categorical형 배열 생성하기
이 예제에서는 다양한 유형의 입력 데이터에서 categorical형 배열을 만들고 배열의 요소를 수정하는 방법을 보여줍니다. categorical 데이터형은 유한한 이산 범주 집합에 속하는 값을 저장합니다. categorical형 배열은 숫자형 배열, 논리형 배열, string형 배열 또는 문자형 벡터로 구성된 셀형 배열로부터 생성할 수 있습니다. 입력 배열의 고유한 값들이 categorical형 배열의 범주가 됩니다. categorical형 배열은 데이터를 효율적으로 저장하고 편리하게 조작할 수 있도록 하는 동시에 값에 대한 의미 있는 이름도 유지합니다.
기본적으로 categorical형 배열의 범주에는 수학적 정렬이 적용되지 않습니다. 예를 들어, 반려 동물 범주들로 구성된 이산 집합 ["dog" "cat" "bird"]에는 유의미한 수학적 순서가 없으므로 MATLAB®은 사전순 정렬 ["bird" "cat" "dog"]를 사용합니다. 그러나 순서형 categorical형 배열을 만들어서 범주가 유의미한 수학적 순서를 갖도록 할 수도 있습니다. 예를 들어, 크기 범주들로 구성된 이산 집합 ["small" "medium" "large"]에는 수학적 정렬 small < medium < large가 적용될 수 있습니다. 순서형 categorical형 배열을 사용하면 요소끼리 비교를 수행할 수 있습니다.
입력 배열에서 categorical형 배열 생성하기
입력 배열에서 categorical형 배열을 생성하려면 categorical 함수를 사용하십시오.
예를 들어, 뉴잉글랜드에 속한 주를 요소로 가지는 string형 배열을 만듭니다. 일부 문자열에는 선행 공백과 후행 공백이 있습니다.
statesNE = ["MA" "ME" " CT" "VT" " ME " "NH" "VT" "MA" "NH" "CT" "RI "]
statesNE = 1×11 string
"MA" "ME" " CT" "VT" " ME " "NH" "VT" "MA" "NH" "CT" "RI "
string형 배열을 categorical형 배열로 변환합니다. string형 배열(또는 문자형 벡터로 구성된 셀형 배열)에서 categorical형 배열을 생성하면 선행 공백과 후행 공백이 제거됩니다.
statesNE = categorical(statesNE)
statesNE = 1×11 categorical
MA ME CT VT ME NH VT MA NH CT RI
categories 함수를 사용하여 statesNE의 범주를 나열합니다. statesNE의 모든 요소가 아래 범주 중 하나에 속합니다. statesNE는 6개의 고유한 주를 가지므로 6개의 범주가 있습니다. 주의 약어는 수학적 순서를 갖지 않으므로 범주가 사전순으로 나열됩니다.
categories(statesNE)
ans = 6×1 cell
{'CT'}
{'MA'}
{'ME'}
{'NH'}
{'RI'}
{'VT'}
요소를 추가하고 수정하기
categorical형 배열에 하나의 요소를 추가하려면 범주 이름을 나타내는 텍스트를 할당합니다. 예를 들어, statesNE에 주를 하나 추가합니다.
statesNE(12) = "ME"statesNE = 1×12 categorical
MA ME CT VT ME NH VT MA NH CT RI ME
여러 개의 요소를 추가하거나 수정하려면 categorical형 배열을 할당해야 합니다.
statesNE(1:3) = categorical(["RI" "VT" "MA"])
statesNE = 1×12 categorical
RI VT MA VT ME NH VT MA NH CT RI ME
누락값을 정의되지 않은 요소로 추가하기
누락값을 categorical형 배열의 정의되지 않은 요소로 할당할 수 있습니다. 정의되지 않은 categorical형 값은 숫자형 배열의 NaN(Not-a-Number)과 마찬가지로, 어떠한 범주에도 속하지 않습니다.
누락값을 할당하려면 missing 함수를 사용합니다. 예를 들어, categorical형 배열의 첫 번째 요소를 누락값으로 수정합니다.
statesNE(1) = missing
statesNE = 1×12 categorical
<undefined> VT MA VT ME NH VT MA NH CT RI ME
categorical형 배열의 끝에 2개의 누락값을 할당합니다.
statesNE(12:13) = [missing missing]
statesNE = 1×13 categorical
<undefined> VT MA VT ME NH VT MA NH CT RI <undefined> <undefined>
string형 배열을 categorical형 배열로 변환하면, 누락값인 string형과 빈 string형이 categorical형 배열에서는 정의되지 않은 요소로 처리됩니다. 숫자형 배열을 변환하면 NaN이 정의되지 않은 요소로 처리됩니다. 따라서 누락값인 string형 "", '' 또는 NaN을 categorical형 배열의 요소에 할당하면 정의되지 않은 categorical형 값으로 변환됩니다.
statesNE(2) = ""statesNE = 1×13 categorical
<undefined> <undefined> MA VT ME NH VT MA NH CT RI <undefined> <undefined>
string형 배열에서 순서형 categorical형 배열 생성하기
순서형 categorical형 배열에서는 범주들의 순서에 따라 수학적 순서가 정의되므로 비교를 수행할 수 있습니다. 이러한 수학적 순서를 기준으로 관계 연산자를 사용하여 순서형 categorical형 배열의 요소끼리 비교할 수 있습니다. 순서형이 아닌 categorical형 배열에서는 요소끼리 비교할 수 없습니다.
예를 들어, 8개 물체의 크기를 포함하는 string형 배열을 생성합니다.
AllSizes = ["medium" "large" "small" "small" "medium" ... "large" "medium" "small"];
string형 배열에는 3개의 고유한 값 "large", "medium", "small"이 있습니다. string형 배열에는 small < medium < large를 간편하게 나타낼 수 있는 방법이 없습니다.
string형 배열을 순서형 categorical형 배열로 변환합니다. 범주를 small, medium, large의 순서로 정의합니다. 순서형 categorical형 배열에서 첫 번째로 지정된 범주가 가장 작고 마지막 범주가 가장 큽니다.
valueset = ["small" "medium" "large"]; sizeOrd = categorical(AllSizes,valueset,Ordinal=true)
sizeOrd = 1×8 categorical
medium large small small medium large medium small
categorical형 배열 sizeOrd에서는 값들의 순서가 원래대로 유지됩니다.
sizeOrd의 이산 범주를 나열합니다. 범주의 순서가 수학적 정렬 순서 small < medium < large와 일치합니다.
categories(sizeOrd)
ans = 3×1 cell
{'small' }
{'medium'}
{'large' }
숫자형 데이터를 비닝(Binning)하여 순서형 categorical형 배열 생성
연속된 숫자형 데이터로 구성된 배열에서는 숫자 범위를 범주로 지정하면 유용한 경우가 있습니다. 이러한 경우 discretize 함수를 사용하여 데이터를 비닝합니다. Bin에 범주 이름을 할당합니다.
예를 들어, 0과 50 사이에 있는 100개의 난수로 구성된 벡터를 생성합니다.
x = rand(100,1)*50
x = 100×1
40.7362
45.2896
6.3493
45.6688
31.6180
4.8770
13.9249
27.3441
47.8753
48.2444
7.8807
48.5296
47.8583
24.2688
40.0140
⋮
discretize를 사용하여 x의 값을 비닝해서 categorical형 배열을 생성합니다. 0과 15 사이의 모든 값을 첫 번째 Bin에 추가하고, 15와 35 사이의 모든 값을 두 번째 Bin에 추가하고, 35와 50 사이의 모든 값을 세 번째 Bin에 추가합니다. 각 Bin은 좌측 끝점만 포함하고 우측 끝점은 포함하지 않되, 마지막 Bin만 예외입니다.
catnames = ["small" "medium" "large"]; binnedData = discretize(x,[0 15 35 50],"categorical",catnames)
binnedData = 100×1 categorical
large
large
small
large
medium
small
small
medium
large
large
small
large
large
medium
large
small
medium
large
large
large
medium
small
large
large
medium
large
large
medium
medium
small
⋮
binnedData는 small < medium < large 순서로 된 3개의 범주를 갖는 순서형 categorical형 배열입니다.
각 범주에 포함된 요소의 개수를 표시하려면 summary 함수를 사용합니다.
summary(binnedData)
binnedData: 100×1 ordinal categorical
small 30
medium 35
large 35
<undefined> 0
Additional statistics:
Min small
Median medium
Max large
다양한 종류의 비닝된 데이터 차트를 만들 수 있습니다. 예를 들어, binnedData에 대한 원형 차트를 만들어 보겠습니다.
pie(binnedData)
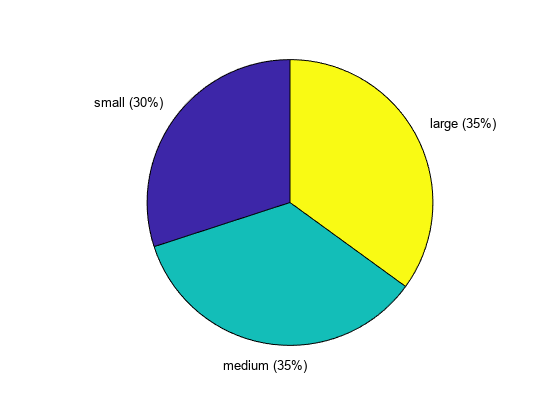
categorical형 배열 사전할당하기
NaN으로 구성된 배열을 만들고 이 배열을 categorical형 배열로 변환하여 임의 크기의 categorical형 배열을 사전할당할 수 있습니다. 배열을 사전할당한 후에는 배열에 범주 이름을 추가하여 해당 범주를 초기화할 수 있습니다.
예를 들어, NaN으로 구성된 2×4 배열을 만듭니다.
A = NaN(2,4)
A = 2×4
NaN NaN NaN NaN
NaN NaN NaN NaN
그런 다음 NaN으로 구성된 배열을 정의되지 않은 categorical형 값으로 구성된 categorical형 배열로 변환합니다.
A = categorical(A)
A = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
이 시점에는 A가 아무런 범주를 갖지 않습니다.
categories(A)
ans = 0×0 empty cell array
addcats 함수를 사용하여 A에 small, medium, large 범주를 추가합니다.
A = addcats(A,["small" "medium" "large"])
A = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
A의 요소는 여전히 정의되지 않은 값이지만 A의 범주는 정의되었습니다.
categories(A)
ans = 3×1 cell
{'small' }
{'medium'}
{'large' }
이제 A에 범주가 있으므로 정의된 categorical형 값을 A 요소로 할당할 수 있습니다.
A(1) = "medium"; A(8) = "small"; A(3:5) = "large"
A = 2×4 categorical
medium large large <undefined>
<undefined> large <undefined> small
참고 항목
categorical | categories | discretize | summary | addcats | missing