histogram2
이변량 히스토그램 플롯

설명
이변량 히스토그램은 데이터를 2차원 Bin으로 그룹화하는 숫자형 데이터의 막대 플롯 유형입니다. Histogram2 객체를 생성한 후 해당 속성값을 변경하여 히스토그램의 여러 특성을 수정할 수 있습니다. 이는 Bin의 속성을 빠르게 수정하거나 화면표시를 빠르게 변경하려는 경우 특히 유용합니다.
생성
구문
설명
histogram2(는 X,Y)X와 Y에 대한 이변량 히스토그램 플롯을 생성합니다. histogram2 함수는 자동 비닝(Binning) 알고리즘을 사용합니다. 이 알고리즘은 X와 Y에 있는 요소의 범위를 포괄하고 분포의 기본 형태를 표시하도록 선택된, 균일한 면적의 Bin을 반환합니다. histogram2는 3차원 사각형 막대로 Bin을 표시하고, 각 막대의 높이는 Bin의 요소 개수를 나타냅니다.
histogram2(___,는 위에 열거된 구문에서 하나 이상의 이름-값 인수를 사용하여 추가적인 파라미터를 지정합니다. 예를 들어, 다른 유형의 정규화를 사용하려면 Name,Value)Normalization을 지정합니다. 속성 목록은 Histogram2 속성를 참조하십시오.
histogram2(는 현재 좌표축(ax,___)gca) 대신 지정된 좌표축에 플로팅합니다. ax는 위에 열거된 구문의 입력 인수 조합보다 먼저 나올 수 있습니다.
h = histogram2(___)Histogram2 객체를 반환합니다. 이 함수를 사용하면 이변량 히스토그램의 속성을 확인하고 조정할 수 있습니다. 속성 목록은 Histogram2 속성를 참조하십시오.
입력 인수
이름-값 인수
선택적 인수 쌍을 Name1=Value1,...,NameN=ValueN으로 지정합니다. 여기서 Name은 인수 이름이고 Value는 대응값입니다. 이름-값 인수는 다른 인수 뒤에 와야 하지만, 인수 쌍의 순서는 상관없습니다.
예: histogram2(X,Y,BinWidth=[5 10])
R2021a 이전 릴리스에서는 쉼표를 사용하여 각 이름과 값을 구분하고 Name을 따옴표로 묶으십시오.
예: histogram2(X,Y,'BinWidth',[5 10])
참고
여기에 나와 있는 속성은 일부에 불과합니다. 전체 목록을 보려면 Histogram2 속성를 참조하십시오.
Bin
데이터
색과 스타일 지정
히스토그램 표시 스타일로, 'bar3' 또는 'tile'로 지정됩니다.
'bar3'— 3차원 막대를 사용하여 히스토그램을 표시합니다.'tile'— Bin 값을 색으로 표현한, 타일로 구성된 사각형 배열로 히스토그램을 표시합니다.
예: histogram2(X,Y,'DisplayStyle','tile')은 타일로 구성된 사각형 배열로 히스토그램을 플로팅합니다.
히스토그램 막대 색으로, 다음 값 중 하나로 지정됩니다.
'none'— 막대가 채워지지 않습니다.'flat'— 막대 색이 높이에 따라 달라집니다. 막대는 높이에 따라 다른 색으로 표시됩니다. 색은 Figure 컬러맵이나 좌표축 컬러맵에서 선택됩니다.'auto'— 히스토그램 막대 색이 자동으로 선택됩니다(디폴트 값).RGB 3색, 16 진수 색 코드 또는 색 이름 — 막대가 지정된 색으로 채워집니다.
RGB 3색과 16진수 색 코드는 사용자 지정 색을 지정할 때 유용합니다.
RGB 3색은 요소를 3개 가진 행 벡터로, 각 요소는 색을 구성하는 빨간색, 녹색, 파란색의 농도를 지정합니다. 농도의 범위는
[0,1]이어야 합니다(예:[0.4 0.6 0.7]).16진수 색 코드는 문자형 벡터 또는 string형 스칼라로, 해시 기호(
#)로 시작하고 그 뒤에 3자리 또는 6자리의 16진수 숫자(0에서F사이일 수 있음)가 옵니다. 이 값은 대/소문자를 구분하지 않습니다. 따라서 색 코드"#FF8800","#ff8800","#F80"및"#f80"은 모두 동일합니다.
몇몇의 흔한 색은 이름으로 지정할 수도 있습니다. 다음 표에는 명명된 색 옵션과 그에 해당하는 RGB 3색 및 16진수 색 코드가 나와 있습니다.
색 이름 짧은 이름 RGB 3색 16진수 색 코드 모양 "red""r"[1 0 0]"#FF0000"
"green""g"[0 1 0]"#00FF00"
"blue""b"[0 0 1]"#0000FF"
"cyan""c"[0 1 1]"#00FFFF"
"magenta""m"[1 0 1]"#FF00FF"
"yellow""y"[1 1 0]"#FFFF00"
"black""k"[0 0 0]"#000000"
"white""w"[1 1 1]"#FFFFFF"
다음 표에는 라이트 테마와 다크 테마에서 플롯의 디폴트 색 팔레트가 나열되어 있습니다.
팔레트 팔레트 색 "gem"— 라이트 테마 디폴트 값R2025a 이전: 대부분의 플롯은 기본적으로 이 색을 사용합니다.

"glow"— 다크 테마 디폴트 값
orderedcolors함수와rgb2hex함수를 사용하여 이러한 팔레트의 RGB 3색과 16진수 색 코드를 가져올 수 있습니다. 예를 들어,"gem"팔레트의 RGB 3색을 가져와서 16진수 색 코드로 변환해 보겠습니다.RGB = orderedcolors("gem"); H = rgb2hex(RGB);R2023b 이전:
RGB = get(groot,"FactoryAxesColorOrder")를 사용하여 RGB 3색을 가져옵니다.R2024a 이전:
H = compose("#%02X%02X%02X",round(RGB*255))를 사용하여 16진수 색 코드를 가져옵니다.
DisplayStyle을 'tile'로 지정하면 FaceColor 속성이 'flat'으로 설정됩니다.
예: histogram2(X,Y,'FaceColor','g')
히스토그램 가장자리 색으로, 다음 값 중 하나로 지정됩니다.
'none'— 가장자리가 그려지지 않습니다.'auto'— 각 가장자리의 색이 자동으로 선택됩니다.RGB 3색, 16진수 색 코드 또는 색 이름 — 지정된 색이 가장자리에 사용됩니다.
RGB 3색과 16진수 색 코드는 사용자 지정 색을 지정할 때 유용합니다.
RGB 3색은 요소를 3개 가진 행 벡터로, 각 요소는 색을 구성하는 빨간색, 녹색, 파란색의 농도를 지정합니다. 농도의 범위는
[0,1]이어야 합니다(예:[0.4 0.6 0.7]).16진수 색 코드는 문자형 벡터 또는 string형 스칼라로, 해시 기호(
#)로 시작하고 그 뒤에 3자리 또는 6자리의 16진수 숫자(0에서F사이일 수 있음)가 옵니다. 이 값은 대/소문자를 구분하지 않습니다. 따라서 색 코드"#FF8800","#ff8800","#F80"및"#f80"은 모두 동일합니다.
몇몇의 흔한 색은 이름으로 지정할 수도 있습니다. 다음 표에는 명명된 색 옵션과 그에 해당하는 RGB 3색 및 16진수 색 코드가 나와 있습니다.
색 이름 짧은 이름 RGB 3색 16진수 색 코드 모양 "red""r"[1 0 0]"#FF0000""green""g"[0 1 0]"#00FF00""blue""b"[0 0 1]"#0000FF""cyan""c"[0 1 1]"#00FFFF""magenta""m"[1 0 1]"#FF00FF""yellow""y"[1 1 0]"#FFFF00""black""k"[0 0 0]"#000000""white""w"[1 1 1]"#FFFFFF"다음 표에는 라이트 테마와 다크 테마에서 플롯의 디폴트 색 팔레트가 나열되어 있습니다.
팔레트 팔레트 색 "gem"— 라이트 테마 디폴트 값R2025a 이전: 대부분의 플롯은 기본적으로 이 색을 사용합니다.
"glow"— 다크 테마 디폴트 값orderedcolors함수와rgb2hex함수를 사용하여 이러한 팔레트의 RGB 3색과 16진수 색 코드를 가져올 수 있습니다. 예를 들어,"gem"팔레트의 RGB 3색을 가져와서 16진수 색 코드로 변환해 보겠습니다.RGB = orderedcolors("gem"); H = rgb2hex(RGB);R2023b 이전:
RGB = get(groot,"FactoryAxesColorOrder")를 사용하여 RGB 3색을 가져옵니다.R2024a 이전:
H = compose("#%02X%02X%02X",round(RGB*255))를 사용하여 16진수 색 코드를 가져옵니다.
예: histogram2(X,Y,'EdgeColor','r')
히스토그램 막대의 조명 효과로, 다음 값 중 하나로 지정됩니다.
| 값 | 설명 |
|---|---|
'lit' | 히스토그램 막대의 측면에 상단보다 어두운 색을 사용하여 의사 조명 효과(Pseudo-lighting Effect)를 줍니다. 좌표축의 다른 광원은 막대에 영향을 미치지 않습니다. 이는 |
'flat' | 히스토그램 막대에 자동으로 조명 효과가 적용되지 않습니다. 다른 light 객체가 있을 경우 해당 조명 효과는 막대 면 전체에 균일하게 적용됩니다. |
'none' | 히스토그램 막대에 자동으로 조명 효과가 적용되지 않고, 조명이 히스토그램 막대에 영향을 미치지 않습니다.
|
예: histogram2(X,Y,'FaceLighting','none')은 히스토그램 막대의 조명을 끕니다.
선 스타일로, 다음 표에 나열된 옵션 중 하나로 지정됩니다.
| 선 스타일 | 설명 | 결과 선 |
|---|---|---|
"-" | 실선 |
|
"--" | 파선 |
|
":" | 점선 |
|
"-." | 일점 쇄선 |
|
"none" | 선 없음 | 선 없음 |




출력 인수
속성
| Histogram2 속성 | 이변량 히스토그램의 모양과 동작 |
예제
10,000개의 난수 쌍을 생성하고 이변량 히스토그램을 만듭니다. histogram2 함수는 x와 y의 값 범위를 포괄하고 기본 분포의 형태를 표시하는 데 적합한 Bin 개수를 자동으로 선택합니다.
x = randn(10000,1); y = randn(10000,1); h = histogram2(x,y)
h =
Histogram2 with properties:
Data: [10000×2 double]
Values: [25×28 double]
NumBins: [25 28]
XBinEdges: [-3.9000 -3.6000 -3.3000 -3 -2.7000 -2.4000 -2.1000 -1.8000 -1.5000 -1.2000 -0.9000 -0.6000 -0.3000 0 0.3000 0.6000 0.9000 1.2000 1.5000 1.8000 2.1000 2.4000 2.7000 3.0000 3.3000 3.6000]
YBinEdges: [-4.2000 -3.9000 -3.6000 -3.3000 -3.0000 -2.7000 -2.4000 -2.1000 -1.8000 -1.5000 -1.2000 -0.9000 -0.6000 -0.3000 0 0.3000 0.6000 0.9000 1.2000 1.5000 1.8000 2.1000 2.4000 2.7000 3 3.3000 3.6000 3.9000 4.2000]
BinWidth: [0.3000 0.3000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
xlabel('x') ylabel('y')
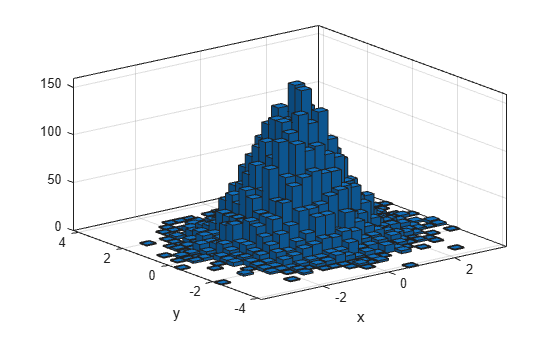
histogram2 함수에 대한 출력 인수를 지정하면 이 함수는 histogram2 객체를 반환합니다. 이 객체를 사용하여 Bin 개수나 Bin 너비 등의 histogram 속성을 검사할 수 있습니다.
각 차원에 포함되는 히스토그램 Bin의 개수를 구합니다.
nXnY = h.NumBins
nXnY = 1×2
25 28
1,000개의 난수 쌍이 균일한 간격의 25개 Bin으로 분류된 이변량 히스토그램을 각 차원에 5개의 Bin을 사용하여 플로팅합니다.
x = randn(1000,1); y = randn(1000,1); nbins = 5; h = histogram2(x,y,nbins)
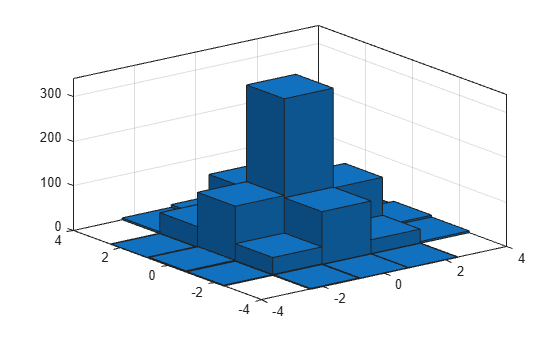
h =
Histogram2 with properties:
Data: [1000×2 double]
Values: [5×5 double]
NumBins: [5 5]
XBinEdges: [-4 -2.4000 -0.8000 0.8000 2.4000 4]
YBinEdges: [-4 -2.4000 -0.8000 0.8000 2.4000 4]
BinWidth: [1.6000 1.6000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
결과 Bin 도수를 구합니다.
counts = h.Values
counts = 5×5
0 2 3 1 0
2 40 124 47 4
1 119 341 109 10
1 32 117 33 1
0 4 8 1 0
1,000개의 난수 쌍을 생성하고 이변량 히스토그램을 만듭니다.
x = randn(1000,1); y = randn(1000,1); h = histogram2(x,y)
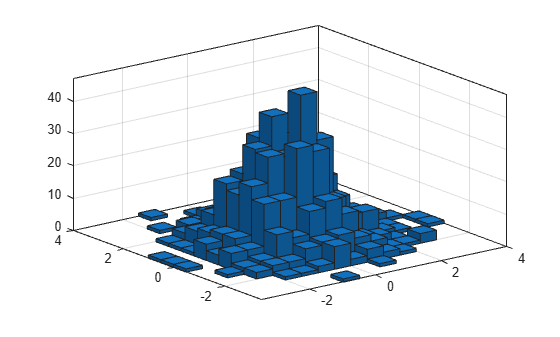
h =
Histogram2 with properties:
Data: [1000×2 double]
Values: [15×15 double]
NumBins: [15 15]
XBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
YBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
BinWidth: [0.5000 0.5000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
morebins 함수를 사용하여 x 차원의 Bin 개수를 성기게 조정합니다.
nbins = morebins(h,'x'); nbins = morebins(h,'x')
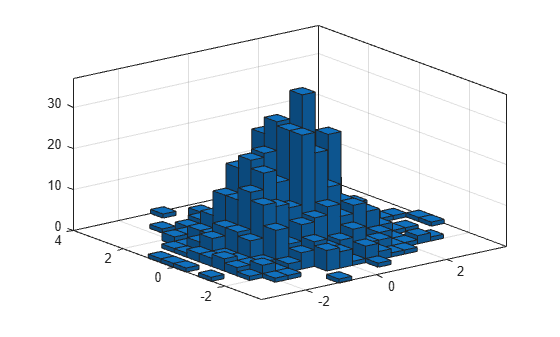
nbins = 1×2
19 15
fewerbins 함수를 사용하여 y 차원의 Bin 개수를 조정합니다.
nbins = fewerbins(h,'y'); nbins = fewerbins(h,'y')
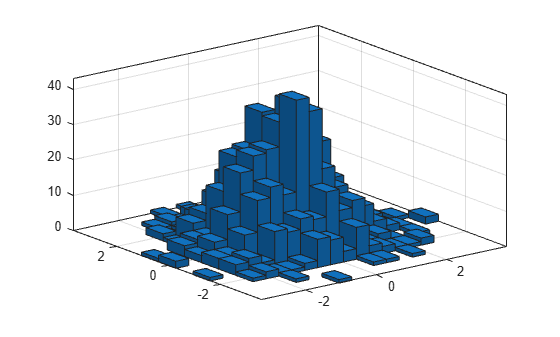
nbins = 1×2
19 11
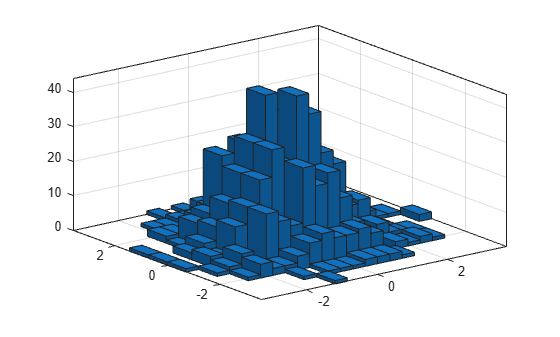
Bin 개수를 명시적으로 설정하여 Bin 개수를 정교하게 조정합니다.
h.NumBins = [20 10];
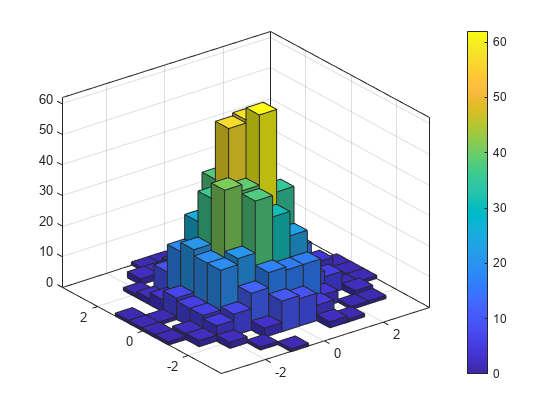
각 차원에 12개의 Bin을 구성하고 1,000개의 정규분포된 난수를 사용하여 이변량 히스토그램을 생성합니다. FaceColor를 'flat'으로 지정하여 높이를 기준으로 히스토그램 막대의 색을 적용합니다.
h = histogram2(randn(1000,1),randn(1000,1),[12 12],'FaceColor','flat'); colorbar
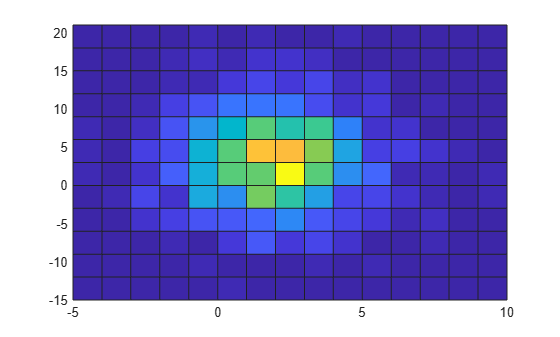
랜덤 데이터를 생성하고 이변량 타일 형식 히스토그램을 플로팅합니다. ShowEmptyBins를 'on'으로 지정하여 비어 있는 Bin을 표시합니다.
x = 2*randn(1000,1)+2; y = 5*randn(1000,1)+3; h = histogram2(x,y,'DisplayStyle','tile','ShowEmptyBins','on');
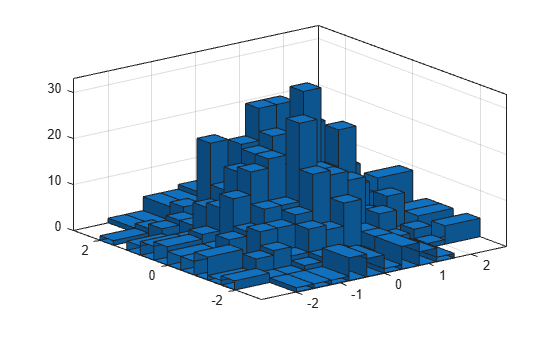
1,000개의 난수 쌍을 생성하고 이변량 히스토그램을 만듭니다. 히스토그램의 경계에 무한대로 넓은 Bin을 갖는 2개의 벡터로 Bin 경계값을 지정하여 를 충족하지 않는 모든 이상값을 캡처합니다.
x = randn(1000,1); y = randn(1000,1); Xedges = [-Inf -2:0.4:2 Inf]; Yedges = [-Inf -2:0.4:2 Inf]; h = histogram2(x,y,Xedges,Yedges)
h =
Histogram2 with properties:
Data: [1000×2 double]
Values: [12×12 double]
NumBins: [12 12]
XBinEdges: [-Inf -2 -1.6000 -1.2000 -0.8000 -0.4000 0 0.4000 0.8000 1.2000 1.6000 2 Inf]
YBinEdges: [-Inf -2 -1.6000 -1.2000 -0.8000 -0.4000 0 0.4000 0.8000 1.2000 1.6000 2 Inf]
BinWidth: 'nonuniform'
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
Bin 경계값이 무한대이면 histogram2는 (히스토그램의 경계를 따라) 각 이상값 Bin을 옆에 있는 Bin의 2배 너비로 표시합니다.
Normalization 속성을 'countdensity'로 지정하여 이상값을 포함하는 Bin을 제거합니다. 이제, 각 Bin의 체적은 해당 구간에서의 관측값 빈도(도수)를 나타냅니다.
h.Normalization = 'countdensity';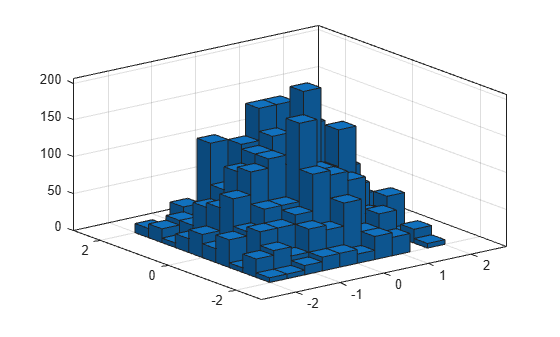
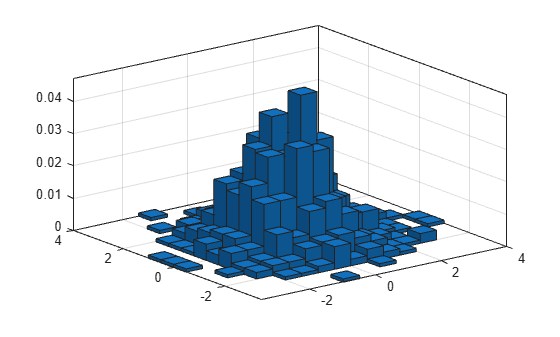
1,000개의 난수 쌍을 생성하고 'probability' 정규화를 사용하여 이변량 히스토그램을 만듭니다.
x = randn(1000,1); y = randn(1000,1); h = histogram2(x,y,'Normalization','probability')
h =
Histogram2 with properties:
Data: [1000×2 double]
Values: [15×15 double]
NumBins: [15 15]
XBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
YBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
BinWidth: [0.5000 0.5000]
Normalization: 'probability'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
모든 막대의 높이의 총합을 계산합니다. 이 정규화를 사용할 경우 각 막대의 높이는 해당 Bin 구간 내에서 관측값을 선택할 확률과 동일하며, 모든 막대 높이의 합은 1입니다.
S = sum(h.Values(:))
S = 1
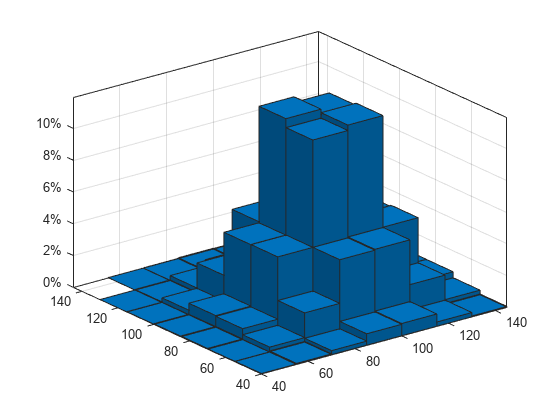
100,000개의 정규분포된 확률 벡터를 생성합니다. 표준편차 15, 평균 100과 85를 사용합니다.
x = [100 85] + 15*randn(1e5,2);
확률 벡터의 히스토그램을 플로팅합니다. z축을 백분율로 스케일링하고 레이블을 지정합니다.
edges = 40:15:145; histogram2(x(:,1),x(:,2),edges,edges,Normalization="percentage") ztickformat("percentage")
1,000개의 난수 쌍을 생성하고 이변량 히스토그램을 만듭니다. histogram 객체를 반환하여, 전체 플롯을 다시 생성하지 않고 histogram의 속성을 조정합니다.
x = randn(1000,1); y = randn(1000,1); h = histogram2(x,y)
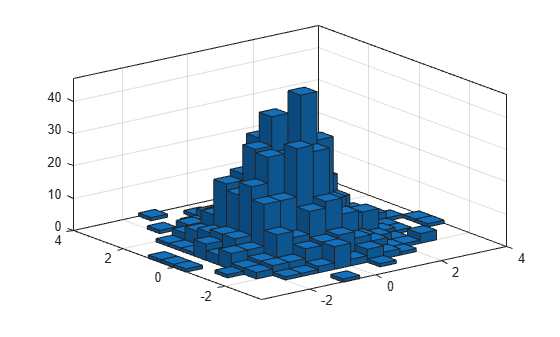
h =
Histogram2 with properties:
Data: [1000×2 double]
Values: [15×15 double]
NumBins: [15 15]
XBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
YBinEdges: [-3.5000 -3 -2.5000 -2 -1.5000 -1 -0.5000 0 0.5000 1 1.5000 2 2.5000 3 3.5000 4]
BinWidth: [0.5000 0.5000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
높이를 기준으로 히스토그램 막대의 색을 지정합니다.
h.FaceColor = 'flat';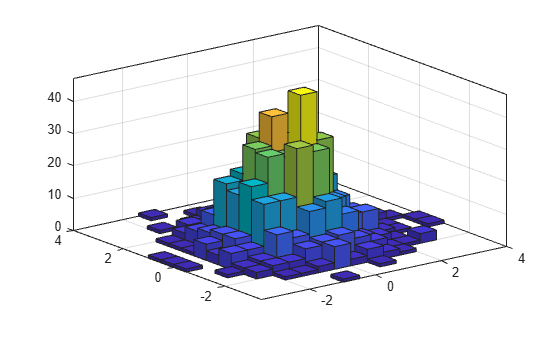
각 방향의 Bin 개수를 변경합니다.
h.NumBins = [10 25];
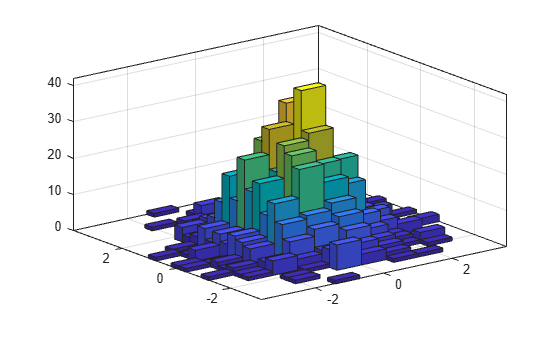
히스토그램을 타일 플롯으로 표시합니다.
h.DisplayStyle = 'tile';
view(2)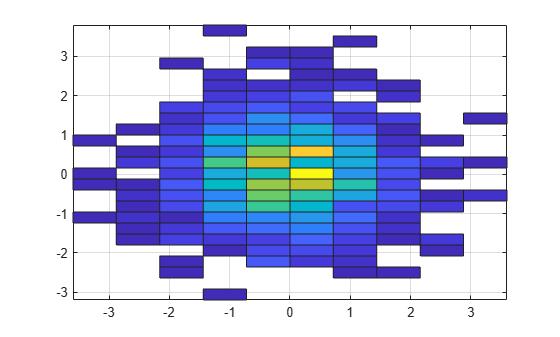
savefig 함수를 사용하여 histogram2 Figure를 저장합니다.
histogram2(randn(100,1),randn(100,1)); savefig('histogram2.fig'); close gcf
openfig를 사용하여 히스토그램 Figure를 다시 MATLAB®으로 불러옵니다. openfig는 또한 Figure에 대한 핸들 h를 반환합니다.
h = openfig('histogram2.fig');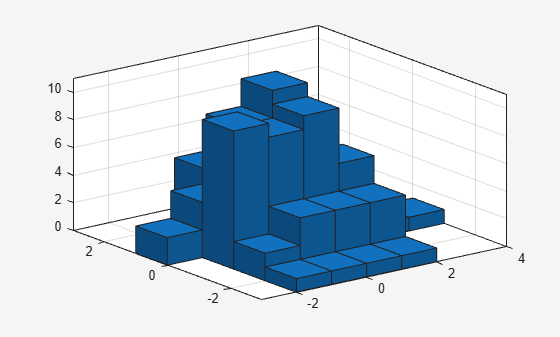
findobj 함수를 사용하여 figure 핸들에서 올바른 객체 핸들을 찾습니다. 이로서 Figure를 생성하는 데 사용된 원래 히스토그램 객체를 계속 조작할 수 있습니다.
y = findobj(h,'type','histogram2')
y =
Histogram2 with properties:
Data: [100×2 double]
Values: [7×6 double]
NumBins: [7 6]
XBinEdges: [-3 -2 -1 0 1 2 3 4]
YBinEdges: [-3 -2 -1 0 1 2 3]
BinWidth: [1 1]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0.1294 0.1294 0.1294]
Show all properties
팁
histogram2를 사용하여 생성된 히스토그램 플롯의 경우 플롯 편집 모드에서 상황별 메뉴가 제공됩니다. 이 메뉴를 통해 Figure 창에서 대화형 방식으로 조작을 수행할 수 있습니다. 예를 들어, 상황별 메뉴를 사용하여 대화형 방식으로 Bin의 개수를 변경하거나, 여러 히스토그램을 정렬하거나, 디스플레이 순서를 변경할 수 있습니다.
확장 기능
버전 내역
R2015b에 개발됨참고 항목
Histogram2 속성 | bar3 | discretize | fewerbins | morebins | histcounts2 | histcounts