splitvars
테이블 또는 타임테이블에 있는 다중 열 변수 분할
설명
T2 = splitvars(T1)T1에 있는 모든 다중 열 변수를 분할하여 T2에서 단일 열 변수가 되도록 합니다. T1의 단일 열 변수는 모두 변경되지 않습니다.
T1의 변수가 여러 개의 열을 갖는 경우splitvars는T1의 원래 변수 이름으로부터T2의 새 변수에 고유한 이름을 만듭니다.T1의 변수가 테이블 자체인 경우splitvars는 이 테이블의 변수 이름(그리고 필요한 경우 이 테이블의 이름)을 사용하여T2의 새 변수에 고유한 이름을 만듭니다.
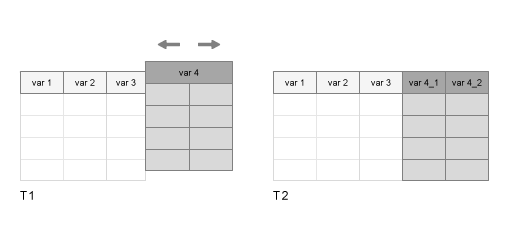
변수를 하나의 다중 열 변수로 병합하려면 mergevars 함수를 사용하십시오.
예제
작업 공간 변수로 테이블을 만듭니다. 변수 중 일부는 여러 개의 열을 갖는 행렬입니다.
A = (1:3)'; B = [5 11 12; 20 30 50; 0.1 3.4 5.9]'; C = ["a" "XX";"b" "YY";"c" "ZZ"]; D = [128 256 512]'; T1 = table(A,B,C,D)
T1=3×4 table
A B C D
_ ________________ ___________ ___
1 5 20 0.1 "a" "XX" 128
2 11 30 3.4 "b" "YY" 256
3 12 50 5.9 "c" "ZZ" 512
변수 B와 C를 분할합니다. 출력 테이블의 모든 변수는 하나의 열을 갖습니다.
T2 = splitvars(T1)
T2=3×7 table
A B_1 B_2 B_3 C_1 C_2 D
_ ___ ___ ___ ___ ____ ___
1 5 20 0.1 "a" "XX" 128
2 11 30 3.4 "b" "YY" 256
3 12 50 5.9 "c" "ZZ" 512
patients.mat 파일의 데이터로 구성된 배열을 사용하여 여러 테이블이 포함된 테이블을 만듭니다.
load patients
Personal_Data = table(Age,Smoker);
BMI_Data = table(Height,Weight);
BloodPressure = table(Systolic,Diastolic);
LastName = string(LastName);
T1 = table(LastName,Personal_Data,BMI_Data,BloodPressure)T1=100×4 table
LastName Personal_Data BMI_Data BloodPressure
__________ _____________ ________________ _____________________
Age Smoker Height Weight Systolic Diastolic
___ ______ ______ ______ ________ _________
"Smith" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Williams" 38 false 64 131 125 83
"Jones" 40 false 67 133 117 75
"Brown" 49 false 64 119 122 80
"Davis" 46 false 68 142 121 70
"Miller" 33 true 64 142 130 88
"Wilson" 40 false 68 180 115 82
"Moore" 28 false 68 183 115 78
"Taylor" 31 false 66 132 118 86
"Anderson" 45 false 68 128 114 77
"Thomas" 42 false 66 137 115 68
"Jackson" 25 false 71 174 127 74
"White" 39 true 72 202 130 95
"Harris" 36 false 65 129 114 79
"Martin" 48 true 71 181 130 92
⋮
BloodPressure를 분할할 변수로 지정합니다.
T2 = splitvars(T1,"BloodPressure")T2=100×5 table
LastName Personal_Data BMI_Data Systolic Diastolic
__________ _____________ ________________ ________ _________
Age Smoker Height Weight
___ ______ ______ ______
"Smith" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Williams" 38 false 64 131 125 83
"Jones" 40 false 67 133 117 75
"Brown" 49 false 64 119 122 80
"Davis" 46 false 68 142 121 70
"Miller" 33 true 64 142 130 88
"Wilson" 40 false 68 180 115 82
"Moore" 28 false 68 183 115 78
"Taylor" 31 false 66 132 118 86
"Anderson" 45 false 68 128 114 77
"Thomas" 42 false 66 137 115 68
"Jackson" 25 false 71 174 127 74
"White" 39 true 72 202 130 95
"Harris" 36 false 65 129 114 79
"Martin" 48 true 71 181 130 92
⋮
여러 개의 변수를 이름으로 지정하려면 string형 배열을 사용하십시오.
T3 = splitvars(T1,["BMI_Data" "BloodPressure"])
T3=100×6 table
LastName Personal_Data Height Weight Systolic Diastolic
__________ _____________ ______ ______ ________ _________
Age Smoker
___ ______
"Smith" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Williams" 38 false 64 131 125 83
"Jones" 40 false 67 133 117 75
"Brown" 49 false 64 119 122 80
"Davis" 46 false 68 142 121 70
"Miller" 33 true 64 142 130 88
"Wilson" 40 false 68 180 115 82
"Moore" 28 false 68 183 115 78
"Taylor" 31 false 66 132 118 86
"Anderson" 45 false 68 128 114 77
"Thomas" 42 false 66 137 115 68
"Jackson" 25 false 71 174 127 74
"White" 39 true 72 202 130 95
"Harris" 36 false 65 129 114 79
"Martin" 48 true 71 181 130 92
⋮
변수를 위치로 지정하려면 숫자형 배열을 사용하십시오.
T4 = splitvars(T1,[2 4])
T4=100×6 table
LastName Age Smoker BMI_Data Systolic Diastolic
__________ ___ ______ ________________ ________ _________
Height Weight
______ ______
"Smith" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Williams" 38 false 64 131 125 83
"Jones" 40 false 67 133 117 75
"Brown" 49 false 64 119 122 80
"Davis" 46 false 68 142 121 70
"Miller" 33 true 64 142 130 88
"Wilson" 40 false 68 180 115 82
"Moore" 28 false 68 183 115 78
"Taylor" 31 false 66 132 118 86
"Anderson" 45 false 68 128 114 77
"Thomas" 42 false 66 137 115 68
"Jackson" 25 false 71 174 127 74
"White" 39 true 72 202 130 95
"Harris" 36 false 65 129 114 79
"Martin" 48 true 71 181 130 92
⋮
patients.mat 파일의 데이터를 사용하여 다중 열 변수가 포함된 테이블을 만듭니다.
load patients
Personal_Data = [Age,Height,Weight];
BloodPressure = [Systolic,Diastolic];
T1 = table(LastName,Smoker,Personal_Data,BloodPressure)T1=100×4 table
LastName Smoker Personal_Data BloodPressure
____________ ______ ________________ _____________
{'Smith' } true 38 71 176 124 93
{'Johnson' } false 43 69 163 109 77
{'Williams'} false 38 64 131 125 83
{'Jones' } false 40 67 133 117 75
{'Brown' } false 49 64 119 122 80
{'Davis' } false 46 68 142 121 70
{'Miller' } true 33 64 142 130 88
{'Wilson' } false 40 68 180 115 82
{'Moore' } false 28 68 183 115 78
{'Taylor' } false 31 66 132 118 86
{'Anderson'} false 45 68 128 114 77
{'Thomas' } false 42 66 137 115 68
{'Jackson' } false 25 71 174 127 74
{'White' } true 39 72 202 130 95
{'Harris' } false 36 65 129 114 79
{'Martin' } true 48 71 181 130 92
⋮
BloodPressure를 분할한 후 출력 테이블의 새 변수에 새 이름을 지정합니다.
T2 = splitvars(T1,"BloodPressure",NewVariableNames=["Systolic" "Diastolic"])
T2=100×5 table
LastName Smoker Personal_Data Systolic Diastolic
____________ ______ ________________ ________ _________
{'Smith' } true 38 71 176 124 93
{'Johnson' } false 43 69 163 109 77
{'Williams'} false 38 64 131 125 83
{'Jones' } false 40 67 133 117 75
{'Brown' } false 49 64 119 122 80
{'Davis' } false 46 68 142 121 70
{'Miller' } true 33 64 142 130 88
{'Wilson' } false 40 68 180 115 82
{'Moore' } false 28 68 183 115 78
{'Taylor' } false 31 66 132 118 86
{'Anderson'} false 45 68 128 114 77
{'Thomas' } false 42 66 137 115 68
{'Jackson' } false 25 71 174 127 74
{'White' } true 39 72 202 130 95
{'Harris' } false 36 65 129 114 79
{'Martin' } true 48 71 181 130 92
⋮
BMI_Data와 BloodPressure를 모두 분할합니다. 분할되는 각 변수에 대해, 올바른 개수의 새 이름을 갖는 셀형 배열을 제공해야 합니다.
T3 = splitvars(T1,["Personal_Data" "BloodPressure"], ... NewVariableNames={["Age" "Height" "Weight"] ["Systolic" "Diastolic"]})
T3=100×7 table
LastName Smoker Age Height Weight Systolic Diastolic
____________ ______ ___ ______ ______ ________ _________
{'Smith' } true 38 71 176 124 93
{'Johnson' } false 43 69 163 109 77
{'Williams'} false 38 64 131 125 83
{'Jones' } false 40 67 133 117 75
{'Brown' } false 49 64 119 122 80
{'Davis' } false 46 68 142 121 70
{'Miller' } true 33 64 142 130 88
{'Wilson' } false 40 68 180 115 82
{'Moore' } false 28 68 183 115 78
{'Taylor' } false 31 66 132 118 86
{'Anderson'} false 45 68 128 114 77
{'Thomas' } false 42 66 137 115 68
{'Jackson' } false 25 71 174 127 74
{'White' } true 39 72 202 130 95
{'Harris' } false 36 65 129 114 79
{'Martin' } true 48 71 181 130 92
⋮
입력 인수
출력 인수
분할된 변수를 갖는 출력 테이블로, 테이블이나 타임테이블로 반환됩니다.
확장 기능
splitvars 함수는 tall형 배열을 완전히 지원합니다. 자세한 내용은 tall형 배열 항목을 참조하십시오.
사용법 관련 참고 및 제한 사항:
vars입력 인수는 패턴 표현식을 지원하지 않습니다.NewVariableNames이름-값 인수의 값은 상수여야 합니다.분할된 변수의 열 개수는 가변적일 수 없습니다.
C/C++ 코드 생성 섹션의 사용법 관련 참고 및 제한 사항을 참조하십시오. GPU 코드 생성에도 동일한 사용법 관련 참고 및 제한 사항이 적용됩니다.
splitvars 함수는 스레드 기반 환경을 완전히 지원합니다. 자세한 내용은 스레드 기반 환경에서 MATLAB 함수 실행하기 항목을 참조하십시오.
버전 내역
R2018a에 개발됨
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
웹사이트 선택
번역된 콘텐츠를 보고 지역별 이벤트와 혜택을 살펴보려면 웹사이트를 선택하십시오. 현재 계신 지역에 따라 다음 웹사이트를 권장합니다:
또한 다음 목록에서 웹사이트를 선택하실 수도 있습니다.
사이트 성능 최적화 방법
최고의 사이트 성능을 위해 중국 사이트(중국어 또는 영어)를 선택하십시오. 현재 계신 지역에서는 다른 국가의 MathWorks 사이트 방문이 최적화되지 않았습니다.
미주
- América Latina (Español)
- Canada (English)
- United States (English)
유럽
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)