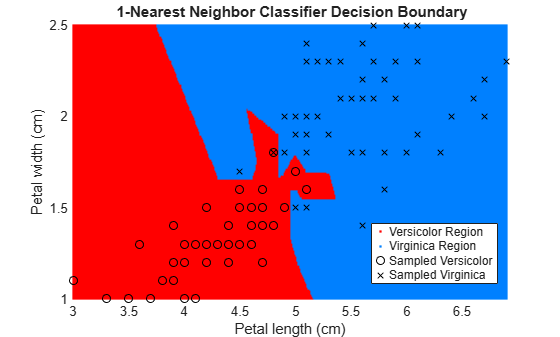
figure gscatter(XGrid(:,1),XGrid(:,2),pred20,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 20-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off
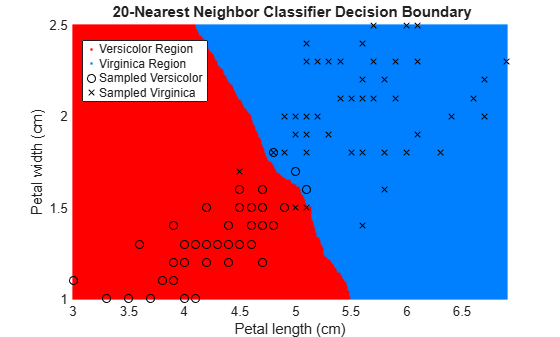
The decision boundary seems to linearize as k increases. This linearization happens because the algorithm down-weights the importance of each input with increasing k. When k = 1, the algorithm correctly predicts the species of almost all training samples. When k = 20, the algorithm has a higher misclassification rate within the training set. You can find an optimal value of k by using the OptimizeHyperparameters name-value argument of fitcknn. For an example, see Optimize KNN Classifier.
Input Arguments
Output Arguments
Algorithms
Alternative Functionality
Simulink Block
To integrate the prediction of a nearest neighbor classification model into
Simulink®, you can use the ClassificationKNN
Predict block in the Statistics and Machine Learning Toolbox™ library or a MATLAB® Function block with the predict function. For
examples, see Predict Class Labels Using ClassificationKNN Predict Block and Predict Class Labels Using MATLAB Function Block.
When deciding which approach to use, consider the following:
If you use the Statistics and Machine Learning Toolbox library block, you can use the Fixed-Point Tool (Fixed-Point Designer) to convert a floating-point model to fixed point.
Support for variable-size arrays must be enabled for a MATLAB Function block with the
predictfunction.If you use a MATLAB Function block, you can use MATLAB functions for preprocessing or post-processing before or after predictions in the same MATLAB Function block.
Extended Capabilities
Version History
Introduced in R2012a