bootstrp
부트스트랩 추출
구문
설명
bootstat = bootstrp(___,Name,Value)
예제
부트스트랩 평균의 커널 밀도를 추정합니다.
평균이 5인 지수 분포에서 100개의 난수를 생성합니다.
rng('default') % For reproducibility y = exprnd(5,100,1);
벡터 y에서 가져온 임의 표본에 대한 100개의 부트스트랩 표본의 평균을 계산합니다.
m = bootstrp(100,@mean,y);
부트스트랩 평균의 밀도에 대한 추정값을 플로팅합니다.
[fi,xi] = ksdensity(m); plot(xi,fi)
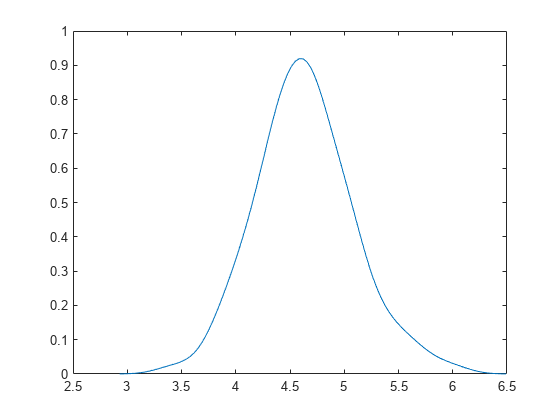
100개의 부트스트랩 표본의 평균과 표준편차를 계산하고 플로팅합니다.
평균이 5인 지수 분포에서 100개의 난수를 생성합니다.
rng('default') % For reproducibility y = exprnd(5,100,1);
벡터 y에서 가져온 임의 표본에 대한 100개의 부트스트랩 표본의 평균과 표준편차를 계산합니다.
stats = bootstrp(100,@(x)[mean(x) std(x)],y);
부트스트랩 추정값 쌍을 플로팅합니다.
plot(stats(:,1),stats(:,2),'o') xlabel('Mean') ylabel('Standard Deviation')

환자 데이터의 부트스트랩 표본을 가져오고 각 데이터 표본에 대한 평균 측정값을 계산한 후 결과를 시각화합니다.
patients 데이터 세트를 불러옵니다. 연령, 체중, 신장 측정값을 포함하는 행렬 patientData를 만듭니다. patientData의 각 행은 한 명의 환자에 대응됩니다.
load patients
patientData = [Age Weight Height];patientData의 데이터에서 200개의 부트스트랩 데이터 표본을 생성합니다. 각 표본을 생성하기 위해 patientData의 100개 행(size(patientData,1))에서 무작위 복원추출 방식으로 행을 선택합니다. 각 표본에 대해, 평균 연령, 체중 및 신장 측정값을 계산합니다. bootstat의 각 행은 하나의 부트스트랩 표본에 대해 세 개의 평균 측정값을 포함합니다.
rng('default') % For reproducibility bootstat = bootstrp(200,@mean,patientData);
모든 200개 부트스트랩 데이터 표본에 대해 평균 측정값을 시각화합니다. 평균 체중 측정값이 큰 부트스트랩 표본은 평균 신장 측정값도 큰 경향이 있습니다.
scatter3(bootstat(:,1),bootstat(:,2),bootstat(:,3)) xlabel('Mean Age') ylabel('Mean Weight') zlabel('Mean Height') view([-75 10])

표본 데이터의 부트스트랩 재추출을 사용하여 상관 계수 표준 오차를 계산합니다.
학생 15명의 LSAT 점수와 로스쿨 GPA가 포함된 lawdata 데이터 세트를 불러옵니다.
load lawdata rng('default') % For reproducibility size(lsat)
ans = 1×2
15 1
size(gpa)
ans = 1×2
15 1
15개의 데이터 점을 재추출하여 1000개의 데이터 표본을 만들고, 각 데이터 표본에 대해 두 변수 사이의 상관관계를 계산합니다.
[bootstat,bootsam] = bootstrp(1000,@corr,lsat,gpa);
처음 5개의 부트스트랩 상관 계수를 표시합니다.
bootstat(1:5,:)
ans = 5×1
0.9874
0.4918
0.5459
0.8458
0.8959
처음 5개의 부트스트랩 표본에 대해 선택된 데이터의 인덱스를 표시합니다.
bootsam(:,1:5)
ans = 15×5
13 3 11 8 12
14 7 1 7 4
2 14 5 10 8
14 12 1 11 11
10 15 2 12 14
2 10 13 5 15
5 1 11 11 9
9 13 5 10 3
15 15 15 3 3
15 11 1 2 4
3 12 7 8 13
15 12 6 15 4
15 6 12 6 13
8 10 12 9 4
13 3 3 4 14
모든 부트스트랩 표본의 상관 계수 변동을 보여주는 히스토그램을 만듭니다.
histogram(bootstat)

표본 최솟값은 양수입니다. 이는 LSAT 점수와 GPA 사이의 관계가 우연이 아님을 나타냅니다.
마지막으로, 추정된 상관 계수에 대한 부트스트랩 표준 오차를 계산합니다.
se = std(bootstat)
se = 0.1285
부트스트랩 표본을 다양한 관측값 가중치와 비교합니다. 각 표본에 대한 통계량을 계산하는 사용자 지정 함수를 만듭니다.
숫자 1부터 6 사이에서 50개 부트스트랩 표본을 생성합니다. 각 표본을 생성하기 위해 bootstrp는 숫자 1부터 6 사이에서 무작위 복원추출 방식으로 6번 선택합니다. 이 과정은 주사위를 6번 굴리는 것과 유사합니다. 각 표본에 대해 (이 예제의 끝부분에 나와 있는) 사용자 지정 함수 countfun은 표본에서 1의 개수를 셉니다.
rng('default') %For reproducibility counts = bootstrp(50,@countfun,(1:6)');
참고: 이 예제에 라이브 스크립트 파일을 사용하는 경우, countfun 함수가 파일의 끝에 이미 포함되어 있습니다. 그렇지 않은 경우, .m 파일의 끝에 이 함수를 만들거나 MATLAB® 경로에 이 함수를 파일로 추가해야 합니다.
숫자 1부터 6 사이에서 50개 부트스트랩 표본을 만들되, 이들 숫자에 서로 다른 가중치를 할당합니다. bootstrp이 숫자 1부터 6 사이에서 무작위로 선택할 때마다 1을 선택할 확률은 0.5이고, 2를 선택할 확률은 0.1인 식입니다. countfun은 각 표본에서 1의 개수를 셉니다.
weights = [0.5 0.1 0.1 0.1 0.1 0.1]';
weightedCounts = bootstrp(50,@countfun,(1:6)','Weights',weights);히스토그램을 사용하여 두 세트의 부트스트랩 표본을 비교합니다.
histogram(counts) hold on histogram(weightedCounts) legend xlabel('Number of 1s in Sample') ylabel('Number of Samples') hold off
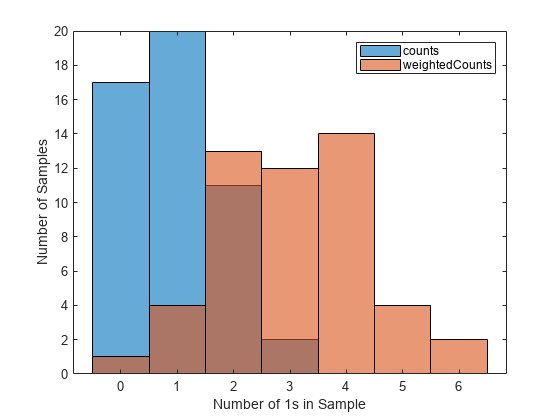
두 세트의 부트스트랩 표본은 서로 다른 분포를 갖는데, 특히 두 번째 세트에 1이 더 많이 포함되는 경향이 있습니다. 예를 들어, 첫 번째 세트의 50개 표본 중에는 두 개의 표본에만 세 개 이상의 1이 포함되어 있습니다. 이와 반대로, 두 번째 세트의 50개 표본(관측값 가중치 사용) 중에는 개 표본에 세 개 이상의 1이 포함되어 있습니다.
다음 코드는 함수 countfun을 생성합니다.
function numberofones = countfun(sample) numberofones = sum(sample == 1); end
잔차에 부트스트랩을 적용하여 선형 회귀에서 계수 벡터에 대한 표준 오차를 추정합니다.
참고: 이 예제에서는 부트스트랩의 경우처럼 단순히 회귀 모델의 계수 추정값 또는 잔차가 필요하고 모델을 여러 차례 반복해서 피팅해야 하는 경우에 유용한 regress를 사용합니다. 피팅된 회귀 모델을 추가로 조사하려면 fitlm을 사용하여 선형 회귀 모델 객체를 생성하십시오.
표본 데이터를 불러옵니다.
load hald선형 회귀를 수행하고 잔차를 계산합니다.
x = [ones(size(heat)),ingredients]; y = heat; b = regress(y,x); yfit = x*b; resid = y - yfit;
잔차에 부트스트랩을 적용하여 표준 오차를 추정합니다.
se = std(bootstrp(1000,@(bootr)regress(yfit+bootr,x),resid))
se = 1×5
56.1752 0.5940 0.5815 0.5989 0.5691
입력 인수
이름-값 인수
출력 인수
확장 기능
버전 내역
R2006a 이전에 개발됨
참고 항목
histogram | bootci | ksdensity | parfor | random | randsample | RandStream | statget | statset