bayesvarm
Create prior Bayesian vector autoregression (VAR) model object
Syntax
Description
PriorMdl = bayesvarm(numseries,numlags)
The collection of model parameters are in the set
p =
numlagsis the AR polynomial order.The joint prior distribution of (Λ,Σ) is diffuse.
PriorMdl = bayesvarm(numseries,numlags,ModelType=modelType)modelType for Λ and Σ. For this
syntax, modelType can be 'conjugate',
'semiconjugate', 'diffuse', or
'normal'. For example, ModelType="semiconjugate"
specifies semiconjugate priors for the multivariate normal likelihood—specifically, vec(Λ)|Σ
is multivariate normal, Σ is inverse Wishart, and Λ and Σ are independent.
PriorMdl = bayesvarm(numseries,numlags,ModelType=modelType,Name=Value)
Examples
Consider the 3-D VAR(4) model for the US inflation (INFL), unemployment (UNRATE), and federal funds (FEDFUNDS) rates.
For all , is a series of independent 3-D normal innovations with a mean of 0 and variance .
Suppose that the AR coefficient matrices , model constant , and innovations covariance matrix are random variables, and their prior distributions are unknown. In this case, use the noninformative diffuse prior: the joint prior distribution is proportional to .
Create a diffuse prior model for the 3-D VAR(4) model parameters, which is the default prior model type.
numseries = 3; numlags = 4; PriorMdl = bayesvarm(numseries,numlags)
PriorMdl =
diffusebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a diffusevarm Bayesian VAR model object representing the prior distribution of the AR coefficient matrices, model constant vector, and innovations covariance matrix. bayesvarm displays a summary of the prior distributions at the command line.
AR— Prior means of the AR coefficient matrices.Constant— Prior means of the model constant vector.TrendandBeta— Prior means of the linear time trend vector and exogenous regression coefficient matrix, respectively. Because the values are empty arrays, the corresponding parameters are not in the model.Covariance— Prior mean of the innovations covariance matrix.
If you have data, then you can estimate characteristics of the posterior distribution by passing PriorMdl and the data to estimate.
Consider the 3-D VAR(4) model in Default Diffuse Prior Model. Assume the following:
. is a 13-by-3 matrix of prior coefficient means ( is the prior mean matrix of , is the prior mean matrix of ,..., and is the prior mean vector of ). is a 13-by-13 matrix representing the among-coefficient prior covariance matrix within an equation. is the 3-by-3 random innovations covariance matrix.
. is the 3-by-3 scale matrix, and is the degrees of freedom of the inverse Wishart distribution.
The coefficients and the innovations covariance matrix are dependent.
Prior coefficient variances among the equations are proportional.
These assumptions and the data likelihood imply a matrix-normal-inverse-Wishart conjugate model.
Create a matrix-normal-inverse-Wishart conjugate prior model for the VAR model parameters.
numseries = 3;
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,ModelType="conjugate")PriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [13×13 double]
Omega: [3×3 double]
DoF: 13
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a conjugatebvarm Bayesian VAR model object representing the prior distribution of the coefficients and innovations covariance matrix. bayesvarm displays a summary of the prior distributions at the command line; it returns the prior mean matrix in vectorized form.
The model contains many estimable parameters. To achieve a parsimonious model, bayesvarm applies the Minnesota prior regularization method to the AR coefficients, by default. Inspect the default prior means (centers of shrinkage) of the AR coefficient matrices.
AR1 = PriorMdl.AR{1}AR1 = 3×3
0.5000 0 0
0 0.5000 0
0 0 0.5000
AR2 = PriorMdl.AR{2}AR2 = 3×3
0 0 0
0 0 0
0 0 0
AR3 = PriorMdl.AR{3}AR3 = 3×3
0 0 0
0 0 0
0 0 0
AR4 = PriorMdl.AR{4}AR4 = 3×3
0 0 0
0 0 0
0 0 0
Each series is an AR(1) model with AR coefficient 0.5, a priori.
The tightness on shrinkage of the coefficients is proportional among the equations. Inspect the default tightness values by displaying a heatmap chart of the property V of PriorMdl, which contains a matrix of the scaled tightness on shrinkage of the coefficients for one equation (the unscaled shrinkage is = kron(PriorMdl.Covariance,PriorMdl.V)). Omit the final row and column, which correspond to the model constant.
% Create labels for the chart. numARCoeffMats = PriorMdl.NumSeries*PriorMdl.P; arcoeffnames = strings(numARCoeffMats,1); for r = numlags:-1:1 arcoeffnames(((r-1)*numseries+1):(numseries*r)) = ["\phi_{11,"+r+"}" "\phi_{12,"+r+"}" "\phi_{13,"+r+"}"]; end heatmap(arcoeffnames,arcoeffnames,PriorMdl.V(1:end-1,1:end-1));
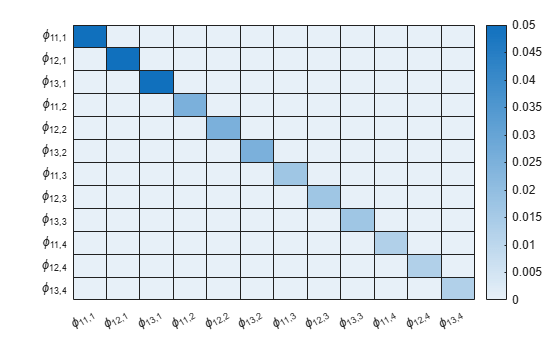
The tightness values decrease with lag, which suggests (a priori) that the means of the corresponding greater-lagged coefficients are more tightly locked around their center of 0.
Display the tightness of the model constant vector.
PriorMdl.V(end,end)
ans = 10000
The center of the model constant vector is 0 but has a large variance, which allows the estimation procedure to defer more to the data than the prior for the posterior mean of the constant vector.
You can specify alternative values after you create a model by using dot notation. For example, increase the tightness of all coefficients by a factor of 100.
PriorMdl.V = 100*PriorMdl.V;
Consider the 3-D VAR(4) model in Default Diffuse Prior Model. Assume these prior distributions, as presented in [1]:
. is a 39-by-1 vector of prior coefficient means (the model has 39 individual coefficients), and is a 39-by-39 prior coefficient covariance matrix.
The innovations covariance is a fixed matrix.
Suppose econometric theory dictates that
Create a normal conjugate prior model for the VAR model coefficients. Specify the value of by using the Sigma name-value argument.
numseries = 3; numlags = 4; Sigma = [10e-5 0 10e-4; 0 0.1 -0.2; 10e-4 -0.2 1.6]; PriorMdl = bayesvarm(numseries,numlags,ModelType="normal", ... Sigma=Sigma)
PriorMdl =
normalbvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [39×39 double]
Sigma: [3×3 double]
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a normalbvarm Bayesian VAR model object representing the prior distribution of the coefficients. Because is fixed for normalbvarm prior models, PriorMdl.Sigma and PriorMdl.Covariance are equal.
PriorMdl.Sigma
ans = 3×3
0.0001 0 0.0010
0 0.1000 -0.2000
0.0010 -0.2000 1.6000
PriorMdl.Covariance
ans = 3×3
0.0001 0 0.0010
0 0.1000 -0.2000
0.0010 -0.2000 1.6000
Consider the 3-D VAR(4) model in Default Diffuse Prior Model. Assume the following:
. is a 39-by-1 vector of prior coefficient means (the model has 39 individual coefficients), and is a 39-by-39 prior coefficient covariance matrix.
. is the 3-by-3 scale matrix, and is the degrees of freedom of the inverse Wishart distribution.
The coefficients and the innovations covariance matrix are independent.
These assumptions and the data likelihood imply a normal-inverse-Wishart semiconjugate model.
The model contains many estimable parameters. To achieve a parsimonious model, bayesvarm enables you to regularize the coefficients by using the Minnesota prior regularization method, rather than specifying each prior mean and variance.
Create a normal-inverse-Wishart semiconjugate prior model for the VAR model parameters. Specify the following:
All series are AR(1) models, a priori, with AR coefficient 0.9. Set the
Centername-value argument to a 3-by-1 vector composed of0.9.The tightness around self lags in is
1. Set theSelfLagname-value argument to1.The tightness around cross lags in is
0.5. Set theCrossLagname-value argument to0.5.All tightness values decay by a factor of the lag degree squared. Set the
Decayname-value argument to2.
numseries = 3; numlags = 4; center = 0.9*ones(numseries,1); PriorMdl = bayesvarm(numseries,numlags,ModelType="semiconjugate", ... Center=center,SelfLag=1,CrossLag=0.5,Decay=2)
PriorMdl =
semiconjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [39×39 double]
Omega: [3×3 double]
DoF: 13
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a semiconjugatebvarm Bayesian VAR model object representing the prior distribution of the coefficients and innovations covariance matrix. bayesvarm displays a summary of the prior distributions at the command line; it returns the prior mean matrix in vectorized form.
Display the prior means of the AR coefficient matrices.
AR1 = PriorMdl.AR{1}AR1 = 3×3
0.9000 0 0
0 0.9000 0
0 0 0.9000
AR2 = PriorMdl.AR{2}AR2 = 3×3
0 0 0
0 0 0
0 0 0
AR3 = PriorMdl.AR{3}AR3 = 3×3
0 0 0
0 0 0
0 0 0
AR4 = PriorMdl.AR{4}AR4 = 3×3
0 0 0
0 0 0
0 0 0
Each series is an AR(1) model, a priori.
The property V of PriorMdl contains a matrix of the tightness on shrinkage of the coefficients. The rows and columns of V correspond to the elements of the Mu property of PriorMdl.
Elements 1 through 3 correspond to the lag 1 AR coefficients in the first equation ordered by response variable, that is, , , and .
Elements 4 through 6 correspond to the lag 2 AR coefficients in the first equation.
Elements 7 through 9 correspond to the lag 3 AR coefficients in the first equation.
Elements 10 through 12 correspond to the lag 4 AR coefficients in the first equation.
Element 13 is the model constant in the first equation.
MATLAB® repeats the pattern for each equation.
In this example, the tightness of shrinkage is the same for all equations. Display a heatmap chart of the property V of PriorMdl for the tightness values of the AR coefficients in the first equation.
% Create labels for the chart. numARCoeffMats = PriorMdl.NumSeries*PriorMdl.P; arcoeffnames = strings(numARCoeffMats,1); for r = numlags:-1:1 arcoeffnames(((r-1)*numseries+1):(numseries*r)) = ["\phi_{"+r+",11}" "\phi_{"+r+",12}" "\phi_{"+r+"13}"]; end heatmap(arcoeffnames,arcoeffnames,PriorMdl.V(1:numARCoeffMats,1:numARCoeffMats));
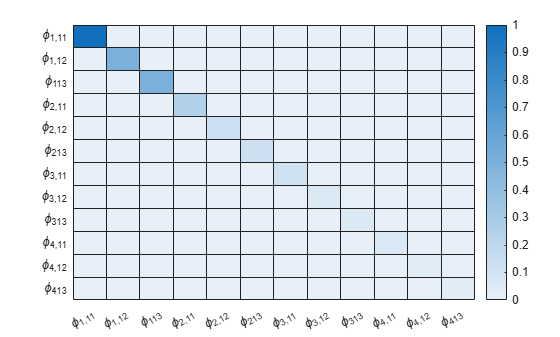
The tightness values decrease with lag, which suggests (a priori) that the means of the corresponding greater-lagged coefficients are more tightly locked around their center of 0. By default, AR coefficients are uncorrelated.
Display the tightness of the model constant vector.
PriorMdl.V(numARCoeffMats + 1,numARCoeffMats + 1)
ans = 10000
The center of the model constant vector is 0 but has a large variance, which allows the estimation procedure to defer more to the data than the prior for the posterior mean of the constant vector.
You can specify alternative values after you create a model by using dot notation. For example, increase the tightness of all coefficients by a factor of 100.
PriorMdl.V = 100*PriorMdl.V;
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Because MATLAB does not adjust input data for variable scales, a best practice is to adjust all series to have a similar magnitude. Consequently, the scales of the coefficients are similar.
By default,
bayesvarmcreates Bayesian VAR models by using the Minnesota prior assumptions and parameter structure [1]. After you create a model, you can inspect the effect of coefficient shrinkage by callingsummarize(PriorMdl). You can change the prior mean and variance by settingPriorMdl.MuandPriorMdl.V, respectively.
Alternative Functionality
To create a non-Bayesian VAR model, see varm.
References
[1] Litterman, Robert B. "Forecasting with Bayesian Vector Autoregressions: Five Years of Experience." Journal of Business and Economic Statistics 4, no. 1 (January 1986): 25–38. https://doi.org/10.2307/1391384.
Version History
Introduced in R2020a