영상 분류를 위해 잔차 신경망 훈련시키기
이 예제에서는 잔차 연결을 사용하여 딥러닝 신경망을 만들고 CIFAR-10 데이터에 대해 훈련시키는 방법을 보여줍니다. 잔차 연결은 컨벌루션 신경망 아키텍처에서 자주 사용되는 요소입니다. 잔차 연결을 사용하면 신경망의 기울기 흐름이 향상되고 보다 심층의 신경망을 훈련시킬 수 있습니다.
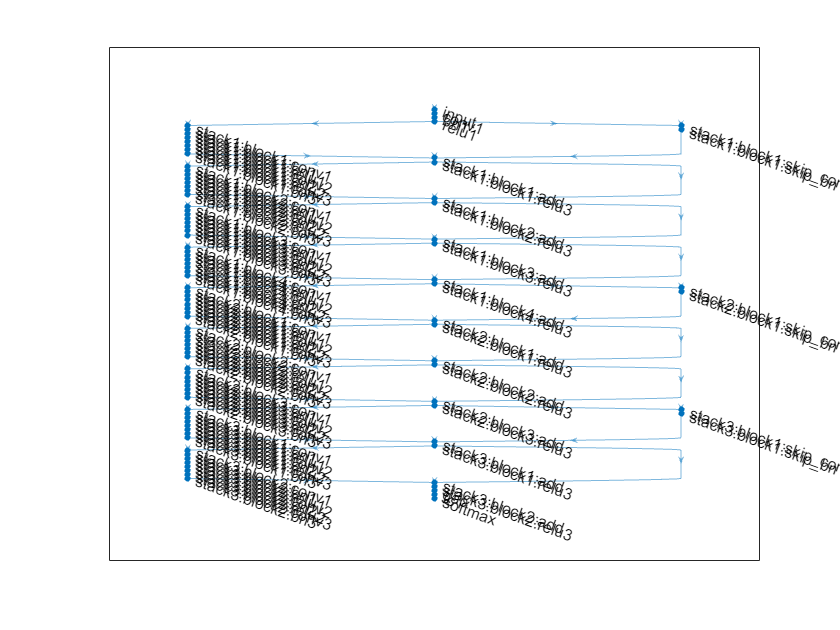
많은 응용 사례에서는 계층들의 단순한 단일 시퀀스로 구성된 하나의 신경망만 사용해도 충분합니다. 그러나 일부 응용 사례에서는 계층이 여러 계층으로부터 입력값을 받아 여러 계층으로 출력값을 보낼 수 있는 보다 복잡한 그래프 구조의 신경망이 필요합니다. 이러한 유형의 신경망을 종종 DAG(유방향 비순환 그래프) 신경망이라 부릅니다. 잔차 신경망(ResNet)은 기본 신경망 계층을 우회하는 잔차(또는 지름길) 연결을 갖는 DAG 신경망의 일종입니다. MATLAB에서 DAG 신경망은 dlnetwork 객체로 표현됩니다. 잔차 연결은 출력 계층에서 신경망의 앞쪽 계층으로 파라미터 기울기가 보다 쉽게 전파되도록 해 주므로 보다 심층의 신경망을 훈련시킬 수 있습니다. 이처럼 신경망 심도가 증가하면 더욱 어려운 작업에서 정확도가 높아질 수 있습니다.
ResNet 아키텍처는 초기 계층, 잔차 블록을 포함하는 스택, 마지막 계층으로 구성됩니다. 잔차 블록에는 다음과 같은 세 가지 유형이 있습니다.
초기 잔차 블록 — 이 블록은 첫 번째 스택의 시작 부분에 위치합니다. 이 예제는 병목 컴포넌트를 사용합니다. 때문에 이 블록은 다운샘플링 블록과 동일한 계층을 포함하되, 첫 번째 컨벌루션 계층에서
[1,1]스트라이드를 사용합니다. 자세한 내용은resnetNetwork항목을 참조하십시오.표준 잔차 블록 — 이 블록은 각 스택에서 첫 번째 다운샘플링 잔차 블록 뒤에 옵니다. 이 블록은 각 스택마다 여러 번 위치하며 활성화 크기를 유지합니다.
다운샘플링 잔차 블록 — 이 블록은 (첫 번째 스택을 제외하고) 각 스택마다 시작 부분에 한 번씩 위치합니다. 다운샘플링 블록에서 첫 번째 컨벌루션 유닛은 인자 2로 공간 차원을 다운샘플링합니다.
각 스택마다 심도가 다를 수 있습니다. 이 예제에서는 심도가 점점 감소하는 스택을 3개 사용하여 잔차 신경망을 훈련시킵니다. 첫 번째 스택은 심도 4, 두 번째 스택은 심도 3, 마지막 스택은 심도 2를 갖습니다.

각 잔차 블록에는 딥러닝 계층이 포함됩니다. 각 블록의 계층에 대한 자세한 내용은 resnetNetwork 항목을 참조하십시오.
영상 분류에 적합한 잔차 신경망을 만들고 훈련시키려면 다음 단계를 따르십시오.
resnetNetwork함수를 사용하여 잔차 신경망을 만듭니다.trainnet함수를 사용하여 신경망을 훈련시킵니다. 훈련된 신경망은dlnetwork객체가 됩니다.새 데이터에 대해 분류와 예측을 수행합니다.
영상 분류를 위해 사전 훈련된 잔차 신경망을 불러올 수도 있습니다. 자세한 내용은 사전 훈련된 심층 신경망 항목을 참조하십시오.
데이터 준비하기
CIFAR-10 데이터 세트를 다운로드합니다[1]. 이 데이터 세트에는 60,000개의 영상이 포함되어 있습니다. 각 영상은 크기가 32×32 픽셀이고 3개의 색 채널(RGB)을 갖습니다. 데이터 세트의 크기는 175MB입니다. 인터넷 연결에 따라 다운로드 과정에 약간의 시간이 걸릴 수 있습니다.
datadir = tempdir; downloadCIFARData(datadir);
Downloading CIFAR-10 dataset (175 MB). This can take a while...done.
CIFAR-10 훈련 및 테스트 영상을 4차원 배열로 불러옵니다. 훈련 세트에는 50,000개의 영상이 포함되어 있고, 테스트 세트에는 10,000개의 영상이 포함되어 있습니다. 신경망 검증을 위해 CIFAR-10 테스트 영상을 사용합니다.
[XTrain,TTrain,XValidation,TValidation] = loadCIFARData(datadir);
다음 코드를 사용하여 훈련 영상에서 임의의 샘플을 표시할 수 있습니다.
figure; idx = randperm(size(XTrain,4),20); im = imtile(XTrain(:,:,:,idx),ThumbnailSize=[96,96]); imshow(im)
신경망 훈련에 사용할 augmentedImageDatastore 객체를 만듭니다. 훈련 중에 데이터저장소는 세로 축을 따라 훈련 영상을 무작위로 뒤집고 최대 4개의 픽셀을 가로와 세로 방향으로 무작위로 평행 이동합니다. 데이터 증강은 신경망이 과적합되는 것을 방지하고 훈련 영상의 정확한 세부 정보가 기억되지 않도록 하는 데 도움이 됩니다.
imageSize = [32 32 3]; pixelRange = [-4 4]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(imageSize,XTrain,TTrain, ... DataAugmentation=imageAugmenter, ... OutputSizeMode="randcrop");
신경망 아키텍처 정의하기
resnetNetwork 함수를 사용하여 이 데이터 세트에 적합한 잔차 신경망을 만듭니다.
CIFAR-10 영상은 32×32 픽셀이므로 초기 필터 크기는 작게 3을 사용하고 초기 스트라이드는 1을 사용합니다. 초기 필터 개수를 16으로 설정합니다.
신경망의 첫 번째 스택은 초기 잔차 블록으로 시작합니다. 그 뒤에 오는 각 스택은 다운샘플링 잔차 블록으로 시작합니다. 다운샘플링 블록에서 첫 번째 컨벌루션 유닛은 인자 2로 공간 차원을 다운샘플링합니다. 전체 신경망에서 각 컨벌루션 계층에 필요한 연산량이 대략 같도록 하려면 공간적 다운샘플링을 수행할 때마다 필터의 개수를 2배만큼 늘리십시오. 스택 심도를
[4 3 2]로, 필터 개수를[16 32 64]로 설정합니다.
initialFilterSize = 3; numInitialFilters = 16; initialStride = 1; numFilters = [16 32 64]; stackDepth = [4 3 2];
2차원 잔차 신경망을 만듭니다.
net = resnetNetwork(imageSize,10, ... InitialFilterSize=initialFilterSize, ... InitialNumFilters=numInitialFilters, ... InitialStride=initialStride, ... InitialPoolingLayer="none", ... StackDepth=[4 3 2], ... NumFilters=[16 32 64]);
신경망을 시각화합니다.
plot(net);
훈련 옵션
훈련 옵션을 지정합니다. Epoch 80회에 대해 신경망을 훈련시킵니다. 미니 배치 크기에 비례하는 학습률을 선택하고, Epoch 60회가 지나면 학습률을 10배만큼 줄입니다. 검증 데이터를 사용하여 Epoch당 한 번씩 신경망을 검증합니다.
miniBatchSize = 128; learnRate = 0.1*miniBatchSize/128; valFrequency = floor(size(XTrain,4)/miniBatchSize); options = trainingOptions("sgdm", ... InitialLearnRate=learnRate, ... MaxEpochs=80, ... MiniBatchSize=miniBatchSize, ... VerboseFrequency=valFrequency, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationData={XValidation,TValidation}, ... ValidationFrequency=valFrequency, ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.1, ... LearnRateDropPeriod=60);
신경망 훈련시키기
trainnet을 사용하여 신경망을 훈련시키려면 doTraining 플래그를 true로 설정하십시오. 분류에는 교차 엔트로피 손실을 사용합니다. 기본적으로 trainnet 함수는 GPU를 사용할 수 있으면 GPU를 사용합니다. GPU에서 훈련시키려면 Parallel Computing Toolbox™ 라이선스와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오. GPU를 사용할 수 없는 경우, trainnet 함수는 CPU를 사용합니다. 실행 환경을 지정하려면 ExecutionEnvironment 훈련 옵션을 사용하십시오.
그렇지 않은 경우에는 사전 훈련된 신경망을 불러옵니다.
doTraining = false; if doTraining net = trainnet(augimdsTrain,net,'crossentropy',options); else load("trainedResidualNetwork.mat","net"); end

훈련된 신경망 평가하기
(데이터 증강이 적용되지 않은) 훈련 세트와 검증 세트에 대해 신경망의 최종 정확도를 계산합니다. 여러 개의 관측값을 사용하여 예측을 수행하려면 minibatchpredict 함수를 사용합니다. 예측 점수를 레이블로 변환하려면 scores2label 함수를 사용합니다. minibatchpredict 함수는 GPU를 사용할 수 있으면 자동으로 GPU를 사용합니다. GPU를 사용하려면 Parallel Computing Toolbox™ 라이선스와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오. GPU를 사용할 수 없는 경우, 함수는 CPU를 사용합니다.
scores = minibatchpredict(net,XValidation); [YValPred,probs] = scores2label(scores,categories(TValidation)); validationError = mean(YValPred ~= TValidation); scores = minibatchpredict(net,XTrain); YTrainPred = scores2label(scores,categories(TTrain)); trainError = mean(YTrainPred ~= TTrain); disp("Training error: " + trainError*100 + "%")
Training error: 4.168%
disp("Validation error: " + validationError*100 + "%")
Validation error: 9.13%
혼동행렬을 플로팅합니다. 열 및 행 요약을 사용하여 각 클래스의 정밀도를 표시하고 다시 호출합니다. 신경망은 고양이와 개를 가장 많이 혼동하고 있습니다.
figure(Units="normalized",Position=[0.2 0.2 0.4 0.4]); cm = confusionchart(TValidation,YValPred); cm.Title = "Confusion Matrix for Validation Data"; cm.ColumnSummary = "column-normalized"; cm.RowSummary = "row-normalized";

다음 코드를 사용하여 테스트 영상 9개의 무작위 샘플을 예측된 클래스 및 해당 클래스의 확률과 함께 표시할 수 있습니다.
figure idx = randperm(size(XValidation,4),9); for i = 1:numel(idx) subplot(3,3,i) imshow(XValidation(:,:,:,idx(i))); prob = num2str(100*max(probs(idx(i),:)),3); predClass = char(YValPred(idx(i))); title([predClass + ", " + prob + "%"]) end
참고 문헌
[1] Krizhevsky, Alex. "Learning multiple layers of features from tiny images." (2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
참고 항목
trainnet | trainingOptions | dlnetwork | resnetNetwork | resnet3dNetwork | analyzeNetwork