bayeslm
Create Bayesian linear regression model object
Syntax
Description
PriorMdl = bayeslm(NumPredictors)PriorMdl is
a template that defines the prior distributions and dimensionality of
β.
PriorMdl = bayeslm(NumPredictors,ModelType=modelType)modelType for
β and σ2. For
this syntax, modelType can be:
'conjugate','semiconjugate', or'diffuse'to create a standard Bayesian linear regression prior model'mixconjugate','mixsemiconjugate', or'lasso'to create a Bayesian linear regression prior model for predictor variable selection
For example, ModelType="conjugate" specifies
conjugate priors for the Gaussian likelihood, that is,
β|σ2 as
Gaussian, σ2 as inverse gamma.
PriorMdl = bayeslm(NumPredictors,ModelType=modelType,Name=Value)modelType.
If you specify
ModelType="empirical", you must also specify theBetaDrawsandSigma2Drawsname-value arguments.BetaDrawsandSigma2Drawscharacterize the respective prior distributions.If you specify
ModelType="custom", you must also specify theLogPDFname-value argument.LogPDFcompletely characterizes the joint prior distribution.
Examples
Consider the multiple linear regression model that predicts the US real gross national product (GNPR) using a linear combination of industrial production index (IPI), total employment (E), and real wages (WR).
For all , is a series of independent Gaussian disturbances with a mean of 0 and variance .
Suppose that the regression coefficients and the disturbance variance are random variables, and their prior values and distribution are unknown. In this case, use the noninformative Jefferys prior: the joint prior distribution is proportional to .
These assumptions and the data likelihood imply an analytically tractable posterior distribution.
Create a diffuse prior model for the linear regression parameters, which is the default model type. Specify the number of predictors p.
p = 3; Mdl = bayeslm(p)
Mdl =
diffuseblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4×1 cell}
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------
Intercept | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Beta(1) | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Beta(2) | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Beta(3) | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Sigma2 | Inf Inf [ NaN, NaN] 1.000 Proportional to 1/Sigma2
Mdl is a diffuseblm Bayesian linear regression model object representing the prior distribution of the regression coefficients and disturbance variance. bayeslm displays a summary of the prior distributions at the command line. Because the prior is noninformative and the model does not contain data, the summary is trivial.
If you have data, then you can estimate characteristics of the posterior distribution by passing the prior model Mdl and data to estimate.
Consider the linear regression model in Default Diffuse Prior Model. Assume these prior distributions:
. is a 4-by-1 vector of means, and is a scaled 4-by-4 positive definite covariance matrix.
. and are the shape and scale, respectively, of an inverse gamma distribution.
These assumptions and the data likelihood imply a normal-inverse-gamma semiconjugate model. The conditional posteriors are conjugate to the prior with respect to the data likelihood, but the marginal posterior is analytically intractable.
Create a normal-inverse-gamma semiconjugate prior model for the linear regression parameters. Specify the number of predictors p.
p = 3;
Mdl = bayeslm(p,ModelType="semiconjugate") Mdl =
semiconjugateblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4×1 cell}
Mu: [4×1 double]
V: [4×4 double]
A: 3
B: 1
| Mean Std CI95 Positive Distribution
-------------------------------------------------------------------------------
Intercept | 0 100 [-195.996, 195.996] 0.500 N (0.00, 100.00^2)
Beta(1) | 0 100 [-195.996, 195.996] 0.500 N (0.00, 100.00^2)
Beta(2) | 0 100 [-195.996, 195.996] 0.500 N (0.00, 100.00^2)
Beta(3) | 0 100 [-195.996, 195.996] 0.500 N (0.00, 100.00^2)
Sigma2 | 0.5000 0.5000 [ 0.138, 1.616] 1.000 IG(3.00, 1)
Mdl is a semiconjugateblm Bayesian linear regression model object representing the prior distribution of the regression coefficients and disturbance variance. bayeslm displays a summary of the prior distributions at the command line. For example, the elements of Positive represent the prior probability that the corresponding parameter is positive.
If you have data, then you can estimate characteristics of the marginal or conditional posterior distribution by passing the prior model Mdl and data to estimate.
Consider the linear regression model in Default Diffuse Prior Model. Assume these prior distributions:
. is a 4-by-1 vector of means, and is a scaled 4-by-4 positive definite covariance matrix. Suppose you have prior knowledge that and V is the identity matrix.
. and are the shape and scale, respectively, of an inverse gamma distribution.
These assumptions and the data likelihood imply a normal-inverse-gamma conjugate model.
Create a normal-inverse-gamma conjugate prior model for the linear regression parameters. Specify the number of predictors p and set the regression coefficient names to the corresponding variable names.
p = 3; Mdl = bayeslm(p,ModelType="conjugate",Mu=[-20; 4; 0.1; 2],V=eye(4), ... VarNames=["IPI" "E" "WR"])
Mdl =
conjugateblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4×1 cell}
Mu: [4×1 double]
V: [4×4 double]
A: 3
B: 1
| Mean Std CI95 Positive Distribution
----------------------------------------------------------------------------------
Intercept | -20 0.7071 [-21.413, -18.587] 0.000 t (-20.00, 0.58^2, 6)
IPI | 4 0.7071 [ 2.587, 5.413] 1.000 t (4.00, 0.58^2, 6)
E | 0.1000 0.7071 [-1.313, 1.513] 0.566 t (0.10, 0.58^2, 6)
WR | 2 0.7071 [ 0.587, 3.413] 0.993 t (2.00, 0.58^2, 6)
Sigma2 | 0.5000 0.5000 [ 0.138, 1.616] 1.000 IG(3.00, 1)
Mdl is a conjugateblm Bayesian linear regression model object representing the prior distribution of the regression coefficients and disturbance variance. bayeslm displays a summary of the prior distributions at the command line. Although bayeslm assigns names to the intercept and disturbance variance, all other coefficients have the specified names.
By default, bayeslm sets the shape and scale to 3 and 1, respectively. Suppose you have prior knowledge that the shape and scale are 5 and 2.
Set the prior shape and scale of to their assumed values.
Mdl.A = 5; Mdl.B = 2
Mdl =
conjugateblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4×1 cell}
Mu: [4×1 double]
V: [4×4 double]
A: 5
B: 2
| Mean Std CI95 Positive Distribution
----------------------------------------------------------------------------------
Intercept | -20 0.3536 [-20.705, -19.295] 0.000 t (-20.00, 0.32^2, 10)
IPI | 4 0.3536 [ 3.295, 4.705] 1.000 t (4.00, 0.32^2, 10)
E | 0.1000 0.3536 [-0.605, 0.805] 0.621 t (0.10, 0.32^2, 10)
WR | 2 0.3536 [ 1.295, 2.705] 1.000 t (2.00, 0.32^2, 10)
Sigma2 | 0.1250 0.0722 [ 0.049, 0.308] 1.000 IG(5.00, 2)
bayeslm updates the prior distribution summary based on the changes in the shape and scale.
Consider the linear regression model in Default Diffuse Prior Model. Assume these prior distributions:
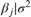 is 4-D t distribution with 50 degrees of freedom for each component and the identity matrix for the correlation matrix. Also, the distribution is centered at
is 4-D t distribution with 50 degrees of freedom for each component and the identity matrix for the correlation matrix. Also, the distribution is centered at ![${\left[ {\begin{array}{*{20}{c}} { - 25}&4&0&3 \end{array}} \right]^\prime }$](../examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq06094370667326100457.png) and each component is scaled by the corresponding elements of the vector
and each component is scaled by the corresponding elements of the vector ![${\left[ {\begin{array}{*{20}{c}} {10}&1&1&1 \end{array}} \right]^\prime }$](../examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq11954731508684699991.png) .
.
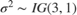 .
.
bayeslm treats these assumptions and the data likelihood as if the corresponding posterior is analytically intractable.
Declare a MATLAB® function that:
Accepts values of
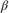 and
and 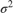 together in a column vector, and accepts values of the hyperparameters
together in a column vector, and accepts values of the hyperparametersReturns the value of the joint prior distribution,
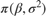 , given the values of and
, given the values of and
function logPDF = priorMVTIG(params,ct,st,dof,C,a,b) %priorMVTIG Log density of multivariate t times inverse gamma % priorMVTIG passes params(1:end-1) to the multivariate t density % function with dof degrees of freedom for each component and positive % definite correlation matrix C. priorMVTIG returns the log of the product of % the two evaluated densities. % % params: Parameter values at which the densities are evaluated, an % m-by-1 numeric vector. % % ct: Multivariate t distribution component centers, an (m-1)-by-1 % numeric vector. Elements correspond to the first m-1 elements % of params. % % st: Multivariate t distribution component scales, an (m-1)-by-1 % numeric (m-1)-by-1 numeric vector. Elements correspond to the % first m-1 elements of params. % % dof: Degrees of freedom for the multivariate t distribution, a % numeric scalar or (m-1)-by-1 numeric vector. priorMVTIG expands % scalars such that dof = dof*ones(m-1,1). Elements of dof % correspond to the elements of params(1:end-1). % % C: Correlation matrix for the multivariate t distribution, an % (m-1)-by-(m-1) symmetric, positive definite matrix. Rows and % columns correspond to the elements of params(1:end-1). % % a: Inverse gamma shape parameter, a positive numeric scalar. % % b: Inverse gamma scale parameter, a positive scalar. % beta = params(1:(end-1)); sigma2 = params(end); tVal = (beta - ct)./st; mvtDensity = mvtpdf(tVal,C,dof); igDensity = sigma2^(-a-1)*exp(-1/(sigma2*b))/(gamma(a)*b^a); logPDF = log(mvtDensity*igDensity); end
Create an anonymous function that operates like priorMVTIG, but accepts the parameter values only and holds the hyperparameter values fixed.
dof = 50; C = eye(4); ct = [-25; 4; 0; 3]; st = [10; 1; 1; 1]; a = 3; b = 1; prior = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
Create a custom joint prior model for the linear regression parameters. Specify the number of predictors p. Also, specify the function handle for priorMVTIG, and pass the hyperparameter values.
p = 3;
Mdl = bayeslm(p,ModelType="custom",LogPDF=prior)
Mdl =
customblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4×1 cell}
LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)
The priors are defined by the function:
@(params)priorMVTIG(params,ct,st,dof,C,a,b)
Mdl is a customblm Bayesian linear regression model object representing the prior distribution of the regression coefficients and disturbance variance. In this case, bayeslm does not display a summary of the prior distributions at the command line.
Consider the linear regression model in Default Diffuse Prior Model.
Assume these prior distributions:
For k = 0,...,3, has a Laplace distribution with a mean of 0 and a scale of , where is the shrinkage parameter. The coefficients are conditionally independent.
. and are the shape and scale, respectively, of an inverse gamma distribution.
Create a prior model for Bayesian linear regression by using bayeslm. Specify the number of predictors p and the variable names.
p = 3; PriorMdl = bayeslm(p,ModelType="lasso", ... VarNames=["IPI" "E" "WR"]);
PriorMdl is a lassoblm Bayesian linear regression model object representing the prior distribution of the regression coefficients and disturbance variance. By default, bayeslm attributes a shrinkage of 0.01 to the intercept and 1 to the other coefficients in the model.
Using dot notation, change the default shrinkages for all coefficients, except the intercept, by specifying a 3-by-1 vector containing the new values for the Lambda property of PriorMdl.
Attribute a shrinkage of
10toIPIandWR.Because
Ehas a scale that is several orders of magnitude larger than the other variables, attribute a shrinkage of1e5to it.
Lambda(2:end) contains the shrinkages of the coefficients corresponding to the specified variables in the VarNames property of PriorMdl.
PriorMdl.Lambda = [10; 1e5; 10];
Load the Nelson-Plosser data set. Create variables for the response and predictor series.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,"GNPR"};
Perform Bayesian lasso regression by passing the prior model and data to estimate, that is, by estimating the posterior distribution of and . Bayesian lasso regression uses Markov chain Monte Carlo (MCMC) to sample from the posterior. For reproducibility, set a random seed.
rng(1); PosteriorMdl = estimate(PriorMdl,X,y);
Method: lasso MCMC sampling with 10000 draws
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
-------------------------------------------------------------------------
Intercept | -1.3472 6.8160 [-15.169, 11.590] 0.427 Empirical
IPI | 4.4755 0.1646 [ 4.157, 4.799] 1.000 Empirical
E | 0.0001 0.0002 [-0.000, 0.000] 0.796 Empirical
WR | 3.1610 0.3136 [ 2.538, 3.760] 1.000 Empirical
Sigma2 | 60.1452 11.1180 [42.319, 85.085] 1.000 Empirical
Plot the posterior distributions.
plot(PosteriorMdl)
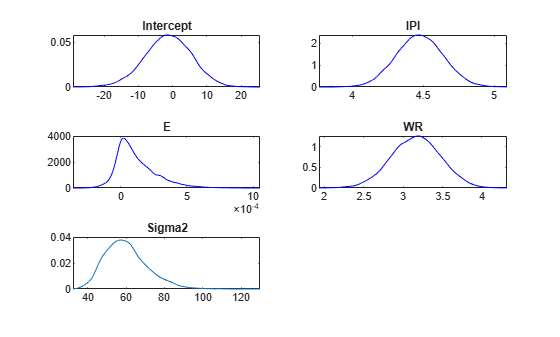
Given a shrinkage of 10, the distribution of E is fairly dense around 0. Therefore, E might not be an important predictor.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] George, E. I., and R. E. McCulloch. "Variable Selection Via Gibbs Sampling." Journal of the American Statistical Association. Vol. 88, No. 423, 1993, pp. 881–889.
[2] Koop, G., D. J. Poirier, and J. L. Tobias. Bayesian Econometric Methods. New York, NY: Cambridge University Press, 2007.
[3] Park, T., and G. Casella. "The Bayesian Lasso." Journal of the American Statistical Association. Vol. 103, No. 482, 2008, pp. 681–686.
Version History
Introduced in R2017a
See Also
Objects
conjugateblm|semiconjugateblm|diffuseblm|customblm|empiricalblm|lassoblm|mixconjugateblm|mixsemiconjugateblm