테이블의 데이터에 액세스하기
테이블은 변수에 열 방향 데이터를 저장하는 컨테이너입니다. 테이블의 데이터에 액세스하려면, 행과 열을 지정하여 행렬의 요소를 참조하는 것과 비슷하게, 행과 변수를 지정하여 테이블의 요소를 참조합니다. 테이블 변수는 구조체 필드와 마찬가지로 이름을 가집니다. 테이블의 행도 이름을 가질 수 있지만 행 이름이 필수적인 것은 아닙니다. 테이블의 요소를 참조하려면 위치, 이름 또는 데이터형을 사용하여 행과 변수를 지정합니다. 결과는 배열일 수도 있고 테이블일 수도 있습니다.
이 항목에서는 몇 가지 테이블 인덱싱 구문을 소개하고 각 유형을 언제 사용하는지 설명합니다. 추가 예제에서는 이러한 테이블 인덱싱 유형을 적용하는 여러 가지 방법을 보여줍니다. 이 항목의 끝에 나와 있는 표에는 인덱싱 구문, 행과 변수를 지정하는 방법, 결과 출력값이 요약되어 있습니다.
테이블 인덱싱 구문
결과는 사용하는 인덱싱 유형에 따라 테이블에서 추출된 배열이거나 새로운 테이블입니다. 인덱싱에 사용하는 방법은 다음과 같습니다.
점 표기법은
T.또는varnameT.(형식으로 작성하며, 하나의 테이블 변수에서 배열을 추출합니다.expression)중괄호는
T{형식으로 작성하며, 지정된 행과 변수에서 배열을 추출합니다. 변수들은 서로 호환되는 데이터형을 가져야만 하나의 배열로 결합될 수 있습니다.rows,vars}괄호는
T(형식으로 작성하며, 지정된 행과 변수만 갖는 테이블을 반환합니다.rows,vars)
다음 도식은 3가지 유형의 테이블 인덱싱을 보여줍니다.
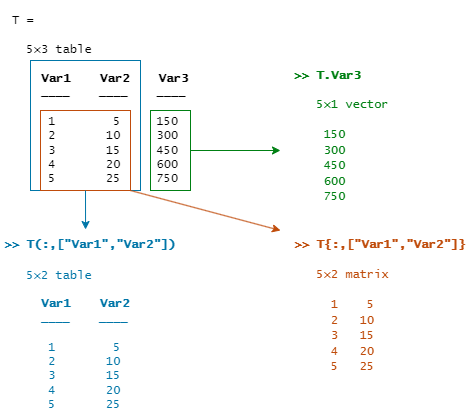
권장되는 인덱싱 구문
테이블의 내용에 액세스하는 데 권장되는 방법은 원하는 결과와 지정하는 변수의 개수에 따라 다릅니다. 다음 구문 예제에서 T는 변수 Var1, Var2, Var3을 갖는 테이블입니다. (table 함수를 호출할 때 변수 이름을 지정하지 않으면 이러한 이름이 디폴트로 설정됩니다.)
T = table([1;2;3;4;5],[5;10;15;20;25],[150;300;450;600;750])
하나의 테이블 변수에 액세스하려면 점 표기법을 사용하십시오. 변수의 이름을 지정하거나, 변수의 이름이나 변수의 위치와 일치하는 표현식을 지정하십시오.
변수의 리터럴 이름을 사용하는 것이 표현식을 사용하는 것보다 더 빠릅니다. 예를 들어,
T.Var1과T.(1)은 둘 다T의 첫 번째 변수에 액세스하지만 표현식을 사용할 때 속도가 더 느립니다.X = T.Var1 Y = T.Var1(1:3) Z = T.(1) T.Var1 = T.Var1 .* 10
중괄호를 사용하여 하나의 변수를 지정할 수도 있습니다. 하지만 점 표기법을 사용하여 변수에 액세스하는 것이 중괄호를 사용하여 변수에 액세스하는 것보다 더 빠릅니다.
여러 개의 테이블 변수에 액세스하려면 중괄호를 사용하십시오.
X = T{:,["Var1" "Var2"]} Y = T{1:3,["Var1" "Var2"]} T{:,["Var1" "Var2"]} = T{:,["Var1" "Var2"]} .* 10지정된 행과 변수만 갖는 테이블을 반환하려면 괄호를 사용하십시오.
T2 = T(:,["Var1" "Var2"]) T2 = T(1:3,["Var1" "Var2"]) A = rand(5,1) B = rand(5,1) T(:,["Var1" "Var2"]) = table(A,B)
행과 변수를 지정하여 인덱싱하기
숫자형 인덱스, 행과 변수 이름, 또는 변수 데이터형을 지정하여 테이블의 요소를 참조할 수 있습니다.
테이블을 만듭니다. 샘플 patients.mat 파일에서 데이터로 구성된 배열을 불러옵니다. 그런 다음 table 함수를 사용하여 이 배열에서 테이블을 만듭니다. 입력 배열의 이름이 테이블 변수의 이름이 됩니다. 행 이름은 선택 사항입니다. 행 이름을 지정하려면 RowNames 이름-값 인수를 사용하십시오.
load patients.mat Age Height Weight Smoker LastName T = table(Age,Height,Weight,Smoker,RowNames=LastName)
T=100×4 table
Age Height Weight Smoker
___ ______ ______ ______
Smith 38 71 176 true
Johnson 43 69 163 false
Williams 38 64 131 false
Jones 40 67 133 false
Brown 49 64 119 false
Davis 46 68 142 false
Miller 33 64 142 true
Wilson 40 68 180 false
Moore 28 68 183 false
Taylor 31 66 132 false
Anderson 45 68 128 false
Thomas 42 66 137 false
Jackson 25 71 174 false
White 39 72 202 true
Harris 36 65 129 false
Martin 48 71 181 true
⋮
위치를 사용해서 인덱싱하기
위치를 숫자형 인덱스로 지정하여 테이블의 요소를 참조할 수 있습니다. 콜론과 end 키워드를 사용할 수도 있습니다.
예를 들어, T의 처음 3개 행의 요소를 참조합니다. 다음 구문은 지정된 개수의 행을 갖는 테이블을 반환하는 간단한 방법입니다.
firstRows = T(1:3,:)
firstRows=3×4 table
Age Height Weight Smoker
___ ______ ______ ______
Smith 38 71 176 true
Johnson 43 69 163 false
Williams 38 64 131 false
T의 처음 2개 변수와 마지막 3개 행을 갖는 테이블을 반환합니다.
lastRows = T(end-2:end,1:2)
lastRows=3×2 table
Age Height
___ ______
Griffin 49 70
Diaz 45 68
Hayes 48 66
변수들이 서로 호환되는 데이터형을 갖고 있는 경우, 중괄호를 사용하면 추출된 데이터를 배열로 반환할 수 있습니다.
lastRowsAsArray = T{end-2:end,1:2}lastRowsAsArray = 3×2
49 70
45 68
48 66
변수 이름을 사용해서 인덱싱하기
변수 이름을 string형 배열로 지정하여 테이블의 요소를 참조할 수 있습니다. 테이블 변수 이름이 유효한 MATLAB® 식별자일 필요는 없습니다. 이름은 공백과 비ASCII 문자를 포함할 수 있으며 어떤 문자로도 시작할 수 있습니다.
예를 들어, T의 처음 3개 행과 Height, Weight 변수만 갖는 테이블을 반환합니다.
variablesByName = T(1:3,["Height" "Weight"])
variablesByName=3×2 table
Height Weight
______ ______
Smith 71 176
Johnson 69 163
Williams 64 131
중괄호를 사용하여 데이터를 배열로 반환합니다.
arraysFromVariables = T{1:3,["Height" "Weight"]}arraysFromVariables = 3×2
71 176
69 163
64 131
점 표기법을 사용하여 하나의 변수의 요소를 참조할 수도 있습니다. 사실 하나의 변수에 액세스할 때는 점 표기법이 더 효율적입니다.
heightAsArray = T.Height
heightAsArray = 100×1
71
69
64
67
64
68
64
68
68
66
68
66
71
72
65
⋮
점 표기법을 사용하여 Height 변수의 처음 3개 행을 배열로 반환합니다.
firstHeights = T.Height(1:3)
firstHeights = 3×1
71
69
64
행 이름을 사용하여 인덱싱하기
테이블에 행 이름이 있는 경우, 행 번호 외에도 행 이름을 사용하여 테이블의 요소를 참조할 수 있습니다. 예를 들어, T에서 3명의 특정 환자에 대한 행을 반환합니다.
rowsByName = T(["Griffin" "Diaz" "Hayes"],:)
rowsByName=3×4 table
Age Height Weight Smoker
___ ______ ______ ______
Griffin 49 70 186 false
Diaz 45 68 172 true
Hayes 48 66 177 false
중괄호를 사용하여 데이터를 배열로 반환할 수도 있습니다.
arraysFromRows = T{["Griffin" "Diaz" "Hayes"],:}arraysFromRows = 3×4
49 70 186 0
45 68 172 1
48 66 177 0
하나의 요소 참조하기
테이블의 한 요소를 참조하려면 하나의 행과 하나의 변수를 지정합니다. 중괄호를 사용하여 요소를 배열로 반환합니다. 여기서는 스칼라 값이 반환됩니다.
oneElement = T{"Diaz","Height"}oneElement = 68
이 요소를 하나의 행과 하나의 변수를 갖는 테이블로 반환하려면 괄호를 사용합니다.
oneElementTable = T("Diaz","Height")
oneElementTable=table
Height
______
Diaz 68
변수 데이터형을 사용하여 인덱싱하기
동일한 데이터형을 갖는 변수를 지정하여 테이블의 요소를 참조하려면, vartype 함수를 사용하여 데이터형 첨자를 만드십시오.
예를 들어, 숫자형 테이블 변수와 일치하는 데이터형 첨자를 생성합니다.
numSubscript = vartype("numeric")numSubscript = table vartype subscript: Select table variables matching the type 'numeric' See Access Data in a Table.
T의 숫자형 변수만 포함된 테이블을 반환합니다. Smoker 변수는 논리형 변수이므로 포함되지 않습니다.
onlyNumVariables = T(:,numSubscript)
onlyNumVariables=100×3 table
Age Height Weight
___ ______ ______
Smith 38 71 176
Johnson 43 69 163
Williams 38 64 131
Jones 40 67 133
Brown 49 64 119
Davis 46 68 142
Miller 33 64 142
Wilson 40 68 180
Moore 28 68 183
Taylor 31 66 132
Anderson 45 68 128
Thomas 42 66 137
Jackson 25 71 174
White 39 72 202
Harris 36 65 129
Martin 48 71 181
⋮
테이블에 값 할당하기
인덱싱 구문을 사용하여 테이블에 값을 할당할 수 있습니다. 변수, 행 또는 개별 요소에 값을 할당할 수 있습니다.
변수에 값 할당하기
readtable 함수를 사용하여 스프레드시트의 정전 데이터를 테이블로 가져옵니다.
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
하나의 변수에 값을 할당하려면 점 표기법을 사용합니다. 예를 들어, Loss 변수를 100배만큼 스케일링합니다.
outages.Loss = outages.Loss .* 100
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 45898 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 53014 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 28940 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 43481 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 18644 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 23129 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 31186 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 23993 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 28672 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 7338.7 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 15999 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 9591.7 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 25409 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
중괄호를 사용하여 여러 개의 변수에 데이터를 할당할 수도 있습니다. 변수들은 서로 호환되는 데이터형을 가져야 합니다. 예를 들어, Loss와 Customers를 1/10,000배만큼 스케일링합니다.
outages{:,["Loss" "Customers"]} = outages{:,["Loss" "Customers"]} ./ 10000outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ _______ _________ ________________ _________________
"SouthWest" 2002-02-01 12:18 4.5898 182.02 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 5.3014 21.204 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 1.8644 21.275 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 2.3129 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 3.1186 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 2.3993 4.9434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 2.8672 6.6104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 0.73387 3.6073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 1.5999 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 0.95917 3.6759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 35.517 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 2.5409 92.429 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
행에 값 할당하기
테이블에 하나의 행을 할당하려면, 행이 한 개 있는 테이블을 사용하거나 셀형 배열을 사용합니다. 여기서는 셀형 배열을 사용하는 것이 행이 한 개 있는 테이블을 만들어 할당하는 것보다 더 편리할 수 있습니다.
예를 들어, outages 맨 끝에서 새 행에 데이터를 할당합니다. 테이블의 맨 끝을 표시합니다.
outages(end+1,:) = {"East",datetime("now"),17.3,325,datetime("tomorrow"),"unknown"};
outages(end-2:end,:)ans=3×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ________ _________ ________________ _________________
"SouthEast" 2013-12-20 19:52 0.023096 0.10382 2013-12-20 23:29 "thunder storm"
"SouthEast" 2011-09-14 11:55 0.45042 1.1835 2011-09-14 13:28 "equipment fault"
"East" 2026-01-24 22:19 17.3 325 2026-01-25 00:00 "unknown"
여러 개의 행에 데이터를 할당하려면, 이름과 데이터형이 동일한 변수를 갖는 다른 테이블에 값을 할당합니다. 예를 들어, 두 행을 갖는 테이블을 새로 만듭니다.
newOutages = table(["West";"North"], ... datetime(2024,1,1:2)', ... [3;4], ... [300;400], ... datetime(2024,1,3:4)',["unknown";"unknown"], ... VariableNames=outages.Properties.VariableNames)
newOutages=2×6 table
Region OutageTime Loss Customers RestorationTime Cause
_______ ___________ ____ _________ _______________ _________
"West" 01-Jan-2024 3 300 03-Jan-2024 "unknown"
"North" 02-Jan-2024 4 400 04-Jan-2024 "unknown"
이 두 행의 테이블을 outages의 처음 2개 행에 할당합니다. 그런 다음 outages의 처음 4개 행을 표시합니다.
outages(1:2,:) = newOutages; outages(1:4,:)
ans=4×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ _________ ________________ _________________
"West" 2024-01-01 00:00 3 300 2024-01-03 00:00 "unknown"
"North" 2024-01-02 00:00 4 400 2024-01-04 00:00 "unknown"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
요소에 값 할당하기
테이블의 요소에 값을 할당하려면 중괄호를 사용합니다. 예를 들어, 처음 두 정전에 대한 원인을 할당합니다.
outages{1,"Cause"} = "severe storm";
outages{2,"Cause"} = "attack";
outages(1:4,:)ans=4×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ _________ ________________ _________________
"West" 2024-01-01 00:00 3 300 2024-01-03 00:00 "severe storm"
"North" 2024-01-02 00:00 4 400 2024-01-04 00:00 "attack"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
값이 조건을 충족하는 테이블 행 찾기
테이블에서 조건을 충족하는 값이 있는 행을 찾으려면 논리형 인덱싱을 사용합니다. 관심 있는 값을 갖는 테이블 변수를 지정하고, 이들 변수의 값이 지정된 조건을 충족하는 행 인덱스로 구성된 배열을 만듭니다. 행 인덱스를 사용하여 테이블의 요소를 참조합니다.
먼저, 스프레드시트의 정전 데이터를 테이블로 가져옵니다.
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
그런 다음, 변수가 조건을 충족하는 행에 상응하는 행 인덱스를 만듭니다. 예를 들어, 지역이 West인 행에 대한 인덱스를 만듭니다.
rows = matches(outages.Region,"West")rows = 1468×1 logical array
0
0
0
1
0
1
1
1
0
0
0
1
0
0
1
⋮
논리형 인덱스를 사용하여 테이블의 요소를 참조할 수 있습니다. 정전이 West 지역에서 발생한 경우에 해당하는 테이블의 행을 표시합니다.
outages(rows,:)
ans=354×6 table
Region OutageTime Loss Customers RestorationTime Cause
______ ________________ ______ __________ ________________ _________________
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"West" 2004-12-21 18:50 112.05 7.985e+05 2004-12-29 03:46 "winter storm"
"West" 2002-12-16 13:43 70.752 4.8193e+05 2002-12-19 09:38 "winter storm"
"West" 2005-06-29 08:37 601.13 32005 2005-06-29 08:57 "equipment fault"
"West" 2003-04-14 07:11 276.41 1.5647 2003-04-14 08:52 "equipment fault"
"West" 2003-10-21 17:25 235.12 51496 2003-10-21 19:43 "equipment fault"
"West" 2005-10-21 08:33 NaN 52639 2005-11-22 22:10 "fire"
"West" 2003-08-28 23:46 172.01 1.6964e+05 2003-09-03 02:10 "wind"
"West" 2005-03-01 14:39 115.47 82611 2005-03-03 05:58 "equipment fault"
"West" 2005-09-26 06:32 258.18 1.3996e+05 2005-09-26 06:33 "earthquake"
"West" 2003-12-22 03:40 232.26 3.9462e+05 2003-12-24 16:32 "winter storm"
⋮
하나의 논리식을 사용하여 여러 조건을 일치시킬 수 있습니다. 예를 들어, West 또는 MidWest 지역에서 정전으로 영향을 받은 고객이 1백만 명이 넘는 경우에 해당하는 행을 찾습니다.
rows = (outages.Customers > 1e6 & (matches(outages.Region,"West") | matches(outages.Region,"MidWest"))); outages(rows,:)
ans=10×6 table
Region OutageTime Loss Customers RestorationTime Cause
_________ ________________ ______ __________ ________________ _________________
"MidWest" 2002-12-10 10:45 14493 3.0879e+06 2002-12-11 18:06 "unknown"
"West" 2007-10-20 20:56 3537.5 1.3637e+06 2007-10-20 22:08 "equipment fault"
"West" 2006-12-28 14:04 804.05 1.5486e+06 2007-01-04 14:26 "severe storm"
"MidWest" 2006-07-16 00:05 1817.9 3.295e+06 2006-07-27 14:42 "severe storm"
"West" 2006-01-01 11:54 734.11 4.26e+06 2006-01-11 01:21 "winter storm"
"MidWest" 2008-09-19 23:31 4801.1 1.2151e+06 2008-10-03 14:04 "severe storm"
"MidWest" 2008-09-07 23:35 NaN 3.972e+06 2008-09-19 17:19 "severe storm"
"West" 2011-07-24 02:54 483.37 1.1212e+06 2011-07-24 12:18 "wind"
"West" 2010-01-24 18:47 348.91 1.8865e+06 2010-01-30 01:43 "severe storm"
"West" 2010-05-17 09:10 8496.6 2.0768e+06 2010-05-18 22:43 "equipment fault"
테이블 인덱싱 구문 요약
다음 표에는 각각의 테이블 인덱싱 구문이 모든 인덱싱 유형 및 결과 출력값과 함께 나열되어 있습니다. 위치, 이름 또는 데이터형을 사용하여 행과 변수를 지정할 수 있습니다.
선형 인덱싱은 지원되지 않습니다. 중괄호 또는 괄호를 사용하여 인덱싱하는 경우 행과 변수를 모두 지정해야 합니다.
변수 이름과 행 이름에는 공백과 비ASCII 문자까지 포함하여 모든 문자를 사용할 수 있습니다. 또한 영문자뿐만 아니라 어떤 문자로도 시작할 수 있습니다. 변수 이름과 행 이름은 유효한 MATLAB 식별자(유효 여부는
isvarname함수의 판정에 따름)가 아니어도 됩니다.이름을 사용하여 행이나 변수를 지정할 때
pattern객체를 사용하여 이름을 지정할 수 있습니다. 예를 들어,"Var" + digitsPattern은Var로 시작하고 임의 개수의 숫자로 끝나는 모든 이름과 일치합니다. (R2022a 이후)
출력값 | 구문 | 행 | 변수 | 예 |
|---|---|---|---|---|
하나의 변수에서 추출된 데이터를 갖는 배열 |
| 지정 안 함 | 지정 방법:
|
|
하나의 변수에서 추출된 데이터의 지정된 요소를 갖는 배열 |
| 지정 안 함 인덱스 | 지정 방법:
| 숫자형 또는 논리형 인덱스를 사용하여 배열 요소를 지정합니다. 추출된 배열이 행렬이거나 다차원 배열인 경우 여러 개의 숫자형 인덱스를 지정할 수 있습니다.
|
지정된 행과 변수에서 결합된 데이터로 구성된 배열 |
| 지정 방법:
| 지정 방법:
|
|
지정된 데이터형을 갖는 지정된 행과 변수를 결합한 데이터로 구성된 배열 |
| 지정 방법:
| 데이터형 첨자로 지정됨(예: |
|
모든 행과 변수를 결합한 데이터로 구성된 배열 |
| 지정 안 함 | 지정 안 함 |
|
지정된 행과 변수를 포함하는 테이블 |
| 지정 방법:
| 지정 방법:
|
|
지정된 데이터형을 갖는 지정된 행과 변수를 포함하는 테이블 |
| 지정 방법:
| 데이터형 첨자로 지정됨(예: |
|
참고 항목
table | readtable | vartype | matches