이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
컨벌루션 신경망을 사용한 잔여 수명 추정
이 예제에서는 심층 컨벌루션 신경망(CNN)을 사용하여 엔진의 잔여 수명(RUL)을 예측하는 방법을 보여줍니다[1]. 딥러닝 접근 방식의 장점은 모델에서 RUL을 예측하기 위해 수동으로 특징을 추출하거나 선택할 필요가 없다는 것입니다. 또한 딥러닝 기반 RUL 예측 모델을 개발하기 위해 기계 건전성 예지진단 또는 신호 처리에 대한 사전 지식이 필요하지 않습니다.
데이터 세트 다운로드하기
이 예제에서는 터보팬 엔진 성능 저하 시뮬레이션 데이터 세트를 사용합니다[1]. 데이터 세트는 ZIP 파일 형식으로, 작동 상태와 결함 모드의 다양한 조합에서 시뮬레이션된 4가지의 서로 다른 세트(FD001, FD002, FD003, FD004)에 대한 RTF(run-to-failure) 시계열 데이터가 포함되어 있습니다.
이 예제는 FD001 데이터 세트만 사용하며, 이 데이터 세트를 다시 훈련 서브셋과 테스트 서브셋으로 나눕니다. 훈련 서브셋에는 100개의 엔진에 대해 시뮬레이션된 시계열 데이터가 포함되어 있습니다. 각 엔진은 여러 개의 센서를 가지며, 이 센서들의 값은 연속적인 공정의 특정 시점들에 기록됩니다. 따라서 기록된 데이터의 시퀀스는 길이가 각각 다르며 각 시퀀스가 하나의 전체 RTF(run-to-failure) 인스턴스에 해당합니다. 테스트 서브셋에는 100개의 부분 시퀀스가 있고 각 시퀀스 끝의 잔여 수명에 해당하는 값이 포함되어 있습니다.
터보팬 엔진 성능 저하 시뮬레이션 데이터 세트를 저장할 디렉터리를 만듭니다.
dataFolder = "data"; if ~exist(dataFolder,'dir') mkdir(dataFolder); end
터보팬 엔진 성능 저하 시뮬레이션 데이터 세트를 다운로드하고 압축을 풉니다.
filename = matlab.internal.examples.downloadSupportFile("nnet","data/TurbofanEngineDegradationSimulationData.zip"); unzip(filename,dataFolder)
이제 데이터 폴더에는 공백으로 구분된 26개의 숫자 열이 포함된 텍스트 파일이 들어 있습니다. 각 행은 1회의 작동 사이클 동안 찍힌 데이터의 스냅샷이며, 각 열은 다음과 같이 서로 다른 변수를 나타냅니다.
열 1 — 단위 번호
열 2 — 타임스탬프
열 3~5 — 작동 설정
열 6~26 — 센서 측정값 1~21
훈련 데이터 전처리하기
localLoadData 함수를 사용하여 데이터를 불러옵니다. 이 함수는 데이터 파일에서 데이터를 추출하고, 훈련 예측 변수와 대응하는 응답 변수(즉, RUL) 시퀀스가 포함된 테이블을 반환합니다. 각 행은 서로 다른 엔진을 나타냅니다.
filenameTrainPredictors = fullfile(dataFolder,"train_FD001.txt");
rawTrain = localLoadData(filenameTrainPredictors);한 엔진의 RTF(run-to-failure) 데이터를 검토합니다.
head(rawTrain.X{1},8) id timeStamp op_setting_1 op_setting_2 op_setting_3 sensor_1 sensor_2 sensor_3 sensor_4 sensor_5 sensor_6 sensor_7 sensor_8 sensor_9 sensor_10 sensor_11 sensor_12 sensor_13 sensor_14 sensor_15 sensor_16 sensor_17 sensor_18 sensor_19 sensor_20 sensor_21
__ _________ ____________ ____________ ____________ ________ ________ ________ ________ ________ ________ ________ ________ ________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________
1 1 -0.0007 -0.0004 100 518.67 641.82 1589.7 1400.6 14.62 21.61 554.36 2388.1 9046.2 1.3 47.47 521.66 2388 8138.6 8.4195 0.03 392 2388 100 39.06 23.419
1 2 0.0019 -0.0003 100 518.67 642.15 1591.8 1403.1 14.62 21.61 553.75 2388 9044.1 1.3 47.49 522.28 2388.1 8131.5 8.4318 0.03 392 2388 100 39 23.424
1 3 -0.0043 0.0003 100 518.67 642.35 1588 1404.2 14.62 21.61 554.26 2388.1 9052.9 1.3 47.27 522.42 2388 8133.2 8.4178 0.03 390 2388 100 38.95 23.344
1 4 0.0007 0 100 518.67 642.35 1582.8 1401.9 14.62 21.61 554.45 2388.1 9049.5 1.3 47.13 522.86 2388.1 8133.8 8.3682 0.03 392 2388 100 38.88 23.374
1 5 -0.0019 -0.0002 100 518.67 642.37 1582.8 1406.2 14.62 21.61 554 2388.1 9055.1 1.3 47.28 522.19 2388 8133.8 8.4294 0.03 393 2388 100 38.9 23.404
1 6 -0.0043 -0.0001 100 518.67 642.1 1584.5 1398.4 14.62 21.61 554.67 2388 9049.7 1.3 47.16 521.68 2388 8132.9 8.4108 0.03 391 2388 100 38.98 23.367
1 7 0.001 0.0001 100 518.67 642.48 1592.3 1397.8 14.62 21.61 554.34 2388 9059.1 1.3 47.36 522.32 2388 8132.3 8.3974 0.03 392 2388 100 39.1 23.377
1 8 -0.0034 0.0003 100 518.67 642.56 1583 1401 14.62 21.61 553.85 2388 9040.8 1.3 47.24 522.47 2388 8131.1 8.4076 0.03 391 2388 100 38.97 23.311
한 엔진의 응답 변수 데이터를 검토합니다.
rawTrain.Y{1}(1:8)ans = 8×1
191
190
189
188
187
186
185
184
일부 예측 변수에 대한 시계열 데이터를 시각화합니다.
stackedplot(rawTrain.X{1},[3,5,6,7,8,15,16,24],XVariable='timeStamp')
변동성이 적은 특징 제거하기
모든 시간 스텝에서 일정하게 유지되는 특징은 훈련에 부정적인 영향을 줄 수 있습니다. prognosability 함수를 사용하여 고장 시 특징의 변동성을 측정합니다.
prog = prognosability(rawTrain.X,"timeStamp");일부 특징의 경우 예지진단 특성이 0 또는 NaN입니다. 이러한 특징을 삭제합니다.
idxToRemove = prog.Variables==0 | isnan(prog.Variables); featToRetain = prog.Properties.VariableNames(~idxToRemove); for i = 1:height(rawTrain) rawTrain.X{i} = rawTrain.X{i}{:,featToRetain}; end
훈련 예측 변수 정규화하기
평균과 단위 분산이 0이 되도록 훈련 예측 변수를 정규화합니다.
[~,Xmu,Xsigma] = zscore(vertcat(rawTrain.X{:}));
preTrain = table();
for i = 1:numel(rawTrain.X)
preTrain.X{i} = (rawTrain.X{i} - Xmu) ./ Xsigma;
end응답 변수 자르기
응답 변수 데이터는 각 엔진의 수명에 따른 RUL 값을 나타내며 개별 엔진 수명을 기반으로 합니다. 이 시퀀스는 초기 측정 시점부터 엔진 고장 시점까지 선형적인 성능 저하를 나타낸다고 가정합니다.
신경망이 엔진이 고장날(엔진 수명 종료) 가능성이 더 높은 지점의 데이터 부분에 초점을 두도록 하기 위해 임계값 150에서 응답 변수를 자릅니다. 응답 변수를 자르면 신경망은 RUL 값이 더 높은 인스턴스를 동일한 인스턴스로 취급합니다.
rulThreshold = 150; for i = 1:numel(rawTrain.Y) preTrain.Y{i} = min(rawTrain.Y{i},rulThreshold); end
다음 그림은 첫 번째 관측값과 이에 대응하는 응답 변수(RUL)를 보여줍니다. RUL은 임계값에서 잘려 있습니다. 녹색 오버레이 부분은 센서 플롯과 RUL 플롯에서 잘린 영역을 정의합니다.

채우기를 위해 데이터 준비하기
이 신경망은 시퀀스 길이가 다양한 입력 데이터를 지원합니다. 신경망을 통해 데이터를 전달할 때, 각 미니 배치의 모든 시퀀스가 지정된 길이를 갖도록 시퀀스가 채워지거나 잘리거나 분할됩니다.
미니 배치에 추가되는 채우기의 양을 최소화하기 위해 시퀀스 길이를 기준으로 훈련 데이터를 정렬합니다. 그런 다음 훈련 데이터를 균등하게 나누고 미니 배치의 채우기 양을 줄이는 미니 배치 크기를 선택합니다.
시퀀스 길이를 기준으로 훈련 데이터를 정렬합니다.
for i = 1:size(preTrain,1) preTrain.X{i} = preTrain.X{i}'; %Transpose training data to have features in the first dimension preTrain.Y{i} = preTrain.Y{i}'; %Transpose responses corresponding to the training data sequence = preTrain.X{i}; sequenceLengths(i) = size(sequence,2); end [sequenceLengths,idx] = sort(sequenceLengths,'descend'); XTrain = preTrain.X(idx); YTrain = preTrain.Y(idx);
신경망 아키텍처
RUL 추정에 사용되는 심층 컨벌루션 신경망 아키텍처는 [1]에 설명되어 있습니다.
여기서는 데이터를 시퀀스 형식으로 처리하고 정렬합니다. 첫 번째 차원은 선택한 특징의 개수를 나타내고 두 번째 차원은 시간 시퀀스의 길이를 나타냅니다. 컨벌루션 계층, 배치 정규화 계층, 활성화 계층(이 경우 relu)을 이 순서대로 하나의 묶음으로 만들고, 특징 추출을 위해 이들 계층을 스택으로 쌓습니다. 완전 연결 계층을 마지막에 사용하여 최종 RUL 값을 출력값으로 구합니다.
이렇게 선택된 신경망의 아키텍처는 오직 시간 시퀀스 방향을 따라서 1차원 컨벌루션을 적용합니다. 따라서 특징의 순서가 훈련에 영향을 주지 않으며 한 번에 한 가지 특징의 추세만 고려됩니다.
신경망 아키텍처를 정의합니다. 여기서 만드는 CNN은 컨벌루션 1차원 계층, 배치 정규화 계층, relu 계층으로 이루어진 묶음이 연속해서 5개 세트로 배치되도록 하며, 이때 convolution1dLayer의 처음 두 입력 인수는 증가하는 filterSize 및 numFilters로 지정합니다. 이 뒤에 크기가 numHiddenUnits인 완전 연결 계층이 오고 드롭아웃 확률이 0.5인 드롭아웃 계층이 오도록 구성합니다. 신경망이 터보팬 엔진의 RUL(잔여 수명)을 예측하므로 두 번째 완전 연결 계층에서 numResponses를 1로 설정합니다.
훈련 데이터의 가변 시간 시퀀스를 보정하기 위해 convolution1dLayer에 이름-값 쌍 입력 인수로 Padding="causal"을 사용합니다.
numFeatures = size(XTrain{1},1);
numHiddenUnits = 100;
numResponses = 1;
layers = [
sequenceInputLayer(numFeatures)
convolution1dLayer(5,32,Padding="causal")
batchNormalizationLayer
reluLayer()
convolution1dLayer(7,64,Padding="causal")
batchNormalizationLayer
reluLayer()
convolution1dLayer(11,128,Padding="causal")
batchNormalizationLayer
reluLayer()
convolution1dLayer(13,256,Padding="causal")
batchNormalizationLayer
reluLayer()
convolution1dLayer(15,512,Padding="causal")
batchNormalizationLayer
reluLayer()
fullyConnectedLayer(numHiddenUnits)
reluLayer()
dropoutLayer(0.5)
fullyConnectedLayer(numResponses)];신경망 훈련시키기
trainingOptions (Deep Learning Toolbox)를 지정합니다. Adam 최적화 함수를 사용하여 크기가 16인 미니 배치로 Epoch 40회 동안 훈련시킵니다. LearnRateSchedule을 piecewise로 설정합니다. 학습률을 0.01로 지정합니다. 기울기가 한없이 증가하지 않도록 하려면 기울기 임계값을 1로 설정하십시오. 길이별로 정렬된 시퀀스를 그대로 유지하기 위해 'Shuffle'을 'never'로 설정합니다. 훈련 진행 상황 플롯을 켜고 Metrics를 'rmse'로 설정하여 RMSE 플롯을 표시합니다. 훈련 데이터는 첫 번째 차원에 특징이, 두 번째 차원에 시계열 시퀀스가, 세 번째 차원에 데이터 배치가 들어 있으므로 InputDataFormats을 CTB로 설정합니다. 명령 창 출력(Verbose)을 끕니다.
maxEpochs = 40; miniBatchSize = 16; options = trainingOptions('adam',... LearnRateSchedule='piecewise',... MaxEpochs=maxEpochs,... MiniBatchSize=miniBatchSize,... InitialLearnRate=0.01,... GradientThreshold=1,... Shuffle='never',... Plots='training-progress',... Metrics='rmse',... InputDataFormats='CTB',... Verbose=0);
trainnet 을 사용하여 신경망을 훈련시키고 손실 함수를 MSE(평균제곱오차)로 지정합니다. 1~2분 정도 소요됩니다.
net = trainnet(XTrain,YTrain,layers,"mse",options);
신경망의 계층 그래프를 플로팅하여 기본 신경망 아키텍처를 시각화합니다.
figure; plot(net)

신경망 테스트하기
테스트 데이터에는 100개의 부분 시퀀스가 있고 각 시퀀스 끝의 잔여 수명에 해당하는 값이 포함되어 있습니다.
filenameTestPredictors = fullfile(dataFolder,'test_FD001.txt'); filenameTestResponses = fullfile(dataFolder,'RUL_FD001.txt'); dataTest = localLoadData(filenameTestPredictors,filenameTestResponses);
훈련 데이터 세트를 준비했을 때와 동일한 전처리 단계를 수행하여 예측에 사용할 테스트 데이터 세트를 준비합니다.
for i = 1:numel(dataTest.X) dataTest.X{i} = dataTest.X{i}{:,featToRetain}; dataTest.X{i} = (dataTest.X{i} - Xmu) ./ Xsigma; dataTest.Y{i} = min(dataTest.Y{i},rulThreshold); end
예측된 응답 변수(YPred)를 실제 응답 변수(Y)와 함께 저장할 테이블을 만듭니다. minibatchpredict를 사용하여 테스트 데이터에 대해 예측을 수행합니다. 함수가 테스트 데이터에 채우기를 추가하지 않도록 하기 위해 미니 배치 크기를 1로 지정하여 테스트 데이터의 각 관측값의 RUL 값을 구합니다. 테스트 데이터도 훈련 데이터와 동일한 형식이므로 InputDataFormats를 CTB로 설정합니다.
predictions = table(Size=[height(dataTest) 2],VariableTypes=["cell","cell"],VariableNames=["Y","YPred"]); for i=1:height(dataTest) unit = dataTest.X{i}'; predictions.Y{i} = dataTest.Y{i}'; predictions.YPred{i} = minibatchpredict(net,unit,MiniBatchSize=1,InputDataFormats='CTB'); end
성능 메트릭
테스트 시퀀스의 모든 시간 사이클에 걸쳐 RMSE(RMS 오차)를 계산하여 신경망이 테스트 데이터에 대해 얼마나 잘 작동하는지 분석합니다.
for i = 1:size(predictions,1) predictions.RMSE(i) = sqrt(mean((predictions.Y{i} - predictions.YPred{i}).^2)); end
히스토그램을 생성하여 모든 테스트 엔진에서 RMSE 값의 분포를 시각화합니다.
figure; histogram(predictions.RMSE,NumBins=10); title("RMSE ( Mean: " + round(mean(predictions.RMSE),2) + " , StDev: " + round(std(predictions.RMSE),2) + " )"); ylabel('Frequency'); xlabel('RMSE');

또한 테스트 엔진에서 신경망의 예측이 데이터의 전체 시퀀스에서 얼마나 잘 작동하는지 확인하기 위해, localLambdaPlot 함수를 사용하여 임의의 테스트 엔진에서 예측된 RUL을 실제 RUL과 대조하여 플로팅합니다.
figure;
localLambdaPlot(predictions,"random");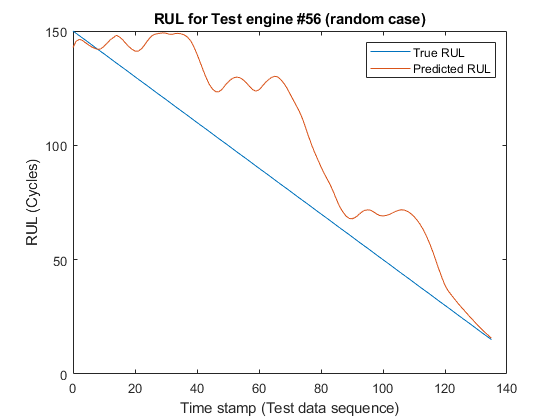
이 결과는 터보 엔진 데이터의 RUL을 추정하는 CNN 딥러닝 아키텍처가 RUL을 예측하는 데 유효한 접근 방식임을 보여줍니다. 전체 타임스탬프에서의 RMSE 값들은 이 신경망이 테스트 시퀀스 데이터의 끝에 가까워질수록 잘 작동함을 나타냅니다. 따라서 RUL을 예측할 때는 센서 데이터의 짧은 이력을 가지고 있는 것이 중요합니다.
헬퍼 함수
데이터 불러오기 함수
이 함수는 제공된 텍스트 파일에서 RTF(run-to-failure) 데이터를 불러오고, 시계열 데이터 및 이에 대응하는 RUL 값을 예측 변수와 응답 변수로 테이블에 그룹화합니다.
function data = localLoadData(filenamePredictors,varargin) if isempty(varargin) filenameResponses = []; else filenameResponses = varargin{:}; end %% Load the text file as a table rawData = readtable(filenamePredictors); % Add variable names to the table VarNames = {... 'id', 'timeStamp', 'op_setting_1', 'op_setting_2', 'op_setting_3', ... 'sensor_1', 'sensor_2', 'sensor_3', 'sensor_4', 'sensor_5', ... 'sensor_6', 'sensor_7', 'sensor_8', 'sensor_9', 'sensor_10', ... 'sensor_11', 'sensor_12', 'sensor_13', 'sensor_14', 'sensor_15', ... 'sensor_16', 'sensor_17', 'sensor_18', 'sensor_19', 'sensor_20', ... 'sensor_21'}; rawData.Properties.VariableNames = VarNames; if ~isempty(filenameResponses) RULTest = readmatrix(filenameResponses); end % Split the signals for each unit ID IDs = rawData{:,1}; nID = unique(IDs); numObservations = numel(nID); % Initialize a table for storing data data = table(Size=[numObservations 2],... VariableTypes={'cell','cell'},... VariableNames={'X','Y'}); for i=1:numObservations idx = IDs == nID(i); data.X{i} = rawData(idx,:); if isempty(filenameResponses) % Calculate RUL from time column for train data data.Y{i} = flipud(rawData.timeStamp(idx))-1; else % Use RUL values from filenameResponses for test data sequenceLength = sum(idx); endRUL = RULTest(i); data.Y{i} = [endRUL+sequenceLength-1:-1:endRUL]'; %#ok<NBRAK> end end end
람다 플롯 함수
이 헬퍼 함수는 predictions 테이블과 lambdaCase 인수를 받고, 전체 시퀀스에서(매 타임스탬프마다) 예측된 RUL을 실제 RUL과 대조해서 플로팅하여 모든 타임스탬프에서 예측값이 어떻게 변화하는지 보여줍니다. 두 번째 인수인 lambdaCase는 테스트 엔진 번호이거나 엔진 번호를 찾기 위한 유효한 문자열 집합("random", "best", "worst" 또는 "average") 중 하나일 수 있습니다.
function localLambdaPlot(predictions,lambdaCase) if isnumeric(lambdaCase) idx = lambdaCase; else switch lambdaCase case {"Random","random","r"} idx = randperm(height(predictions),1); % Randomly choose a test case to plot case {"Best","best","b"} idx = find(predictions.RMSE == min(predictions.RMSE)); % Best case case {"Worst","worst","w"} idx = find(predictions.RMSE == max(predictions.RMSE)); % Worst case case {"Average","average","a"} err = abs(predictions.RMSE-mean(predictions.RMSE)); idx = find(err==min(err),1); end end y = predictions.Y{idx}; yPred = predictions.YPred{idx}; x = 0:numel(y)-1; plot(x,y,x,yPred) legend("True RUL","Predicted RUL") xlabel("Time stamp (Test data sequence)") ylabel("RUL (Cycles)") title("RUL for Test engine #"+idx+ " ("+lambdaCase+" case)") end
참고 문헌
Li, Xiang, Qian Ding, and Jian-Qiao Sun. “Remaining Useful Life Estimation in Prognostics Using Deep Convolution Neural Networks.” Reliability Engineering & System Safety 172 (April 2018): 1–11. https://doi.org/10.1016/j.ress.2017.11.021.
참고 항목
imageInputLayer (Deep Learning Toolbox) | prognosability | trainingOptions (Deep Learning Toolbox)
도움말 항목
- 컨벌루션 신경망에 대해 알아보기 (Deep Learning Toolbox)
- 딥러닝을 사용한 sequence-to-sequence 회귀 (Deep Learning Toolbox)
- 유사성 기반 잔여 수명 추정
- Battery Cycle Life Prediction Using Deep Learning