conjugatebvarm
Bayesian vector autoregression (VAR) model with conjugate prior for data likelihood
Description
The Bayesian VAR model object conjugatebvarm specifies the joint prior or posterior distribution of the array of model coefficients Λ and the innovations covariance matrix Σ of an m-D VAR(p) model. The joint prior distribution (Λ,Σ) is the dependent, matrix-normal-inverse-Wishart conjugate model.
In general, when you create a Bayesian VAR model object, it specifies the joint prior distribution and characteristics of the VARX model only. That is, the model object is a template intended for further use. Specifically, to incorporate data into the model for posterior distribution analysis, pass the model object and data to the appropriate object function.
Creation
Syntax
Description
To create a conjugatebvarm object, use either the conjugatebvarm function (described here) or the bayesvarm function. The syntaxes for each function are similar, but the options differ. bayesvarm enables you to set prior hyperparameter values for Minnesota prior[1] regularization easily, whereas conjugatebvarm requires the entire specification of prior distribution hyperparameters.
PriorMdl = conjugatebvarm(numseries,numlags)numseries-D Bayesian VAR(numlags) model object PriorMdl, which specifies dimensionalities and prior assumptions for all model coefficients and the innovations covariance Σ, where:
numseries= m, the number of response time series variables.numlags= p, the AR polynomial order.The joint prior distribution of (Λ,Σ) is the dependent, matrix-normal-inverse-Wishart conjugate model.
PriorMdl = conjugatebvarm(numseries,numlags,Name,Value)NumSeries and P) using name-value pair arguments. Enclose each property name in quotes. For example, conjugatebvarm(3,2,'SeriesNames',["UnemploymentRate" "CPI" "FEDFUNDS"]) specifies the names of the three response variables in the Bayesian VAR(2) model.
Input Arguments
Properties
Object Functions
estimate | Estimate posterior distribution of Bayesian vector autoregression (VAR) model parameters |
forecast | Forecast responses from Bayesian vector autoregression (VAR) model |
simsmooth | Simulation smoother of Bayesian vector autoregression (VAR) model |
simulate | Simulate coefficients and innovations covariance matrix of Bayesian vector autoregression (VAR) model |
summarize | Distribution summary statistics of Bayesian vector autoregression (VAR) model |
Examples
Consider the 3-D VAR(4) model for the US inflation (INFL), unemployment (UNRATE), and federal funds (FEDFUNDS) rates.
For all , is a series of independent 3-D normal innovations with a mean of 0 and covariance . Assume the following prior distributions:
, where M is a 13-by-3 matrix of means and is the 13-by-13 among-coefficient scale matrix. Equivalently, .
, where is the 3-by-3 scale matrix and is the degrees of freedom.
Create a conjugate prior model for the 3-D VAR(4) model parameters.
numseries = 3; numlags = 4; PriorMdl = conjugatebvarm(numseries,numlags)
PriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [13×13 double]
Omega: [3×3 double]
DoF: 13
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
PriorMdl is a conjugatebvarm Bayesian VAR model object representing the prior distribution of the coefficients and innovations covariance of the 3-D VAR(4) model. The command line display shows properties of the model. You can display properties by using dot notation.
Display the prior mean matrices of the four AR coefficients by setting each matrix in the cell to a variable.
AR1 = PriorMdl.AR{1}AR1 = 3×3
0 0 0
0 0 0
0 0 0
AR2 = PriorMdl.AR{2}AR2 = 3×3
0 0 0
0 0 0
0 0 0
AR3 = PriorMdl.AR{3}AR3 = 3×3
0 0 0
0 0 0
0 0 0
AR4 = PriorMdl.AR{4}AR4 = 3×3
0 0 0
0 0 0
0 0 0
conjugatebvarm centers all AR coefficients at 0 by default. The AR property is read-only, but it is derived from the writeable property Mu.
Consider a 1-D Bayesian AR(2) model for the daily NASDAQ returns from January 2, 1990 through December 31, 2001.
The priors are:
, where is a 3-by-1 vector of coefficient means and is a 3-by-3 scaled covariance matrix.
, where is the degrees of freedom and is the scale.
Create a conjugate prior model for the AR(2) model parameters.
numseries = 1; numlags = 2; PriorMdl = conjugatebvarm(numseries,numlags)
PriorMdl =
conjugatebvarm with properties:
Description: "1-Dimensional VAR(2) Model"
NumSeries: 1
P: 2
SeriesNames: "Y1"
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [3×1 double]
V: [3×3 double]
Omega: 1
DoF: 11
AR: {[0] [0]}
Constant: 0
Trend: [1×0 double]
Beta: [1×0 double]
Covariance: 0.1111
conjugatebvarm interprets the innovations covariance matrix as an inverse Wishart random variable. Because the scales and degrees of freedom hyperparameters among the inverse Wishart and inverse gamma distributions are not equal, you can adjust them by using dot notation. For example, to achieve 10 degrees of freedom for the inverse gamma interpretation, set the inverse Wishart degrees of freedom to 20.
PriorMdl.DoF = 20
PriorMdl =
conjugatebvarm with properties:
Description: "1-Dimensional VAR(2) Model"
NumSeries: 1
P: 2
SeriesNames: "Y1"
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [3×1 double]
V: [3×3 double]
Omega: 1
DoF: 20
AR: {[0] [0]}
Constant: 0
Trend: [1×0 double]
Beta: [1×0 double]
Covariance: 0.0556
In the 3-D VAR(4) model of Create Matrix-Normal-Inverse-Wishart Conjugate Prior Model, consider excluding lags 2 and 3 from the model.
You cannot exclude coefficient matrices from models, but you can specify high prior tightness on zero for coefficients that you want to exclude.
Create a conjugate prior model for the 3-D VAR(4) model parameters. Specify response variable names.
By default, AR coefficient prior means are zero. Specify high tightness values for lags 2 and 3 by setting their prior variances to 1e-6. Leave all other coefficient tightness values at their defaults:
1for AR coefficient variances1e3for constant vector variances0for all coefficient covariances
Also, for conjugate Bayesian VAR models only, MATLAB® assumes that coefficient variances are proportional across response equations. Therefore, specify variances relative to the first equation.
numseries = 3; numlags = 4; seriesnames = ["INFL"; "UNRATE"; "FEDFUNDS"]; vPhi1 = ones(1,numseries); vPhi2 = 1e-6*ones(1,numseries); vPhi3 = 1e-6*ones(1,numseries); vPhi4 = ones(1,numseries); vc = 1e3; V = diag([vPhi1 vPhi2 vPhi3 vPhi4 vc]); PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames,... 'V',V)
PriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["INFL" "UNRATE" "FEDFUNDS"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [13×13 double]
Omega: [3×3 double]
DoF: 13
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
Consider the 2-D VARX(1) model for the US real GDP (RGDP) and investment (GCE) rates that treats the personal consumption (PCEC) rate as exogenous:
For all , is a series of independent 2-D normal innovations with a mean of 0 and covariance . Assume the following prior distributions:
, where M is a 4-by-2 matrix of means and is the 4-by-4 among-coefficient scale matrix. Equivalently, .
, where Ω is the 2-by-2 scale matrix and is the degrees of freedom.
Create a conjugate prior model for the 2-D VARX(1) model parameters.
numseries = 2;
numlags = 1;
numpredictors = 1;
PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors)PriorMdl =
conjugatebvarm with properties:
Description: "2-Dimensional VAR(1) Model"
NumSeries: 2
P: 1
SeriesNames: ["Y1" "Y2"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 1
Mu: [8×1 double]
V: [4×4 double]
Omega: [2×2 double]
DoF: 12
AR: {[2×2 double]}
Constant: [2×1 double]
Trend: [2×0 double]
Beta: [2×1 double]
Covariance: [2×2 double]
Display the prior mean of the coefficients Mu with the corresponding coefficients.
coeffnames = ["phi(11)"; "phi(12)"; "c(1)"; "beta(1)"; "phi(21)"; "phi(22)"; "c(2)"; "beta(2)"]; array2table(PriorMdl.Mu,'VariableNames',{'PriorMean'},'RowNames',coeffnames)
ans=8×1 table
PriorMean
_________
phi(11) 0
phi(12) 0
c(1) 0
beta(1) 0
phi(21) 0
phi(22) 0
c(2) 0
beta(2) 0
conjugatebvarm options enable you to specify prior hyperparameter values directly, but bayesvarm options are well suited for tuning hyperparameters following the Minnesota regularization method.
Consider the 3-D VAR(4) model of Create Matrix-Normal-Inverse-Wishart Conjugate Prior Model. The model contains 39 coefficients. For coefficient sparsity, create a conjugate Bayesian VAR model by using bayesvarm. Specify the following, a priori:
Each response is an AR(1) model, on average, with lag 1 coefficient 0.75.
Prior scaled coefficient covariances decay with increasing lag at a rate of 2 (that is, lower lags are more important than higher lags).
numseries = 3; numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'ModelType','conjugate',... 'Center',0.75,'Decay',2)
PriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["Y1" "Y2" "Y3"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39×1 double]
V: [13×13 double]
Omega: [3×3 double]
DoF: 13
AR: {[3×3 double] [3×3 double] [3×3 double] [3×3 double]}
Constant: [3×1 double]
Trend: [3×0 double]
Beta: [3×0 double]
Covariance: [3×3 double]
Display the prior coefficient means in the equation of the first response.
Phi1 = PriorMdl.AR{1}Phi1 = 3×3
0.7500 0 0
0 0.7500 0
0 0 0.7500
Phi2 = PriorMdl.AR{2}Phi2 = 3×3
0 0 0
0 0 0
0 0 0
Phi3 = PriorMdl.AR{3}Phi3 = 3×3
0 0 0
0 0 0
0 0 0
Phi4 = PriorMdl.AR{4}Phi4 = 3×3
0 0 0
0 0 0
0 0 0
Display a heatmap of the prior scaled covariances of the coefficients in the first response equation.
% Create labels for the chart. numARCoeffMats = PriorMdl.NumSeries*PriorMdl.P; arcoeffnames = strings(numARCoeffMats,1); for r = numlags:-1:1 arcoeffnames(((r-1)*numseries+1):(numseries*r)) = ["\phi_{"+r+",11}" "\phi_{"+r+",12}" "\phi_{"+r+",13}"]; end heatmap(arcoeffnames,arcoeffnames,PriorMdl.V(1:end-1,1:end-1));
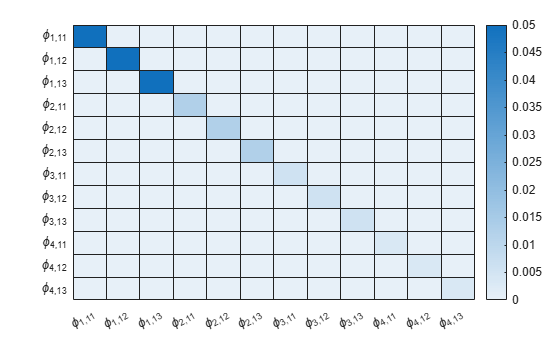
For conjugate Bayesian VAR models, scaled covariances are proportional among equations.
Consider the 3-D VAR(4) model of Create Matrix-Normal-Inverse-Wishart Conjugate Prior Model. Estimate the posterior distribution, and generate forecasts from the corresponding posterior predictive distribution.
Load and Preprocess Data
Load the US macroeconomic data set. Compute the inflation rate. Plot all response series.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; figure plot(DataTimeTable.Time,DataTimeTable{:,seriesnames}) legend(seriesnames)
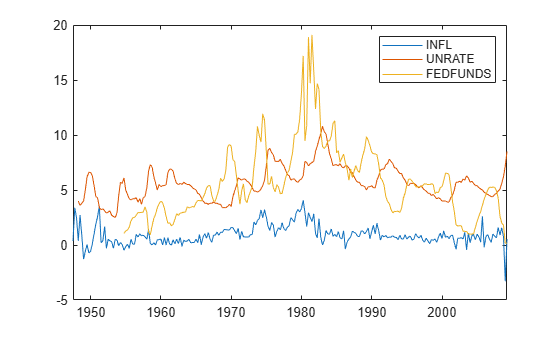
Stabilize the unemployment and federal funds rates by applying the first difference to each series.
DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)];
DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)];
seriesnames(2:3) = "D" + seriesnames(2:3);Remove all missing values from the data.
rmDataTimeTable = rmmissing(DataTimeTable);
Create Prior Model
Create a conjugate Bayesian VAR(4) prior model for the three response series. Specify the response variable names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);Estimate Posterior Distribution
Estimate the posterior distribution by passing the prior model and entire data series to estimate.
PosteriorMdl = estimate(PriorMdl,rmDataTimeTable{:,seriesnames},'Display','equation');Bayesian VAR under conjugate priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1260 -0.4400 0.1049 0.3176 -0.0545 0.0440 0.4173 0.2421 0.0515 0.0247 -0.1639 0.0080 0.1064
| (0.0713) (0.1395) (0.0366) (0.0810) (0.1490) (0.0386) (0.0802) (0.1467) (0.0400) (0.0838) (0.1385) (0.0369) (0.0774)
DUNRATE | -0.0236 0.4440 0.0350 0.0900 0.2295 0.0520 -0.0330 0.0567 0.0010 0.0298 -0.1665 0.0104 -0.0536
| (0.0396) (0.0774) (0.0203) (0.0449) (0.0827) (0.0214) (0.0445) (0.0814) (0.0222) (0.0465) (0.0768) (0.0205) (0.0430)
DFEDFUNDS | -0.1514 -1.3408 -0.2762 0.3275 -0.2971 -0.3041 0.2609 -0.6971 0.0130 -0.0692 0.1392 -0.1341 -0.3902
| (0.1517) (0.2967) (0.0777) (0.1722) (0.3168) (0.0820) (0.1705) (0.3120) (0.0851) (0.1782) (0.2944) (0.0785) (0.1646)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.2725 -0.0197 0.1407
| (0.0270) (0.0106) (0.0417)
DUNRATE | -0.0197 0.0839 -0.1290
| (0.0106) (0.0083) (0.0242)
DFEDFUNDS | 0.1407 -0.1290 1.2322
| (0.0417) (0.0242) (0.1220)
Because the prior is conjugate for the data likelihood, the posterior is a conjugatebvarm object. By default, estimate uses the first four observations as a presample to initialize the model.
Generate Forecasts from Posterior Predictive Distribution
From the posterior predictive distribution, generate forecasts over a two-year horizon. Because sampling from the posterior predictive distribution requires the entire data set, specify the prior model in forecast instead of the posterior.
fh = 8;
FY = forecast(PriorMdl,fh,rmDataTimeTable{:,seriesnames});FY is an 8-by-3 matrix of forecasts.
Plot the end of the data set and the forecasts.
fp = rmDataTimeTable.Time(end) + calquarters(1:fh);
figure
plotdata = [rmDataTimeTable{end - 10:end,seriesnames}; FY];
plot([rmDataTimeTable.Time(end - 10:end); fp'],plotdata)
hold on
plot([fp(1) fp(1)],ylim,'k-.')
legend(seriesnames)
title('Data and Forecasts')
hold off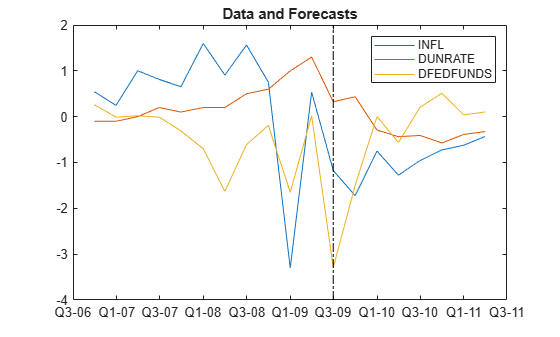
Compute Impulse Responses
Plot impulse response functions by passing posterior estimations to armairf.
armairf(PosteriorMdl.AR,[],'InnovCov',PosteriorMdl.Covariance)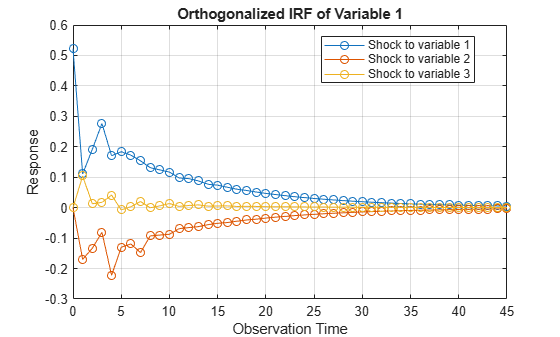
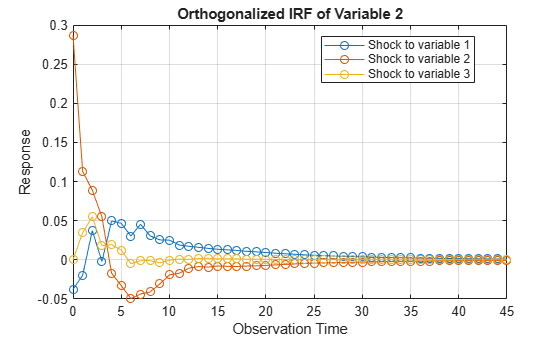
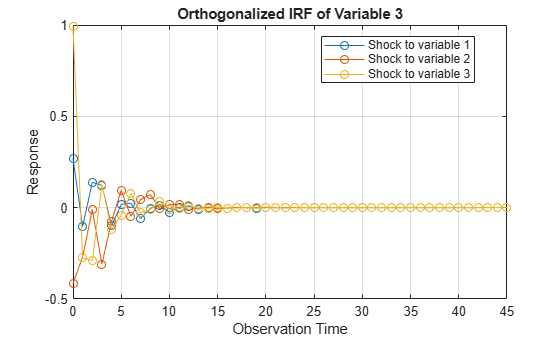
More About
Algorithms
If you pass either a
conjugatebvarmordiffusebvarmobject and data toestimate, MATLAB® returns aconjugatebvarmobject representing the posterior distribution.The conditional covariance (unscaled) of the entire vectorized matrix normal prior is Σ⊗
V. To achieve conjugacy, these conditions must be true:Prior covariances are assumed to be proportional among all equations. Σ determines the proportionality, and scales
Vduring posterior estimation.For an equation, the covariances between all AR coefficients, self lag and cross lag, are equal.
conjugatebvarmenforces the first condition, but not the second. Therefore,conjugatebvarmapplies elements ofVto all coefficients in the model relative to the coefficients in the equation of y1,t.
References
[1] Litterman, Robert B. "Forecasting with Bayesian Vector Autoregressions: Five Years of Experience." Journal of Business and Economic Statistics 4, no. 1 (January 1986): 25–38. https://doi.org/10.2307/1391384.
Version History
Introduced in R2020a