medicalSegmentAnythingModel
설명
Add-On Required: 이 기능을 사용하려면 다음 애드온이
MedSAM(Medical Segment Anything Model)은 대규모 의료 영상 데이터 세트에 대한 의료 영상 분할을 위해 미세 조정된 SAM(Segment Anything Model)입니다. medicalSegmentAnythingModel 객체와 그 객체 함수를 사용하여 시각적 프롬프트를 통해 2차원 의료 영상의 객체를 대화형 방식으로 분할할 수 있습니다. medicalSegmentAnythingModel 객체는 모델을 다시 훈련시키지 않고도 의료 영상에 있는 객체의 의미론적 분할을 위해 MedSAM을 구성합니다. 영상을 분할하려면 먼저 extractEmbeddings 객체 함수를 사용하여 MedSAM 영상 인코더에서 영상 임베딩을 추출해야 합니다. 그런 다음 segmentObjectsFromEmbeddings 객체 함수를 사용하여 마스크 디코더로 영상 임베딩에서 객체를 분할합니다.
참고
이 기능을 사용하려면 Deep Learning Toolbox™ 및 Computer Vision Toolbox™와 Medical Imaging Toolbox™ Model for Medical Segment Anything Model 애드온도 필요합니다.
생성
설명
medsam = medicalSegmentAnythingModelextractEmbeddings 객체 함수에 지정하여 영상 임베딩을 추출한 다음 임베딩에 시각적 프롬프트와 함께 segmentObjectsFromEmbeddings 객체 함수를 사용하십시오.
객체 함수
extractEmbeddings | MedSAM(Medical Segment Anything Model) 인코더에서 영상 임베딩 추출 |
segmentObjectsFromEmbeddings | MedSAM(Medical Segment Anything Model) 영상 임베딩을 사용하여 의료 영상의 객체 분할 |
예제
MedSAM(Medical Segment Anything Model) 객체를 만듭니다.
medsam = medicalSegmentAnythingModel;
작업 공간에 엑스레이 영상을 불러옵니다. 영상을 시각화합니다.
medImg = medicalImage("forearmXrayImage1.dcm");
img = medImg.Pixels;
figure
imshow(img,[])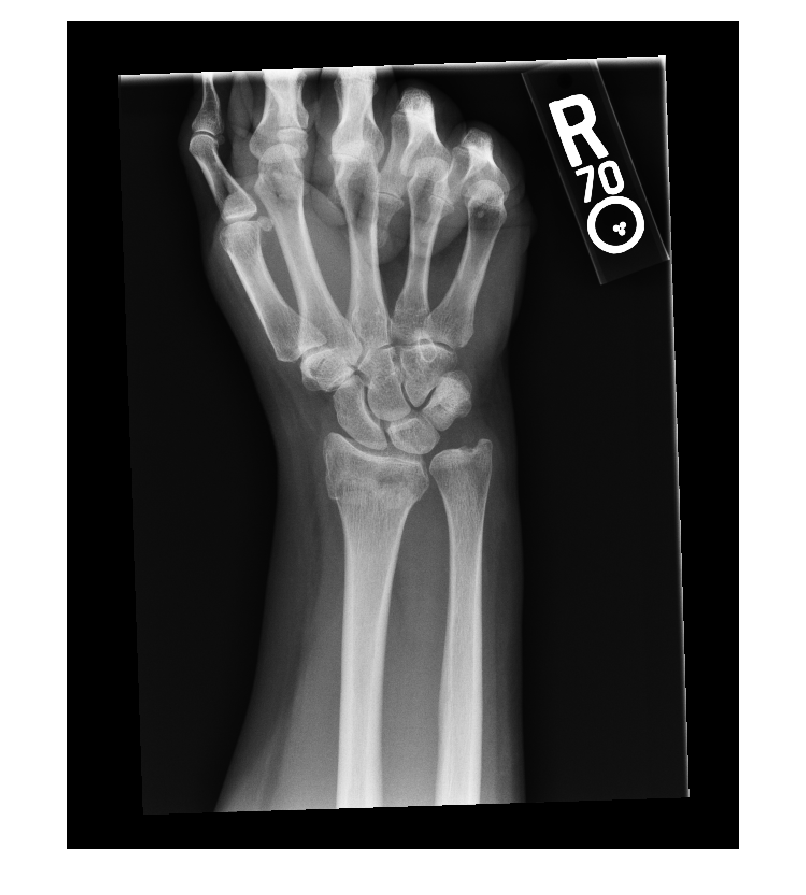
extractEmbeddings 객체 함수를 사용하여 엑스레이 영상에서 영상 임베딩을 추출합니다.
embeddings = extractEmbeddings(medsam,img);
MedSAM 대화형 분할을 위해 영상 표시를 준비합니다. 새 Figure와 좌표축을 만들고 영상을 표시합니다.
f = figure; ax = axes(f); imshow(img,[],Parent=ax);
drawrectangle 함수를 사용하여, 분할할 객체가 포함된 ROI를 영상 위에 Rectangle 객체로 그립니다.
roi = drawrectangle(ax);

객체를 분할하려면 segmentObjectsFromEmbeddings 객체 함수를 사용하여 영상 임베딩에 대해 MedSAM 디코더를 실행합니다. 경계 상자의 시각적 프롬프트 BoundingBox를 사각형 ROI의 위치로 지정합니다.
mask = segmentObjectsFromEmbeddings(medsam,embeddings,size(img),BoundingBox=roi.Position); overlayedImg = insertObjectMask(rescale(img),mask);
영상 표시에서 분할 마스크가 영상에 겹쳐지게 시각화합니다.
figure imshow(overlayedImg)
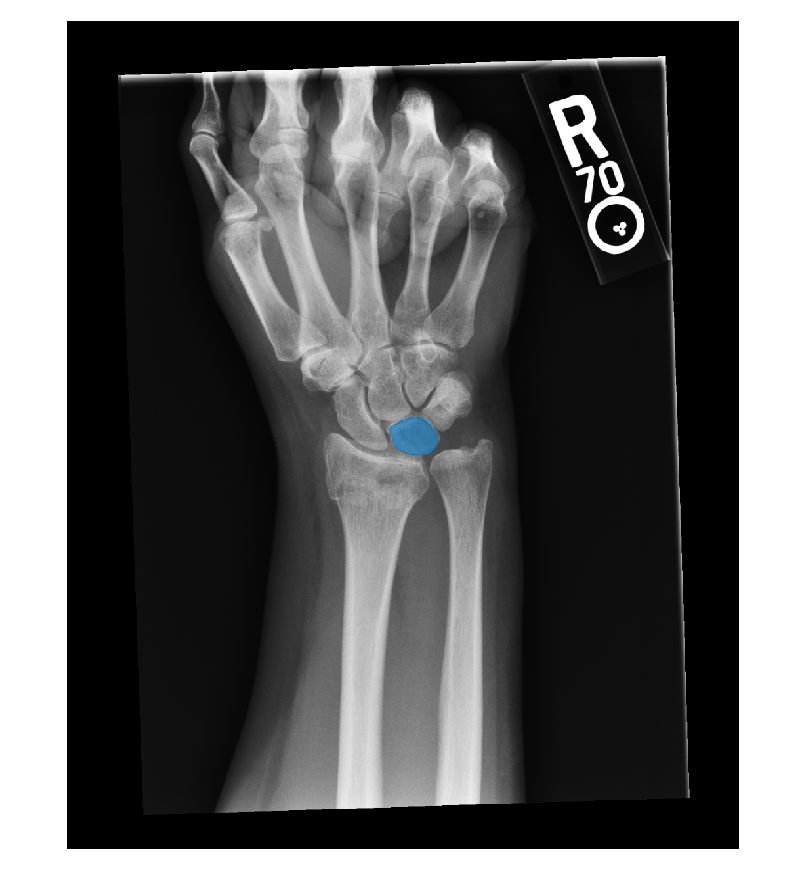
참고 문헌
[1] Ma, Jun, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. “Segment Anything in Medical Images.” Nature Communications 15, no. 1 (January 22, 2024): 654. https://doi.org/10.1038/s41467-024-44824-z.
버전 내역
R2024b에 개발됨