categorical
범주에 할당된 값을 포함하는 배열
설명
categorical은 High, Med, Low와 같은 유한한 이산 범주 집합에 값을 할당하는 데이터형입니다. 이러한 범주에는 High > Med > Low와 같은 수학적 정렬을 적용할 수 있으며, 이것은 필수 사항이 아닙니다. categorical형 배열을 사용하면 숫자형이 아닌 데이터를 효율적으로 저장하고 편리하게 조작하는 한편, 값에 의미 있는 이름을 부여할 수 있습니다. categorical형 배열은 흔히 테이블에서 행 그룹을 정의하는 데 사용됩니다.
생성
categorical형 배열을 만들려면 다음을 수행하십시오.
아래에 설명된 대로
categorical함수를 사용합니다.discretize함수를 사용하여 연속 데이터를 비닝합니다. Bin을 categorical형 배열로 반환합니다.두 categorical형 배열을 곱합니다. 곱은 categorical형 배열이며 곱의 범주는 두 피연산자 범주의 가능한 모든 조합으로 구성됩니다.
구문
설명
C = categorical(A,___,Name=Value)Ordinal을 true로 설정합니다.
입력 인수
이름-값 인수
출력 인수
예제
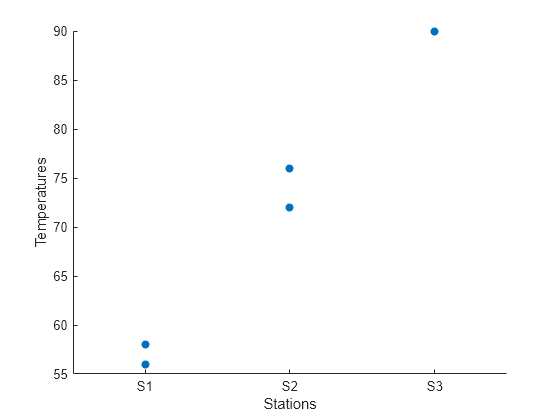
기상 관측소 코드 목록으로부터 categorical형 배열을 만듭니다. 그런 다음 이 배열을 온도 측정값 테이블에 추가합니다. categorical형 배열을 사용하면 테이블의 데이터를 범주별로 쉽게 분석할 수 있습니다.
먼저 기상 관측소 코드로 구성된 배열을 만듭니다.
Stations = ["S1" "S2" "S1" "S3" "S2"]
Stations = 1×5 string
"S1" "S2" "S1" "S3" "S2"
기상 관측소 코드로부터 categorical형 배열을 생성하려면 categorical 함수를 사용합니다.
Stations = categorical(Stations)
Stations = 1×5 categorical
S1 S2 S1 S3 S2
범주를 표시합니다. 세 개의 관측소 코드가 범주입니다.
categories(Stations)
ans = 3×1 cell
{'S1'}
{'S2'}
{'S3'}
이제 기상 데이터가 포함된 테이블을 만듭니다. 테이블에는 기온, 날짜, 관측소 코드가 있습니다.
Temperatures = [58;72;56;90;76]; Dates = datetime(["2017-04-17";"2017-04-18";"2017-04-30";"2017-05-01";"2017-04-27"]); Stations = Stations'; tempReadings = table(Temperatures,Dates,Stations)
tempReadings=5×3 table
Temperatures Dates Stations
____________ ___________ ________
58 17-Apr-2017 S1
72 18-Apr-2017 S2
56 30-Apr-2017 S1
90 01-May-2017 S3
76 27-Apr-2017 S2
기상 관측소별로 테이블의 데이터를 분류합니다. 예를 들어, 관측소 S2의 데이터가 있는 테이블 행을 반환합니다. 논리형 인덱스로 구성된 배열을 사용하여 Stations가 S2인 테이블의 요소를 참조합니다.
TF = (tempReadings.Stations == "S2")TF = 5×1 logical array
0
1
0
0
1
tempReadings(TF,:)
ans=2×3 table
Temperatures Dates Stations
____________ ___________ ________
72 18-Apr-2017 S2
76 27-Apr-2017 S2
기상 관측소와 관련된 데이터에서 패턴을 찾으려면 관측소별 온도 측정값으로 구성된 산점도 플롯을 만듭니다.
scatter(tempReadings,"Stations","Temperatures","filled")
string형 배열을 categorical형 배열로 변환합니다. categorical형 배열에 원래 배열에 없는 값을 포함하는 범주 집합이 있음을 지정합니다.
먼저, 반복되는 값의 집합을 갖는 string형 배열을 만듭니다.
A = ["red" "blue" "blue" "blue" "blue" "red"]
A = 1×6 string
"red" "blue" "blue" "blue" "blue" "red"
string형 배열을 categorical형 배열로 변환합니다. 범주를 지정합니다. green을 범주로 포함합니다.
valueset = ["blue" "red" "green"]; C = categorical(A,valueset)
C = 1×6 categorical
red blue blue blue blue red
categorical형 배열의 범주를 표시합니다. 이 배열에는 입력 string형 배열에서 가져오지 않은 범주가 있습니다.
categories(C)
ans = 3×1 cell
{'blue' }
{'red' }
{'green'}
숫자형 배열을 만듭니다.
A = [1 3 2; 2 1 3; 3 1 2]
A = 3×3
1 3 2
2 1 3
3 1 2
숫자형 배열을 categorical형 배열로 변환합니다. 범주의 값과 이름을 지정합니다.
C = categorical(A,[1 2 3],["red" "green" "blue"])
C = 3×3 categorical
red blue green
green red blue
blue red green
범주를 표시합니다.
categories(C)
ans = 3×1 cell
{'red' }
{'green'}
{'blue' }
C는 순서형 categorical형 배열이 아닙니다. 따라서, C에 있는 값은 등호 연산자 ==와 ~=만 사용하여 비교할 수 있습니다.
범주 red에 속하는 요소를 찾습니다. 논리형 인덱싱을 사용하여 찾은 요소에 액세스합니다.
TF = (C == "red")TF = 3×3 logical array
1 0 0
0 1 0
0 1 0
C(TF)
ans = 3×1 categorical
red
red
red
기본적으로 categorical 함수는 누락값(예: NaN, NaT, 빈 string형, 누락값인 string형)을 정의되지 않은 categorical형 값으로 변환합니다. 하지만 categorical을 호출하면 누락값이 속할 범주를 지정할 수 있습니다.
예를 들어, 빈 string형과 누락값인 string형을 포함하는 string형 배열을 생성합니다.
A = ["hi" "lo" missing "" "lo" "lo" "hi"]
A = 1×7 string
"hi" "lo" <missing> "" "lo" "lo" "hi"
먼저 string형 배열을 정의되지 않은 요소가 있는 categorical형 배열로 변환합니다.
C = categorical(A)
C = 1×7 categorical
hi lo <undefined> <undefined> lo lo hi
categories(C)
ans = 2×1 cell
{'hi'}
{'lo'}
그런 다음 그 배열을 다시 변환합니다. 이번에는 누락값인 string형에 대한 범주로 INDEF를 지정합니다.
C = categorical(A,["lo" "hi" missing],["lo" "hi" "INDEF"])
C = 1×7 categorical
hi lo INDEF <undefined> lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
누락값인 string형과 빈 string형 모두에 대한 범주로 INDEF를 지정합니다.
C = categorical(A,["lo" "hi" missing ""],["lo" "hi" "INDEF" "INDEF"])
C = 1×7 categorical
hi lo INDEF INDEF lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
5×2 숫자형 배열을 만듭니다.
A = [3 2;3 3;3 2;2 1;3 2]
A = 5×2
3 2
3 3
3 2
2 1
3 2
A를 1, 2, 3으로 범주 child, adult, senior를 각각 나타내는 순서형 categorical형 배열로 변환합니다.
valueset = [1 2 3]; catnames = ["child" "adult" "senior"]; C = categorical(A,valueset,catnames,Ordinal=true)
C = 5×2 categorical
senior adult
senior senior
senior adult
adult child
senior adult
C가 순서형 배열이므로, C의 범주에는 수학적 정렬인 child < adult < senior가 적용됩니다. 순서형 categorical형 값에 모든 관계 연산자를 사용할 수 있습니다. 예를 들어, adult보다 큰 값을 갖는 요소를 반환합니다.
TF = C > "adult"TF = 5×2 logical array
1 0
1 1
1 0
0 0
1 0
C(TF)
ans = 5×1 categorical
senior
senior
senior
senior
senior
NaN으로 구성된 배열을 만들고 이 배열을 categorical형 배열로 변환하여 임의 크기의 categorical형 배열을 사전할당할 수 있습니다. 배열을 사전할당한 후에는 범주 이름을 지정하고 범주를 배열에 추가하여 해당 범주를 초기화할 수 있습니다.
먼저 NaN으로 구성된 배열을 만듭니다. 임의 크기의 배열을 만들 수 있습니다. 예를 들어, NaN으로 구성된 2×4 배열을 만듭니다.
A = NaN(2,4)
A = 2×4
NaN NaN NaN NaN
NaN NaN NaN NaN
그런 다음 NaN으로 구성된 배열을 변환하여 categorical형 배열을 사전할당합니다. categorical 함수는 NaN을 정의되지 않은 categorical형 값으로 변환합니다. NaN이 "숫자가 아님(Not-a-Number)"을 나타내는 것처럼 <undefined>는 범주에 속하지 않는 categorical형 값을 나타냅니다.
C = categorical(A)
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
실제로 이 시점에서 C는 범주가 없습니다.
categories(C)
ans = 0×0 empty cell array
C 범주를 초기화하려면 addcats 함수를 사용하여 범주 이름을 지정하고 이를 C에 추가합니다. 예를 들어 small, medium, large를 3개의 C 범주로 추가합니다.
C = addcats(C,["small" "medium" "large"])
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
C의 요소는 정의되지 않은 값인 반면, 해당 범주는 addcats로 초기화하였습니다.
categories(C)
ans = 3×1 cell
{'small' }
{'medium'}
{'large' }
이제 C에 범주가 있으므로 정의된 categorical형 값을 C 요소로 할당할 수 있습니다.
C(1) = "medium"; C(8) = "small"; C(3:5) = "large"
C = 2×4 categorical
medium large large <undefined>
<undefined> large <undefined> small
discretize 함수는 연속 데이터에서 범주를 만드는 데 권장되며, 특히 입력값의 간격이 좁은 경우에 권장됩니다. 두 값 사이의 차이가 약 5e-5보다 작은 경우 두 값의 간격이 좁습니다. 값의 간격이 좁은 경우 categorical 함수는 값으로부터 고유한 범주 이름을 만들 수 없습니다.
100개의 난수가 있는 숫자형 배열을 만듭니다.
X = rand(100,1)
X = 100×1
0.8147
0.9058
0.1270
0.9134
0.6324
0.0975
0.2785
0.5469
0.9575
0.9649
0.1576
0.9706
0.9572
0.4854
0.8003
⋮
이 난수를 세 개의 범주로 비닝하려면 discretize를 사용합니다. Bin 경계와 Bin의 범주 이름을 지정합니다.
C = discretize(X,[0 .25 .75 1],"categorical",["small" "medium" "large"])
C = 100×1 categorical
large
large
small
large
medium
small
medium
medium
large
large
small
large
large
medium
large
small
medium
large
large
large
medium
small
large
large
medium
large
medium
medium
medium
small
⋮
세 개 데이터 범주의 히스토그램을 플로팅합니다.
histogram(C)
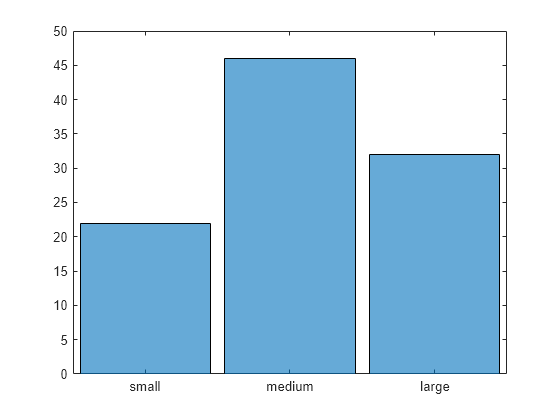
두 개의 categorical형 배열을 곱할 경우 결과는 새 범주 집합을 갖는 categorical형 배열입니다. 새 범주는 두 개의 원래 categorical형 배열의 범주에서 생성된, 순서가 지정된 모든 쌍입니다. 가능한 모든 범주 조합의 집합은 두 개의 원래 범주 집합의 카테시안 곱(Cartesian product)이라고도 알려져 있습니다.
예를 들어, 두 개의 categorical형 배열을 만듭니다. 이 배열에는 6명의 환자에 대한 혈액형과 Rh 인자가 나열되어 있습니다.
bloodGroups = categorical(["A" "AB" "O" "O" "A" "A"], ... ["A" "B" "AB" "O"])
bloodGroups = 1×6 categorical
A AB O O A A
Rhfactors = categorical(["+" "+" "-" "-" "+" "+"])
Rhfactors = 1×6 categorical
+ + - - + +
두 배열의 범주를 표시합니다. 두 categorical형 배열은 동일한 개수의 요소를 가지지만, 범주 개수는 서로 다를 수 있습니다.
categories(bloodGroups)
ans = 4×1 cell
{'A' }
{'B' }
{'AB'}
{'O' }
categories(Rhfactors)
ans = 2×1 cell
{'+'}
{'-'}
이 두 categorical형 배열을 곱합니다. 곱의 요소는 입력 배열의 대응하는 요소들의 조합에서 가져옵니다.
bloodTypes = bloodGroups .* Rhfactors
bloodTypes = 1×6 categorical
A + AB + O - O - A + A +
하지만 곱의 범주는 두 배열의 범주에서 생성될 수 있는, 순서가 지정된 모든 쌍입니다. 따라서 일부 범주는 출력 배열의 어떤 요소에도 해당되지 않을 수 있습니다.
categories(bloodTypes)
ans = 8×1 cell
{'A +' }
{'A -' }
{'B +' }
{'B -' }
{'AB +'}
{'AB -'}
{'O +' }
{'O -' }
제한 사항
입력 배열이 숫자형 배열, datetime형 배열 또는 duration형 배열이고 이 입력 배열의 값에서 범주 이름을 생성하는 경우
categorical은 유효 숫자 5자리로 반올림합니다.예를 들어,
categorical([1 1.23456789])의 경우 이 두 값에서1과1.2346이 범주 이름으로 생성됩니다. 연속된 숫자형 데이터, duration형 데이터 또는 datetime형 데이터에서 범주를 생성하려면discretize함수를 사용하십시오.입력 배열에 간격이 너무 좁은 숫자형 값, datetime형 값 또는 duration형 값이 있는 경우
categorical은 그러한 값으로부터 범주 이름을 생성할 수 없습니다. 입력 배열에 차이가 약5e-5보다 작은 두 값이 있는 경우 값의 간격이 너무 좁다고 여겨집니다.예를 들어,
categorical([1 1.00001])은 두 숫자형 값 사이의 차이가 너무 작기 때문에 이 두 숫자형 값으로부터 범주 이름을 만들 수 없습니다. 연속된 숫자형 데이터, duration형 데이터 또는 datetime형 데이터에서 범주를 생성하려면discretize함수를 사용하십시오.
팁
categorical형 배열을 수락하거나 반환하는 함수 목록은 categorical형 배열 항목을 참조하십시오.
확장 기능
버전 내역
R2013b에 개발됨
참고 항목
categories | discretize | iscategorical | addcats | times | NaN | missing