이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
딥러닝을 사용한 화학 공정 결함 검출
이 예제에서는 시뮬레이션 데이터를 사용하여 화학 공정의 결함을 검출할 수 있는 신경망을 훈련시키는 방법을 보여줍니다. 신경망은 시뮬레이션된 공정의 결함을 높은 정확도로 검출합니다. 일반적인 워크플로는 다음과 같습니다.
데이터 전처리하기
계층 아키텍처 설계하기
신경망 훈련시키기
검증 수행하기
신경망 테스트하기
데이터 세트 다운로드하기
이 예제에서는 Tennessee Eastman Process(TEP) 시뮬레이션 데이터 [1]에서 MathWorks®에 의해 변환된 MATLAB 형식의 파일을 사용합니다. 이 파일은 MathWorks 지원 파일 사이트에서 받을 수 있습니다. 고지 사항을 참조하십시오.
데이터 세트는 무결함 훈련 데이터 세트, 무결함 테스트 데이터 세트, 결함 훈련 데이터 세트, 결함 테스트 데이터 세트의 네 가지 구성요소로 이루어집니다. 각 파일을 개별적으로 다운로드합니다.
url = 'https://www.mathworks.com/supportfiles/predmaint/chemical-process-fault-detection-data/faultytesting.mat'; websave('faultytesting.mat',url); url = 'https://www.mathworks.com/supportfiles/predmaint/chemical-process-fault-detection-data/faultytraining.mat'; websave('faultytraining.mat',url); url = 'https://www.mathworks.com/supportfiles/predmaint/chemical-process-fault-detection-data/faultfreetesting.mat'; websave('faultfreetesting.mat',url); url = 'https://www.mathworks.com/supportfiles/predmaint/chemical-process-fault-detection-data/faultfreetraining.mat'; websave('faultfreetraining.mat',url);
다운로드한 파일을 MATLAB® 작업 공간으로 불러옵니다.
load('faultfreetesting.mat'); load('faultfreetraining.mat'); load('faultytesting.mat'); load('faultytraining.mat');
각 구성요소는 다음과 같은 두 가지 파라미터의 모든 순열에 대해 실행된 시뮬레이션의 데이터를 포함합니다.
결함 번호 — 결함 데이터 세트의 경우, 시뮬레이션된 서로 다른 결함을 나타내는 1~20 범위의 정수 값입니다. 무결함 데이터 세트의 경우, 0 값입니다.
시뮬레이션 실행 — 모든 데이터 세트에 대해 1~500 범위의 정수 값으로, 여기서 각 값은 시뮬레이션의 고유한 난수 생성기 상태를 나타냅니다.
각 시뮬레이션의 길이는 데이터 세트에 따라 달라졌습니다. 모든 시뮬레이션은 3분마다 샘플링되었습니다.
훈련 데이터 세트는 25시간 분량의 시뮬레이션에서 나온 500개의 시간 샘플을 포함합니다.
테스트 데이터 세트는 48시간 분량의 시뮬레이션에서 나온 960개의 시간 샘플을 포함합니다.
각 데이터 프레임의 열에는 다음 변수가 있습니다.
1열(
faultNumber)은 결함 유형을 나타냅니다. 0~20 사이입니다. 결함 번호 0은 무결함을 의미하고, 결함 번호 1~20은 TEP의 서로 다른 결함 유형을 나타냅니다.2열(
simulationRun)은 전체 데이터를 얻기 위해 TEP 시뮬레이션이 실행된 횟수를 나타냅니다. 훈련 데이터 세트와 테스트 데이터 세트에서, 실행 횟수는 모든 결함 번호에 대해 1~500 사이입니다. 모든simulationRun값은 시뮬레이션의 서로 다른 난수 생성기 상태를 나타냅니다.3열(
sample)은 시뮬레이션당 TEP 변수가 기록된 횟수를 나타냅니다. 값은 훈련 데이터 세트의 경우 1~500 사이이고, 테스트 데이터 세트의 경우 1~960 사이입니다. TEP 변수(4열~55열)는 훈련 데이터 세트의 경우 25시간 동안, 테스트 데이터 세트의 경우 48시간 동안 3분마다 샘플링되었습니다.4~44열(
xmeas_1~xmeas_41)은 TEP의 측정된 변수를 포함합니다.45~55열(
xmv_1~xmv_11)은 TEP의 조작된 변수를 포함합니다.
두 개 파일의 하위 섹션을 검토합니다.
head(faultfreetraining,4)
faultNumber simulationRun sample xmeas_1 xmeas_2 xmeas_3 xmeas_4 xmeas_5 xmeas_6 xmeas_7 xmeas_8 xmeas_9 xmeas_10 xmeas_11 xmeas_12 xmeas_13 xmeas_14 xmeas_15 xmeas_16 xmeas_17 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_23 xmeas_24 xmeas_25 xmeas_26 xmeas_27 xmeas_28 xmeas_29 xmeas_30 xmeas_31 xmeas_32 xmeas_33 xmeas_34 xmeas_35 xmeas_36 xmeas_37 xmeas_38 xmeas_39 xmeas_40 xmeas_41 xmv_1 xmv_2 xmv_3 xmv_4 xmv_5 xmv_6 xmv_7 xmv_8 xmv_9 xmv_10 xmv_11
___________ _____________ ______ _______ _______ _______ _______ _______ _______ _______ _______ _______ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______
0 1 1 0.25038 3674 4529 9.232 26.889 42.402 2704.3 74.863 120.41 0.33818 80.044 51.435 2632.9 25.029 50.528 3101.1 22.819 65.732 229.61 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.51 41.258 18.447
0 1 2 0.25109 3659.4 4556.6 9.4264 26.721 42.576 2705 75 120.41 0.3362 80.078 50.154 2633.8 24.419 48.772 3102 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 63.132 53.414 24.588 59.259 22.084 40.176 38.554 43.692 47.427 41.359 17.194
0 1 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.42 0.33563 80.22 50.302 2635.5 25.244 50.071 3103.5 21.924 65.732 230.08 341.38 94.605 77.466 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.666 61.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53
0 1 4 0.24977 3661.3 4512.1 9.4776 26.758 42.063 2707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 40.257 38.072 47.541 47.658 41.643 18.089
head(faultytraining,4)
faultNumber simulationRun sample xmeas_1 xmeas_2 xmeas_3 xmeas_4 xmeas_5 xmeas_6 xmeas_7 xmeas_8 xmeas_9 xmeas_10 xmeas_11 xmeas_12 xmeas_13 xmeas_14 xmeas_15 xmeas_16 xmeas_17 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_23 xmeas_24 xmeas_25 xmeas_26 xmeas_27 xmeas_28 xmeas_29 xmeas_30 xmeas_31 xmeas_32 xmeas_33 xmeas_34 xmeas_35 xmeas_36 xmeas_37 xmeas_38 xmeas_39 xmeas_40 xmeas_41 xmv_1 xmv_2 xmv_3 xmv_4 xmv_5 xmv_6 xmv_7 xmv_8 xmv_9 xmv_10 xmv_11
___________ _____________ ______ _______ _______ _______ _______ _______ _______ _______ _______ _______ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______
1 1 1 0.25038 3674 4529 9.232 26.889 42.402 2704.3 74.863 120.41 0.33818 80.044 51.435 2632.9 25.029 50.528 3101.1 22.819 65.732 229.61 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.51 41.258 18.447
1 1 2 0.25109 3659.4 4556.6 9.4264 26.721 42.576 2705 75 120.41 0.3362 80.078 50.154 2633.8 24.419 48.772 3102 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 63.132 53.414 24.588 59.259 22.084 40.176 38.554 43.692 47.427 41.359 17.194
1 1 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.42 0.33563 80.22 50.302 2635.5 25.244 50.071 3103.5 21.924 65.732 230.08 341.38 94.605 77.466 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.666 61.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53
1 1 4 0.24977 3661.3 4512.1 9.4776 26.758 42.063 2707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 40.257 38.072 47.541 47.658 41.643 18.089
데이터 정리하기
훈련 데이터 세트와 테스트 데이터 세트에서 결함 번호가 3번, 9번, 15번인 데이터 요소를 제거합니다. 이러한 결함 번호는 인식되지 않으며, 관련 시뮬레이션 결과는 오류입니다.
faultytesting(faultytesting.faultNumber == 3,:) = []; faultytesting(faultytesting.faultNumber == 9,:) = []; faultytesting(faultytesting.faultNumber == 15,:) = []; faultytraining(faultytraining.faultNumber == 3,:) = []; faultytraining(faultytraining.faultNumber == 9,:) = []; faultytraining(faultytraining.faultNumber == 15,:) = [];
데이터 나누기
훈련 데이터의 20%를 검증용으로 남겨 둠으로써 훈련 데이터를 훈련 데이터와 검증 데이터로 나눕니다. 검증 데이터 세트를 사용하면 모델 하이퍼파라미터를 조정하는 과정에서 훈련 데이터 세트에 대한 모델 피팅을 평가할 수 있습니다. 데이터 분할은 일반적으로 신경망의 과적합 및 과소적합을 방지하기 위해 사용됩니다.
결함 훈련 데이터 세트와 무결함 훈련 데이터 세트에서 총 행 개수를 가져옵니다.
H1 = height(faultfreetraining); H2 = height(faultytraining);
시뮬레이션 실행은 특정 결함 유형으로 TEP 공정이 반복된 횟수입니다. 훈련 데이터 세트와 테스트 데이터 세트에서 최대 시뮬레이션 실행을 가져옵니다.
msTrain = max(faultfreetraining.simulationRun); msTest = max(faultytesting.simulationRun);
검증 데이터에 대해 최대 시뮬레이션 실행을 계산합니다.
rTrain = 0.80; msVal = ceil(msTrain*(1 - rTrain)); msTrain = msTrain*rTrain;
최대 샘플 개수 또는 시간 스텝(즉, TEP 시뮬레이션 중에 데이터가 기록된 최대 횟수)을 가져옵니다.
sampleTrain = max(faultfreetraining.sample); sampleTest = max(faultfreetesting.sample);
무결함 훈련 데이터 세트와 결함 훈련 데이터 세트에서 분할점(행 번호)을 가져와서 훈련 데이터 세트로부터 검증 데이터 세트를 만듭니다.
rowLim1 = ceil(rTrain*H1);
rowLim2 = ceil(rTrain*H2);
trainingData = [faultfreetraining{1:rowLim1,:}; faultytraining{1:rowLim2,:}];
validationData = [faultfreetraining{rowLim1 + 1:end,:}; faultytraining{rowLim2 + 1:end,:}];
testingData = [faultfreetesting{:,:}; faultytesting{:,:}];신경망 설계 및 전처리
훈련 데이터, 검증 데이터, 테스트 데이터로 구성된 최종 데이터 세트는 500개의 균일한 시간 스텝을 갖는 52개의 신호를 포함합니다. 따라서 이 신호(시퀀스)를 올바른 결함 번호로 분류해야 시퀀스 분류 문제가 됩니다.
장단기 기억(LSTM) 신경망은 시퀀스 데이터의 분류에 적합합니다.
LSTM 신경망은 새로운 신호를 분류하기 위해 지난 신호의 고유성을 기억하는 경향이 있으므로 시계열 데이터에 적합합니다.
LSTM 신경망을 사용하면 신경망에 시퀀스 데이터를 입력하고 시퀀스 데이터의 개별 시간 스텝을 기준으로 예측을 수행할 수 있습니다. LSTM 신경망에 대한 자세한 내용은 장단기 기억 신경망 (Deep Learning Toolbox) 항목을 참조하십시오.
trainnet함수를 사용하여 신경망이 시퀀스를 분류하도록 훈련시키려면 먼저 데이터를 전처리해야 합니다. 데이터는 셀형 배열에 들어 있어야 하며, 여기서 셀형 배열의 각 요소는 단일 시뮬레이션의 52개 신호 세트를 나타내는 행렬입니다. 셀형 배열에 들어 있는 각 행렬은 TEP의 특정 시뮬레이션의 신호 세트이며, 결함이 있거나 무결함 상태일 수 있습니다. 각 신호 세트는 0~20 사이의 특정 결함 클래스를 가리킵니다.
이전의 데이터 세트 섹션에서 설명했듯이, 데이터는 52개의 변수를 포함하며 그 값은 시뮬레이션의 일정한 시간 동안 기록됩니다. sample 변수는 52개의 변수가 1회의 시뮬레이션 실행에서 기록된 횟수를 나타냅니다. sample 변수의 최댓값은 훈련 데이터 세트에서 500, 테스트 데이터 세트에서 960입니다. 따라서 각 시뮬레이션에 대해 길이가 500 또는 960인 52개의 신호 세트가 있습니다. 각 신호 세트는 TEP의 특정 시뮬레이션 실행에 속하며, 0~20 범위의 특정 결함 유형을 가리킵니다.
훈련 데이터셋과 테스트 데이터셋은 모두 각 결함 유형에 대해 500개의 시뮬레이션을 포함합니다. 훈련 데이터 세트에서 20%는 검증용으로 남겨 두었으므로 훈련 데이터 세트에는 결함 유형당 400개의 시뮬레이션이 있고 검증 데이터에는 결함 유형당 100개의 시뮬레이션이 있습니다. 헬퍼 함수 helperPreprocess를 사용하여 신호 세트를 만듭니다. 여기서 각 세트는 단일 TEP 시뮬레이션을 나타내는 셀형 배열의 단일 요소에 있는 double형 행렬입니다. 따라서 최종 훈련 데이터 세트, 검증 데이터 세트, 테스트 데이터 세트의 크기는 다음과 같습니다.
Xtrain의 크기: (시뮬레이션의 총 개수) X (결함 유형의 총 개수) = 400 X 18 = 7200XVal의 크기: (시뮬레이션의 총 개수) X (결함 유형의 총 개수) = 100 X 18 = 1800Xtest의 크기: (시뮬레이션의 총 개수) X (결함 유형의 총 개수) = 500 X 18 = 9000
데이터 세트에서 처음 500개의 시뮬레이션은 0 결함 유형(무결함)이고, 결함이 있는 후속 시뮬레이션의 순서는 알려져 있습니다. 순서에 대한 지식을 바탕으로 훈련, 검증 및 테스트 데이터 세트에 대한 실제 응답을 만들 수 있습니다.
Xtrain = helperPreprocess(trainingData,sampleTrain); Ytrain = categorical([zeros(msTrain,1);repmat([1,2,4:8,10:14,16:20],1,msTrain)']); XVal = helperPreprocess(validationData,sampleTrain); YVal = categorical([zeros(msVal,1);repmat([1,2,4:8,10:14,16:20],1,msVal)']); Xtest = helperPreprocess(testingData,sampleTest); Ytest = categorical([zeros(msTest,1);repmat([1,2,4:8,10:14,16:20],1,msTest)']);
데이터 세트 정규화하기
정규화는 값의 범위의 차이를 왜곡하지 않으면서 데이터 세트에서 숫자형 값을 공통의 스케일로 스케일링하는 기법입니다. 이 기법을 사용하면 훈련에서 큰 값을 가진 변수가 다른 변수에 비해 우세해지는 일이 없도록 할 수 있습니다. 이 기법은 또한 훈련에 필요한 중요한 정보의 손실 없이 높은 범위에 있는 숫자형 값을 작은 범위(일반적으로 -1에서 1 사이)로 변환합니다.
훈련 데이터 세트에 있는 모든 시뮬레이션의 데이터를 사용하여 52개 신호의 평균과 표준편차를 계산합니다.
tMean = mean(trainingData(:,4:end)); tSigma = std(trainingData(:,4:end));
헬퍼 함수 helperNormalize를 사용하여 훈련 데이터의 평균과 표준편차를 기반으로 세 데이터 세트의 각 셀에 정규화를 적용합니다.
Xtrain = helperNormalize(Xtrain, tMean, tSigma); XVal = helperNormalize(XVal, tMean, tSigma); Xtest = helperNormalize(Xtest, tMean, tSigma);
데이터 시각화하기
Xtrain 데이터 세트는 400개의 무결함 시뮬레이션과 그 뒤에 이어지는 6800개의 결함 시뮬레이션을 포함합니다. 무결함 데이터와 결함 데이터를 시각화합니다. 먼저 무결함 데이터의 플롯을 만듭니다. 이 예제에서는 읽기 쉬운 Figure를 만들기 위해 Xtrain 데이터 세트에 있는 10개의 신호만 플로팅하여 레이블을 지정합니다.
figure;
splot = 10;
plot(Xtrain{1}(:,1:10));
xlabel("Time Step");
title("Training Observation for Non-Faulty Data");
legend("Signal " + string(1:splot),'Location','northeastoutside');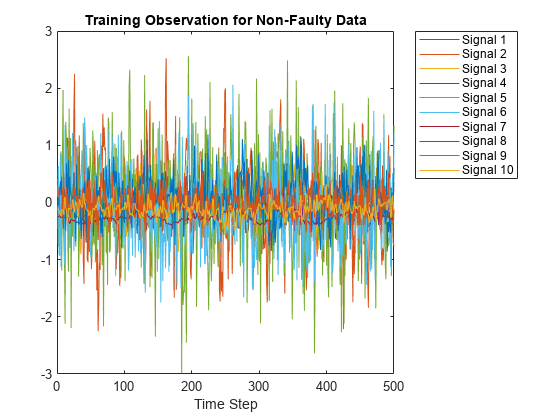
이번에는 셀형 배열에서 400번째 이후의 요소 중 아무거나 플로팅하여 무결함 플롯을 결함 플롯과 비교합니다.
figure;
plot(Xtrain{1000}(:,1:10));
xlabel("Time Step");
title("Training Observation for Faulty Data");
legend("Signal " + string(1:splot),'Location','northeastoutside');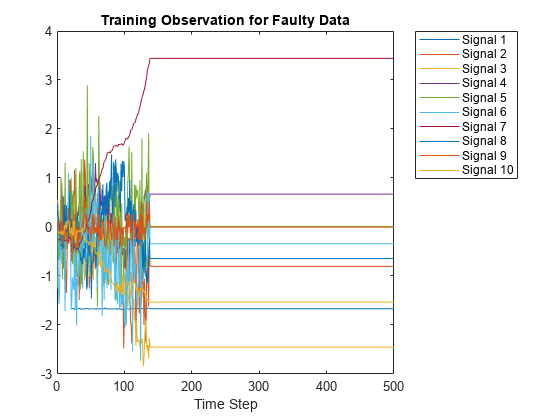
계층 아키텍처와 훈련 옵션
LSTM 계층은 입력 시퀀스의 중요한 측면만 기억하는 경향이 있으므로 시퀀스 분류를 위한 좋은 선택이 됩니다.
입력 계층
sequenceInputLayer가 입력 신호의 개수(52)와 같은 크기가 되도록 지정합니다.52개, 40개, 25개 단위를 갖는 3개의 LSTM 은닉 계층을 지정합니다. 이 지정은 [2]에서 수행한 실험을 따른 것입니다. 시퀀스 분류에 LSTM 신경망을 사용하는 것에 대한 자세한 내용은 딥러닝을 사용한 시퀀스 분류 (Deep Learning Toolbox) 항목을 참조하십시오.
과적합을 방지하기 위해 LSTM 계층 사이에 3개의 드롭아웃 계층을 추가합니다. 드롭아웃 계층은 신경망이 계층에 있는 작은 뉴런 세트에 민감해지지 않도록 하기 위해 주어진 확률에 따라 다음 계층의 입력 요소를 무작위로 0으로 설정합니다.
마지막으로, 분류를 위해 출력 클래스의 개수(18)와 크기가 같은 완전 연결 계층을 포함합니다. 완전 연결 계층 뒤에는 다중 클래스 문제에서 각 클래스에 소수점 확률(예측 가능성)을 할당하는 소프트맥스 계층을 포함합니다.
numSignals = 52;
numHiddenUnits2 = 52;
numHiddenUnits3 = 40;
numHiddenUnits4 = 25;
numClasses = 18;
layers = [ ...
sequenceInputLayer(numSignals)
lstmLayer(numHiddenUnits2,'OutputMode','sequence')
dropoutLayer(0.2)
lstmLayer(numHiddenUnits3,'OutputMode','sequence')
dropoutLayer(0.2)
lstmLayer(numHiddenUnits4,'OutputMode','last')
dropoutLayer(0.2)
fullyConnectedLayer(numClasses)
softmaxLayer];trainnet이 사용하는 훈련 옵션을 설정합니다.
이름-값 쌍 'ExecutionEnvironment'의 디폴트 값을 'auto'로 유지합니다. 이 설정을 사용하여 소프트웨어가 자동으로 실행 환경을 선택합니다. 기본적으로 trainnet은 GPU가 사용 가능한 경우 GPU를 사용하고 그렇지 않으면 CPU를 사용합니다. GPU에서 훈련시키려면 Parallel Computing Toolbox™와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오. 이 예제에서는 다량의 데이터를 사용하므로 GPU를 사용하면 훈련 시간이 크게 줄어듭니다.
이름-값 인수 쌍 'Shuffle'을 'every-epoch'로 설정하면 매 Epoch마다 동일한 데이터가 버려지는 것을 방지할 수 있습니다.
딥러닝을 위한 훈련 옵션에 대한 자세한 내용은 trainingOptions (Deep Learning Toolbox) 항목을 참조하십시오.
maxEpochs = 40; miniBatchSize = 50; options = trainingOptions('adam', ... 'ExecutionEnvironment','auto', ... 'GradientThreshold',1, ... 'MaxEpochs',maxEpochs, ... 'MiniBatchSize', miniBatchSize,... 'Shuffle','every-epoch', ... 'Verbose',0, ... 'Plots','training-progress',... 'ValidationData',{XVal,YVal});
신경망 훈련시키기
trainnet를 사용하여 LSTM 신경망을 훈련시킵니다.
net = trainnet(Xtrain,Ytrain,layers,"crossentropy",options);
훈련 진행 상황 Figure에 신경망 정확도에 대한 플롯이 표시됩니다. Figure 오른쪽에서 훈련 시간과 설정에 대한 정보를 확인합니다.
신경망 테스트하기
훈련된 신경망을 테스트 세트에 대해 실행하고 신호의 결함 유형을 예측합니다. minibatchpredict를 사용하여 테스트 데이터에 대한 점수를 가져온 다음 해당 점수를 각각의 레이블로 변환합니다.
scores = minibatchpredict(net,Xtest); Ypred = scores2label(scores,unique(Ytrain));
정확도를 계산합니다. 정확도는 테스트 데이터에서 Ypred의 분류와 일치하는 실제 레이블의 개수를 테스트 데이터에 있는 영상의 개수로 나눈 값입니다.
acc = sum(Ypred == Ytest)./numel(Ypred)
acc = 0.9997
높은 정확도는 신경망이 보이지 않는 신호의 결함 유형을 최소한의 오차로 성공적으로 식별할 수 있음을 나타냅니다. 따라서 정확도가 높을수록 신경망의 성능이 더 좋습니다.
테스트 신호의 실제 클래스 레이블을 사용하여 혼동행렬을 플로팅하여 신경망이 각 결함을 얼마나 잘 식별하는지 확인합니다.
confusionchart(Ytest,Ypred);
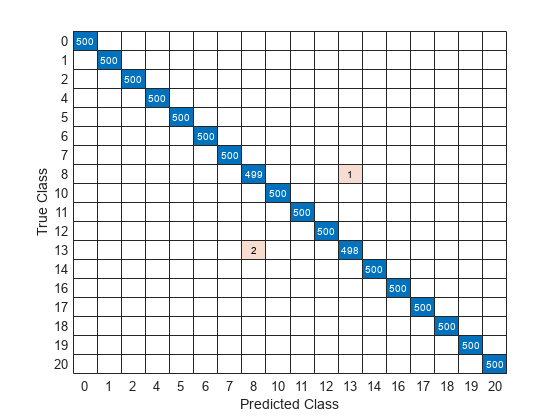
혼동행렬을 사용하여 분류 신경망의 효과를 평가할 수 있습니다. 혼동행렬은 주대각선에 숫자 값을, 다른 곳에는 0을 갖습니다. 이 예제에서는 훈련된 신경망이 효과적이며 신호의 99% 이상을 올바르게 분류합니다.
참고 문헌
[1] Rieth, C. A., B. D. Amsel, R. Tran., and B. Maia. "Additional Tennessee Eastman Process Simulation Data for Anomaly Detection Evaluation." Harvard Dataverse, Version 1, 2017. https://doi.org/10.7910/DVN/6C3JR1.
[2] Heo, S., and J. H. Lee. "Fault Detection and Classification Using Artificial Neural Networks." Department of Chemical and Biomolecular Engineering, Korea Advanced Institute of Science and Technology.
헬퍼 함수
helperPreprocess
헬퍼 함수 helperPreprocess는 최대 샘플 개수를 사용하여 데이터를 전처리합니다. 샘플 개수는 신호 길이를 나타내며, 이 길이는 데이터 세트 전체에서 일관됩니다. 데이터 세트 전체에 for 루프가 적용되며, 신호 길이 필터가 적용되어 52개의 신호 세트를 형성합니다. 각 세트는 셀형 배열의 요소입니다. 각 셀형 배열은 단일 시뮬레이션을 나타냅니다.
function processed = helperPreprocess(mydata,limit) H = size(mydata,1); processed = {}; for ind = 1:limit:H x = mydata(ind:(ind+(limit-1)),4:end); processed = [processed; x]; %#ok<AGROW> end end
helperNormalize
헬퍼 함수 helperNormalize는 데이터, 평균 및 표준편차를 사용하여 데이터를 정규화합니다.
function data = helperNormalize(data,m,s) for ind = 1:size(data,1) data{ind} = (data{ind} - m)./s; end end
참고 항목
trainNetwork (Deep Learning Toolbox) | trainingOptions (Deep Learning Toolbox)
도움말 항목
- 장단기 기억 신경망 (Deep Learning Toolbox)
- 딥러닝을 사용한 시퀀스 분류 (Deep Learning Toolbox)