rmoutliers
데이터에서 이상값을 감지하여 제거
구문
설명
B = rmoutliers(A)A의 데이터에서 이상값을 감지하여 제거합니다.
A가 행렬인 경우rmoutliers는A의 각 열에서 이상값을 개별적으로 감지하고 그 행 전체를 제거합니다.A가 테이블 또는 타임테이블인 경우rmoutliers는A의 각 변수에서 이상값을 개별적으로 감지하고 그 행 전체를 제거합니다.
기본적으로, 이상값이란 중앙값에서 3 스케일링된 중앙값절대편차(MAD)를 초과해 떨어져 있는 값입니다.
라이브 스크립트에 이상값 데이터 정리 작업을 추가하여 rmoutliers 기능을 대화형 방식으로 사용할 수 있습니다.
B = rmoutliers(___,Name=Value)rmoutliers(A,SamplePoints=t)는 시간 벡터 t의 대응하는 요소를 기준으로 A의 이상값을 감지합니다.
예제
2개의 이상값이 들어 있는 벡터를 만들고 해당 이상값을 제거합니다.
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; B = rmoutliers(A)
B = 1×13
57 59 60 59 58 57 58 61 62 60 62 58 57
평균값 감지 방법을 사용하여 데이터 타임테이블에서 잠재적 이상값을 식별하고 이상값을 제거한 다음 정리된 데이터를 시각화합니다.
데이터 타임테이블을 만들고 데이터를 시각화하여 잠재적 이상값을 감지합니다.
T = hours(1:15); V = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; A = timetable(T',V'); plot(A.Time,A.Var1)

데이터에서 이상값을 제거합니다. 여기서 이상값은 평균에서 3 표준편차를 초과해 떨어져 있는 점으로 정의됩니다.
B = rmoutliers(A,"mean")B=14×1 timetable
Time Var1
_____ ____
1 hr 57
2 hr 59
3 hr 60
4 hr 100
5 hr 59
6 hr 58
7 hr 57
8 hr 58
10 hr 61
11 hr 62
12 hr 60
13 hr 62
14 hr 58
15 hr 57
같은 그래프에서 원래 데이터와 이상값이 제거된 데이터를 플로팅합니다.
hold on plot(B.Time,B.Var1,"o-") legend("Original Data","Cleaned Data")

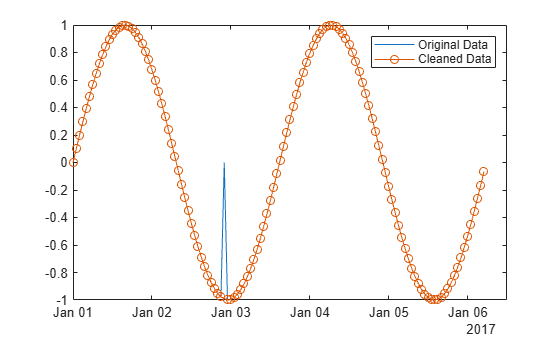
이동 중앙값을 사용하여 시간 벡터에 대응하는 사인파에서 국소 이상값을 감지하고 제거합니다.
국소 이상값이 포함된 데이터로 구성된 벡터를 만듭니다.
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
A의 데이터에 대응하는 시간 벡터를 만듭니다.
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
이상값을 슬라이딩 윈도우 내 국소 중앙값에서 3 국소 스케일링된 MAD를 초과하여 떨어져 있는 점으로 정의합니다. 윈도우 크기를 5시간으로 하여 t의 점을 기준으로 A에서 이상값의 위치를 찾아 제거합니다.
[B,TFrm] = rmoutliers(A,"movmedian",hours(5),SamplePoints=t);원래 데이터와 이상값이 제거된 데이터를 플로팅합니다.
plot(t,A) hold on plot(t(~TFrm),B,"o-") legend("Original Data","Cleaned Data")
두 개의 이상값이 포함된 행렬을 만들고 이상값을 제거합니다. 논리형 출력 벡터 TFrm을 반환하여 A의 어느 행이 제거되었는지 식별하고, 논리형 출력 배열 TFoutlier를 반환하여 A에서 이상값의 위치를 식별합니다.
A = [2 290 1 2; 1 0 323 1; 0 2 3 2; 1 1 2 3]
A = 4×4
2 290 1 2
1 0 323 1
0 2 3 2
1 1 2 3
[B,TFrm,TFoutlier] = rmoutliers(A)
B = 2×4
0 2 3 2
1 1 2 3
TFrm = 4×1 logical array
1
1
0
0
TFoutlier = 4×4 logical array
0 1 0 0
0 0 1 0
0 0 0 0
0 0 0 0
A에서 제거된 행의 값을 찾습니다.
rmCol = A(TFrm,:)
rmCol = 2×4
2 290 1 2
1 0 323 1
A에서 이상값을 찾습니다.
rmVal = A(TFoutlier)
rmVal = 2×1
290
323
데이터 행렬에서 이상값을 제거하고 제거된 열과 이상값을 검토합니다.
두 개의 이상값이 포함된 행렬을 만듭니다.
A = [1 1 1; 1 100 1; 1 100 1; 1 1 100; 1 1 1]
A = 5×3
1 1 1
1 100 1
1 100 1
1 1 100
1 1 1
rmoutliers를 사용하여 A의 각 열을 따라 이상값을 감지하고 적어도 하나의 이상값을 포함하는 모든 행을 제거합니다.
B = rmoutliers(A)
B = 2×3
1 1 1
1 1 1
rmoutliers를 사용하여 A의 각 열을 따라 이상값을 감지하고 적어도 하나의 이상값을 포함하는 모든 열을 제거합니다. dim을 2로 지정하면 두 번째 차원의 데이터 크기가 줄어듭니다.
B = rmoutliers(A,2)
B = 5×1
1
1
1
1
1
2개의 이상값이 들어 있는 벡터를 만들고 위치를 감지합니다.
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; detect = isoutlier(A)
detect = 1×15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
이상값을 제거합니다. 감지 방법을 사용하는 대신 isoutlier에서 감지한 이상값 위치를 제공합니다.
B = rmoutliers(A,OutlierLocations=detect)
B = 1×13
57 59 60 59 58 57 58 61 62 60 62 58 57
데이터로 구성된 벡터에서 이상값을 제거하고 정리된 데이터를 시각화합니다.
이상값이 포함된 데이터로 구성된 벡터를 만듭니다.
A = [60 59 49 49 58 100 61 57 48 58];
디폴트 감지 방법 "median"을 사용하여 이상값을 제거합니다.
[B,TFrm,TFoutlier,L,U,C] = rmoutliers(A);
원래 데이터, 이상값이 제거된 데이터, 감지 방법에 의해 결정된 임계값과 중심값을 플로팅합니다. 중심값은 데이터의 중앙값이며, 상한/하한 임계값은 중앙값으로부터 3 스케일링된 MAD만큼 위 그리고 아래에 있는 값입니다.
plot(A) hold on plot(find(~TFrm),B,"o-") yline([L U C],":",["Lower Threshold","Upper Threshold","Center Value"]) legend("Original Data","Cleaned Data")

R2024b 이후
테이블을 만들고 10보다 큰 값으로 정의된 이상값을 제거합니다. 제거할 이상값의 위치를 나타내는 논리형 변수 loc의 테이블을 만듭니다. 그런 다음 OutlierLocations 이름-값 인수를 사용하여 rmoutliers의 알려진 이상값 위치를 지정합니다.
A = [1; 4; 9; 12; 3]; B = [9; 0; 6; 2; 1]; C = [14; 4; 2; 3; 8]; T = table(A,B,C)
T=5×3 table
A B C
__ _ __
1 9 14
4 0 4
9 6 2
12 2 3
3 1 8
loc = T>10
loc=5×3 table
A B C
_____ _____ _____
false false true
false false false
false false false
true false false
false false false
T = rmoutliers(T,OutlierLocations=loc)
T=3×3 table
A B C
_ _ _
4 0 4
9 6 2
3 1 8
입력 인수
이름-값 인수
출력 인수
세부 정보
다음 표에서는 균일한 간격을 갖는 디폴트 샘플 점 벡터 [1 2 3 4 5 6 7]에서의 윈도우 위치를 보여줍니다.
설명 | 윈도우 크기와 위치 | 윈도우에서의 샘플 점 | 다이어그램 |
|---|---|---|---|
스칼라 윈도우 크기의 경우, 윈도우의 앞쪽 경계값은 제외되고 윈도우의 뒤쪽 경계값은 포함됩니다. |
현재 샘플 점 = 4 | 3, 4, 5 |
|
현재 샘플 점 = 4 | 2, 3, 4, 5 |
| |
벡터 윈도우 크기의 경우, 앞쪽 경계값과 뒤쪽 경계값이 포함됩니다. |
현재 샘플 점 = 4 | 2, 3, 4, 5, 6 |
|
입력 데이터의 끝점 근처에 있는 샘플 점의 경우, |
현재 샘플 점 = 2 | 1, 2, 3, 4 |
|


![Given elements 1 to 7, if the current sample point is 4, then the corresponding window spans the range [2, 6].](movwindow_vector.png)
![Given elements 1 to 7, if the current sample point is 2, then the corresponding window spans the range [1, 4].](movwindow_edgetruncate.png)
