estimate
Estimate posterior distribution of Bayesian vector autoregression (VAR) model parameters
Syntax
Description
PosteriorMdl = estimate(PriorMdl,Y)PosteriorMdl that characterizes the joint posterior distributions of the coefficients Λ and innovations covariance matrix Σ. PriorMdl specifies the joint prior distribution of the parameters and the structure of the VAR model. Y is the multivariate response data. PriorMdl and PosteriorMdl might not be the same object type.
NaNs in the data indicate missing values, which estimate removes by using list-wise deletion.
PosteriorMdl = estimate(PriorMdl,Y,Name,Value)'Y0' name-value pair argument.
[ also returns an estimation summary of the posterior distribution PosteriorMdl,Summary]
= estimate(___)Summary, using any of the input argument combinations in the previous syntaxes.
Examples
Consider the 3-D VAR(4) model for the US inflation (INFL), unemployment (UNRATE), and federal funds (FEDFUNDS) rates.
For all , is a series of independent 3-D normal innovations with a mean of 0 and covariance . Assume that the joint prior distribution of the VAR model parameters is diffuse.
Load and Preprocess Data
Load the US macroeconomic data set. Compute the inflation rate. Plot all response series.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; figure plot(DataTimeTable.Time,DataTimeTable{:,seriesnames}) legend(seriesnames)
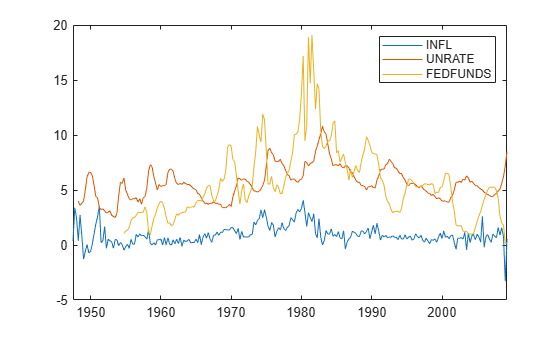
Stabilize the unemployment and federal funds rates by applying the first difference to each series.
DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)];
DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)];
seriesnames(2:3) = "D" + seriesnames(2:3);Remove all missing values from the data.
rmDataTimeTable = rmmissing(DataTimeTable);
Create Prior Model
Create a diffuse Bayesian VAR(4) prior model for the three response series. Specify the response variable names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,'SeriesNames',seriesnames)PriorMdl =
diffusebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["INFL" "DUNRATE" "DFEDFUNDS"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a diffusebvarm model object.
Estimate Posterior Distribution
Estimate the posterior distribution by passing the prior model and entire data series to estimate.
PosteriorMdl = estimate(PriorMdl,rmDataTimeTable{:,seriesnames})Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
PosteriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["INFL" "DUNRATE" "DFEDFUNDS"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [13×13 double]
Omega: [3×3 double]
DoF: 184
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PosteriorMdl is a conjugatebvarm model object; the posterior is analytically tractable. The command line displays the posterior means (Mean) and standard deviations (Std) of all coefficients and the innovations covariance matrix. Row AR{k}(i,j) contains the posterior estimates of , the lag k AR coefficient of response variable j in response equation i. By default, estimate uses the first four observations as a presample to initialize the model.
Display the posterior means of the AR coefficient matrices by using dot notation.
AR1 = PosteriorMdl.AR{1}AR1 = 3×3
0.1241 -0.4809 0.1005
-0.0219 0.4716 0.0391
-0.1586 -1.4368 -0.2905
AR2 = PosteriorMdl.AR{2}AR2 = 3×3
0.3236 -0.0503 0.0450
0.0913 0.2414 0.0536
0.3403 -0.2968 -0.3117
AR3 = PosteriorMdl.AR{3}AR3 = 3×3
0.4272 0.2738 0.0523
-0.0389 0.0552 0.0008
0.2848 -0.7401 0.0028
AR4 = PosteriorMdl.AR{4}AR4 = 3×3
0.0167 -0.1830 0.0067
0.0285 -0.1795 0.0088
-0.0690 0.1494 -0.1372
Consider the 3-D VAR(4) model of Estimate Posterior Distribution. In this case, fit the model to the data starting in 1970.
Load and Preprocess Data
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create Prior Model
Create a diffuse Bayesian VAR(4) prior model for the three response series. Specify the response variable names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = diffusebvarm(numseries,numlags,'SeriesNames',seriesnames);Partition Time Base for Subsamples
A VAR(4) model requires p = 4 presample observations to initialize the AR component for estimation. Define index sets corresponding to the required presample and estimation samples.
idxpre = rmDataTimeTable.Time < datetime('1970','InputFormat','yyyy'); % Presample indices idxest = ~idxpre; % Estimation sample indices T = sum(idxest)
T = 157
The effective sample size is 157 observations.
Estimate Posterior Distribution
Estimate the posterior distribution. Specify only the required presample observations by using the 'Y0' name-value pair argument.
Y0 = rmDataTimeTable{find(idxpre,PriorMdl.P,'last'),seriesnames};
PosteriorMdl = estimate(PriorMdl,rmDataTimeTable{idxest,seriesnames},...
'Y0',Y0);Bayesian VAR under diffuse priors
Effective Sample Size: 157
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1431 0.1134
Constant(2) | -0.0132 0.0588
Constant(3) | -0.6864 0.2418
AR{1}(1,1) | 0.1314 0.0869
AR{1}(2,1) | -0.0187 0.0450
AR{1}(3,1) | -0.2009 0.1854
AR{1}(1,2) | -0.5009 0.1834
AR{1}(2,2) | 0.4881 0.0950
AR{1}(3,2) | -1.6913 0.3912
AR{1}(1,3) | 0.1089 0.0446
AR{1}(2,3) | 0.0555 0.0231
AR{1}(3,3) | -0.3588 0.0951
AR{2}(1,1) | 0.2942 0.1012
AR{2}(2,1) | 0.0786 0.0524
AR{2}(3,1) | 0.3767 0.2157
AR{2}(1,2) | 0.0208 0.2042
AR{2}(2,2) | 0.3238 0.1058
AR{2}(3,2) | -0.4530 0.4354
AR{2}(1,3) | 0.0634 0.0487
AR{2}(2,3) | 0.0747 0.0252
AR{2}(3,3) | -0.3594 0.1038
AR{3}(1,1) | 0.4503 0.1002
AR{3}(2,1) | -0.0388 0.0519
AR{3}(3,1) | 0.3580 0.2136
AR{3}(1,2) | 0.3119 0.2008
AR{3}(2,2) | 0.0966 0.1040
AR{3}(3,2) | -0.8212 0.4282
AR{3}(1,3) | 0.0659 0.0502
AR{3}(2,3) | 0.0155 0.0260
AR{3}(3,3) | -0.0269 0.1070
AR{4}(1,1) | -0.0141 0.1046
AR{4}(2,1) | 0.0105 0.0542
AR{4}(3,1) | 0.0263 0.2231
AR{4}(1,2) | -0.2274 0.1875
AR{4}(2,2) | -0.1734 0.0972
AR{4}(3,2) | 0.1328 0.3999
AR{4}(1,3) | 0.0028 0.0456
AR{4}(2,3) | 0.0094 0.0236
AR{4}(3,3) | -0.1487 0.0973
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3597 -0.0333 0.1987
| (0.0433) (0.0161) (0.0672)
DUNRATE | -0.0333 0.0966 -0.1647
| (0.0161) (0.0116) (0.0365)
DFEDFUNDS | 0.1987 -0.1647 1.6355
| (0.0672) (0.0365) (0.1969)
Consider the 3-D VAR(4) model of Estimate Posterior Distribution.
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create a diffuse Bayesian VAR(4) prior model for the three response series. Specify the response variable names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = diffusebvarm(numseries,numlags,'SeriesNames',seriesnames);You can display estimation output in three ways, or turn off the display. Compare the display types.
estimate(PriorMdl,rmDataTimeTable{:,seriesnames}); % 'table', the defaultBayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
estimate(PriorMdl,rmDataTimeTable{:,seriesnames},...
'Display','equation');Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1241 -0.4809 0.1005 0.3236 -0.0503 0.0450 0.4272 0.2738 0.0523 0.0167 -0.1830 0.0067 0.1007
| (0.0762) (0.1536) (0.0390) (0.0868) (0.1647) (0.0413) (0.0860) (0.1620) (0.0428) (0.0901) (0.1520) (0.0395) (0.0832)
DUNRATE | -0.0219 0.4716 0.0391 0.0913 0.2414 0.0536 -0.0389 0.0552 0.0008 0.0285 -0.1795 0.0088 -0.0499
| (0.0413) (0.0831) (0.0211) (0.0469) (0.0891) (0.0223) (0.0465) (0.0876) (0.0232) (0.0488) (0.0822) (0.0214) (0.0450)
DFEDFUNDS | -0.1586 -1.4368 -0.2905 0.3403 -0.2968 -0.3117 0.2848 -0.7401 0.0028 -0.0690 0.1494 -0.1372 -0.4221
| (0.1632) (0.3287) (0.0835) (0.1857) (0.3526) (0.0883) (0.1841) (0.3466) (0.0917) (0.1928) (0.3253) (0.0845) (0.1781)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
estimate(PriorMdl,rmDataTimeTable{:,seriesnames},...
'Display','matrix');Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Coefficient Matrix of Lag 1
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1)
--------------------------------------------------
INFL | 0.1241 -0.4809 0.1005
| (0.0762) (0.1536) (0.0390)
DUNRATE | -0.0219 0.4716 0.0391
| (0.0413) (0.0831) (0.0211)
DFEDFUNDS | -0.1586 -1.4368 -0.2905
| (0.1632) (0.3287) (0.0835)
VAR Coefficient Matrix of Lag 2
| INFL(-2) DUNRATE(-2) DFEDFUNDS(-2)
--------------------------------------------------
INFL | 0.3236 -0.0503 0.0450
| (0.0868) (0.1647) (0.0413)
DUNRATE | 0.0913 0.2414 0.0536
| (0.0469) (0.0891) (0.0223)
DFEDFUNDS | 0.3403 -0.2968 -0.3117
| (0.1857) (0.3526) (0.0883)
VAR Coefficient Matrix of Lag 3
| INFL(-3) DUNRATE(-3) DFEDFUNDS(-3)
--------------------------------------------------
INFL | 0.4272 0.2738 0.0523
| (0.0860) (0.1620) (0.0428)
DUNRATE | -0.0389 0.0552 0.0008
| (0.0465) (0.0876) (0.0232)
DFEDFUNDS | 0.2848 -0.7401 0.0028
| (0.1841) (0.3466) (0.0917)
VAR Coefficient Matrix of Lag 4
| INFL(-4) DUNRATE(-4) DFEDFUNDS(-4)
--------------------------------------------------
INFL | 0.0167 -0.1830 0.0067
| (0.0901) (0.1520) (0.0395)
DUNRATE | 0.0285 -0.1795 0.0088
| (0.0488) (0.0822) (0.0214)
DFEDFUNDS | -0.0690 0.1494 -0.1372
| (0.1928) (0.3253) (0.0845)
Constant Term
INFL | 0.1007
| (0.0832)
DUNRATE | -0.0499
| 0.0450
DFEDFUNDS | -0.4221
| 0.1781
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
Return the estimation summary, which is a structure that contains the same information regardless of display type.
[PosteriorMdl,Summary] = estimate(PriorMdl,rmDataTimeTable{:,seriesnames});Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
Summary
Summary = struct with fields:
Description: "3-Dimensional VAR(4) Model"
NumEstimatedParameters: 39
Table: [39×2 table]
CoeffMap: [39×1 string]
CoeffMean: [39×1 double]
CoeffStd: [39×1 double]
SigmaMean: [3×3 double]
SigmaStd: [3×3 double]
The CoeffMap field contains a list of the coefficient names. The order of the names corresponds to the order of all coefficient vector inputs and outputs. Display CoeffMap.
Summary.CoeffMap
ans = 39×1 string
"AR{1}(1,1)"
"AR{1}(1,2)"
"AR{1}(1,3)"
"AR{2}(1,1)"
"AR{2}(1,2)"
"AR{2}(1,3)"
"AR{3}(1,1)"
"AR{3}(1,2)"
"AR{3}(1,3)"
"AR{4}(1,1)"
"AR{4}(1,2)"
"AR{4}(1,3)"
"Constant(1)"
"AR{1}(2,1)"
"AR{1}(2,2)"
"AR{1}(2,3)"
"AR{2}(2,1)"
"AR{2}(2,2)"
"AR{2}(2,3)"
"AR{3}(2,1)"
"AR{3}(2,2)"
"AR{3}(2,3)"
"AR{4}(2,1)"
"AR{4}(2,2)"
"AR{4}(2,3)"
"Constant(2)"
"AR{1}(3,1)"
"AR{1}(3,2)"
"AR{1}(3,3)"
"AR{2}(3,1)"
⋮
Consider the 3-D VAR(4) model of Estimate Posterior Distribution In this example, create a normal conjugate prior model with a fixed coefficient matrix instead of a diffuse model. The model contains 39 coefficients. For coefficient sparsity in the posterior, apply the Minnesota regularization method during estimation.
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create a normal conjugate Bayesian VAR(4) prior model for the three response series. Specify the response variable names, and set the innovations covariance matrix
According to the Minnesota regularization method, specify the following:
Each response is an AR(1) model, on average, with lag 1 coefficient 0.75.
The prior self-lag coefficients have variance 100. This large variance setting allows the data to influence the posterior more than the prior.
The prior cross-lag coefficients have variance 0.01. This small variance setting tightens the cross-lag coefficients to zero during estimation.
Prior coefficient covariances decay with increasing lag at a rate of 10 (that is, lower lags are more important than higher lags).
numseries = numel(seriesnames); numlags = 4; Sigma = [10e-5 0 10e-4; 0 0.1 -0.2; 10e-4 -0.2 1.6]; PriorMdl = bayesvarm(numseries,numlags,'Model','normal','SeriesNames',seriesnames,... 'Center',0.75,'SelfLag',100,'CrossLag',0.01,'Decay',10,... 'Sigma',Sigma);
Estimate the posterior distribution, and display the posterior response equations.
PosteriorMdl = estimate(PriorMdl,rmDataTimeTable{:,seriesnames},'Display','equation');Bayesian VAR under normal priors and fixed Sigma
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1234 -0.4373 0.1050 0.3343 -0.0342 0.0308 0.4441 0.0031 0.0090 0.0083 -0.0003 0.0003 0.0820
| (0.0014) (0.0027) (0.0007) (0.0015) (0.0021) (0.0006) (0.0015) (0.0004) (0.0003) (0.0015) (0.0001) (0.0001) (0.0014)
DUNRATE | 0.0521 0.3636 0.0125 0.0012 0.1720 0.0009 0.0000 -0.0741 -0.0000 0.0000 0.0007 -0.0000 -0.0413
| (0.0252) (0.0723) (0.0191) (0.0031) (0.0666) (0.0031) (0.0004) (0.0348) (0.0004) (0.0001) (0.0096) (0.0001) (0.0339)
DFEDFUNDS | -0.0105 -0.1394 -0.1368 0.0002 -0.0000 -0.1227 0.0000 -0.0000 0.0085 -0.0000 0.0000 -0.0041 -0.0113
| (0.0749) (0.0948) (0.0713) (0.0031) (0.0031) (0.0633) (0.0004) (0.0004) (0.0344) (0.0001) (0.0001) (0.0097) (0.1176)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
----------------------------------------
INFL | 0.0001 0 0.0010
| (0) (0) (0)
DUNRATE | 0 0.1000 -0.2000
| (0) (0) (0)
DFEDFUNDS | 0.0010 -0.2000 1.6000
| (0) (0) (0)
Compare the results to a posterior in which you specify no prior regularization.
PriorMdlNoReg = bayesvarm(numseries,numlags,'Model','normal','SeriesNames',seriesnames,... 'Sigma',Sigma); PosteriorMdlNoReg = estimate(PriorMdlNoReg,rmDataTimeTable{:,seriesnames},'Display','equation');
Bayesian VAR under normal priors and fixed Sigma
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1242 -0.4794 0.1007 0.3233 -0.0502 0.0450 0.4270 0.2734 0.0523 0.0168 -0.1823 0.0068 0.1010
| (0.0014) (0.0028) (0.0007) (0.0016) (0.0030) (0.0007) (0.0016) (0.0029) (0.0008) (0.0016) (0.0027) (0.0007) (0.0015)
DUNRATE | -0.0264 0.3428 0.0089 0.0969 0.1578 0.0292 0.0042 -0.0309 -0.0114 0.0221 -0.1071 0.0072 -0.0873
| (0.0347) (0.0714) (0.0203) (0.0356) (0.0714) (0.0203) (0.0337) (0.0670) (0.0200) (0.0326) (0.0615) (0.0186) (0.0422)
DFEDFUNDS | -0.0351 -0.1248 -0.0411 0.0416 -0.0224 -0.1358 0.0014 -0.0302 0.1557 -0.0074 -0.0010 -0.0785 -0.0205
| (0.0787) (0.0949) (0.0696) (0.0631) (0.0689) (0.0663) (0.0533) (0.0567) (0.0630) (0.0470) (0.0493) (0.0608) (0.1347)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
----------------------------------------
INFL | 0.0001 0 0.0010
| (0) (0) (0)
DUNRATE | 0 0.1000 -0.2000
| (0) (0) (0)
DFEDFUNDS | 0.0010 -0.2000 1.6000
| (0) (0) (0)
The posterior estimates of the Minnesota prior have lower magnitude, in general, compared to the estimates of the default normal conjugate prior model.
Consider the 3-D VAR(4) model of Estimate Posterior Distribution In this case, assume that the coefficients and innovations covariance matrix are independent (a semiconjugate prior model).
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create a semiconjugate Bayesian VAR(4) prior model for the three response series. Specify the response variable names.
numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'Model','semiconjugate',... 'SeriesNames',seriesnames);
Because the joint posterior of a semiconjugate prior model is analytically intractable, estimate uses a Gibbs sampler to form the joint posterior by sampling from the tractable full conditionals.
Estimate the posterior distribution. For the Gibbs sampler, specify an effective number of draws of 20,000, a burn-in period of 5000, and a thinning factor of 10.
rng(1) % For reproducibility PosteriorMdl = estimate(PriorMdl,rmDataTimeTable{:,seriesnames},... 'Display','equation','NumDraws',20000,'Burnin',5000,'Thin',10);
Bayesian VAR under semiconjugate priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.2243 -0.0824 0.1365 0.2515 -0.0098 0.0329 0.2888 0.0311 0.0368 0.0458 -0.0206 0.0176 0.1836
| (0.0662) (0.0821) (0.0319) (0.0701) (0.0636) (0.0309) (0.0662) (0.0534) (0.0297) (0.0649) (0.0470) (0.0274) (0.0720)
DUNRATE | -0.0262 0.3666 0.0148 0.0929 0.1637 0.0336 0.0016 -0.0147 -0.0089 0.0222 -0.1133 0.0082 -0.0808
| (0.0342) (0.0728) (0.0197) (0.0354) (0.0713) (0.0198) (0.0334) (0.0671) (0.0194) (0.0320) (0.0606) (0.0179) (0.0407)
DFEDFUNDS | -0.0251 -0.1285 -0.0527 0.0379 -0.0256 -0.1452 -0.0040 -0.0360 0.1516 -0.0090 0.0008 -0.0823 -0.0193
| (0.0785) (0.0962) (0.0673) (0.0630) (0.0688) (0.0643) (0.0531) (0.0567) (0.0610) (0.0467) (0.0492) (0.0586) (0.1302)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.2984 -0.0219 0.1754
| (0.0305) (0.0121) (0.0499)
DUNRATE | -0.0219 0.0890 -0.1496
| (0.0121) (0.0092) (0.0292)
DFEDFUNDS | 0.1754 -0.1496 1.4754
| (0.0499) (0.0292) (0.1506)
PosteriorMdl is an empiricalbvarm model represented by draws from the full conditionals. After removing the first burn-in period draws and thinning the remaining draws by keeping every 10th draw, estimate stores the draws in the CoeffDraws and SigmaDraws properties.
Consider the 2-D VARX(1) model for the US real GDP (RGDP) and investment (GCE) rates that treats the personal consumption (PCEC) rate as exogenous:
For all , is a series of independent 2-D normal innovations with a mean of 0 and covariance . Assume the following prior distributions:
, where M is a 4-by-2 matrix of means and is the 4-by-4 among-coefficient scale matrix. Equivalently, .
, where Ω is the 2-by-2 scale matrix and is the degrees of freedom.
Load the US macroeconomic data set. Compute the real GDP, investment, and personal consumption rate series. Remove all missing values from the resulting series.
load Data_USEconModel DataTimeTable.RGDP = DataTimeTable.GDP./DataTimeTable.GDPDEF; seriesnames = ["PCEC"; "RGDP"; "GCE"]; rates = varfun(@price2ret,DataTimeTable,'InputVariables',seriesnames); rates = rmmissing(rates); rates.Properties.VariableNames = seriesnames;
Create a conjugate prior model for the 2-D VARX(1) model parameters.
numseries = 2; numlags = 1; numpredictors = 1; PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors,... 'SeriesNames',seriesnames(2:end));
Estimate the posterior distribution. Specify the exogenous predictor data.
PosteriorMdl = estimate(PriorMdl,rates{:,2:end},...
'X',rates{:,1},'Display','equation');Bayesian VAR under conjugate priors
Effective Sample Size: 247
Number of equations: 2
Number of estimated Parameters: 8
VAR Equations
| RGDP(-1) GCE(-1) Constant X1
-----------------------------------------------
RGDP | 0.0083 -0.0027 0.0078 0.0105
| (0.0625) (0.0606) (0.0043) (0.0625)
GCE | 0.0059 0.0477 0.0166 0.0058
| (0.0644) (0.0624) (0.0044) (0.0645)
Innovations Covariance Matrix
| RGDP GCE
---------------------------
RGDP | 0.0040 0.0000
| (0.0004) (0.0003)
GCE | 0.0000 0.0043
| (0.0003) (0.0004)
By default, estimate uses the first p = 1 observations in the specified response data as a presample, and it removes the corresponding observations in the predictor data from the sample.
The posterior means (and standard deviations) of the regression coefficients appear below the X1 column of the estimation summary table.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Monte Carlo simulation is subject to variation. If
estimateuses Monte Carlo simulation, then estimates and inferences might vary when you callestimatemultiple times under seemingly equivalent conditions. To reproduce estimation results, set a random number seed by usingrngbefore callingestimate.
Algorithms
Whenever the prior distribution
PriorMdland the data likelihood yield an analytically tractable posterior distribution,estimateevaluates the closed-form solutions to Bayes estimators. Otherwise,estimateuses the Gibbs sampler to estimate the posterior.This figure illustrates how
estimatereduces the Monte Carlo sample using the values ofNumDraws,Thin, andBurnIn. Rectangles represent successive draws from the distribution.estimateremoves the white rectangles from the Monte Carlo sample. The remainingNumDrawsblack rectangles compose the Monte Carlo sample.
Version History
Introduced in R2020a