베이즈 최적화를 사용한 딥러닝
이 예제에서는 딥러닝에 베이즈 최적화를 적용하여 컨벌루션 신경망을 위한 최적의 신경망 하이퍼파라미터와 훈련 옵션을 찾는 방법을 보여줍니다.
심층 신경망을 훈련시키려면 신경망 아키텍처와 훈련 알고리즘 옵션을 지정해야 합니다. 이러한 하이퍼파라미터를 선택하고 조정하는 것은 쉽지 않고 시간이 걸릴 수 있습니다. 베이즈 최적화는 분류 및 회귀 모델의 하이퍼파라미터를 최적화하는 데 적합한 알고리즘입니다. 베이즈 최적화는 미분 불가능하고, 불연속이고, 계산에 시간이 걸리는 함수를 최적화하는 데 사용할 수 있습니다. 이 알고리즘은 내부적으로 목적 함수의 가우스 과정 모델을 유지하며, 이 모델을 훈련시키기 위해 목적 함수 계산을 수행합니다.
이 예제에서는 다음을 수행하는 방법을 보여줍니다.
신경망 훈련을 위해 CIFAR-10 데이터 세트 다운로드 및 준비. 이 데이터 세트는 영상 분류 모델 테스트에 가장 많이 사용되는 데이터 세트입니다.
베이즈 최적화를 사용하여 최적화할 변수 지정. 이러한 변수에는 훈련 알고리즘 옵션과 신경망 아키텍처 자체의 파라미터가 있습니다.
목적 함수 정의. 이 목적 함수는 최적화 변수의 값을 입력값으로 받고, 신경망 아키텍처 및 훈련 옵션을 지정하고, 신경망을 훈련 및 검증하고, 훈련된 신경망을 디스크에 저장합니다. 목적 함수는 이 스크립트의 끝에서 정의합니다.
검증 세트에 대한 분류 오차를 최소화하여 베이즈 최적화 수행.
디스크에서 최적의 신경망을 불러오고 테스트 세트에서 평가.
또는 실험 관리자에서 베이즈 최적화를 사용하여 최적 훈련 옵션을 찾을 수도 있습니다. 자세한 내용은 Tune Experiment Hyperparameters by Using Bayesian Optimization 항목을 참조하십시오.
데이터 준비하기
CIFAR-10 데이터 세트를 다운로드합니다[1]. 이 데이터 세트는 각각 크기가 32×32이고 3개의 색 채널(RGB)을 갖는 영상 60,000개를 포함합니다. 전체 데이터 세트의 크기는 175MB입니다. 인터넷 연결에 따라 다운로드가 완료되기까지 얼마간의 시간이 걸릴 수 있습니다.
datadir = tempdir; downloadCIFARData(datadir);
CIFAR-10 데이터 세트를 훈련 영상과 레이블, 그리고 테스트 영상과 레이블로 불러옵니다. 신경망 검증을 위해 테스트 영상 중 5,000개를 검증용으로 사용합니다.
[XTrain,YTrain,XTest,YTest] = loadCIFARData(datadir); idx = randperm(numel(YTest),5000); XValidation = XTest(:,:,:,idx); XTest(:,:,:,idx) = []; YValidation = YTest(idx); YTest(idx) = [];
다음 코드를 사용하여 훈련 영상에서 샘플을 표시할 수 있습니다.
figure; idx = randperm(numel(YTrain),20); for i = 1:numel(idx) subplot(4,5,i); imshow(XTrain(:,:,:,idx(i))); end
최적화할 변수 선택하기
베이즈 최적화를 사용하여 최적화할 변수를 선택하고 탐색할 범위를 지정합니다. 변수가 정수인지, 간격을 로그 간격으로 탐색할 것인지 여부도 지정합니다. 다음 변수를 최적화합니다.
신경망 섹션 심도. 이 파라미터는 신경망의 심도를 제어합니다. 신경망은 각각
SectionDepth개의 동일한 컨벌루션 계층을 갖는 3개의 섹션으로 구성되어 있습니다. 따라서 컨벌루션 계층의 총 개수는3*SectionDepth가 됩니다. 이 스크립트의 나중에 나오는 목적 함수는 각 계층에서1/sqrt(SectionDepth)에 비례하는 컨벌루션 필터의 개수를 받습니다. 그 결과 파라미터의 개수와 각 반복에 필요한 연산량은 서로 다른 섹션 심도에서도 대략 같습니다.초기 학습률. 가장 좋은 학습률은 데이터, 그리고 훈련시키는 신경망에 따라 달라질 수 있습니다.
확률적 경사하강 모멘텀. 모멘텀은 현재 업데이트가 직전 반복의 업데이트에 비례하는 비중을 포함하도록 함으로써 파라미터 업데이트에 관성을 더합니다. 그 결과 파라미터 업데이트가 보다 매끄러워지고 확률적 경사하강법에 내재된 잡음이 줄어듭니다.
L2 정규화 강도. 정규화를 사용하여 과적합을 방지합니다. 정규화 강도의 공간을 탐색하여 좋은 값을 찾습니다. 데이터 증강과 배치 정규화도 신경망을 정규화하는 데 도움이 됩니다.
optimVars = [
optimizableVariable('SectionDepth',[1 3],'Type','integer')
optimizableVariable('InitialLearnRate',[1e-2 1],'Transform','log')
optimizableVariable('Momentum',[0.8 0.98])
optimizableVariable('L2Regularization',[1e-10 1e-2],'Transform','log')];베이즈 최적화 수행하기
훈련 데이터와 검증 데이터를 입력값으로 사용하여 베이즈 최적화 함수의 목적 함수를 만듭니다. 목적 함수는 컨벌루션 신경망을 훈련시키고 검증 세트에 대한 분류 오차를 반환합니다. 이 함수는 스크립트의 끝부분에 정의되어 있습니다. bayesopt 는 검증 세트에서 오차율을 사용하여 최상의 모델을 선택하기 때문에 최종 신경망이 검증 세트에 과적합될 수 있습니다. 그런 다음, 최종 선택된 모델은 일반화 오차를 추정하기 위해 독립적인 테스트 세트에서 테스트됩니다.
ObjFcn = makeObjFcn(XTrain,YTrain,XValidation,YValidation);
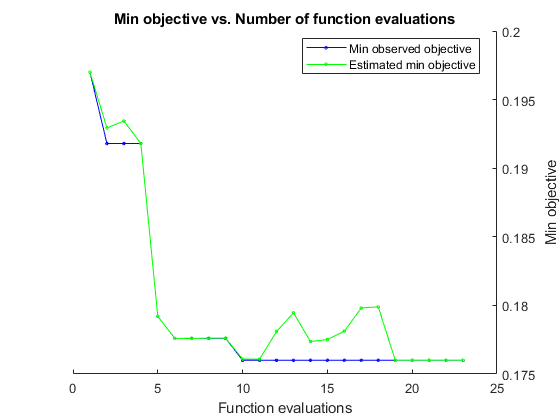
검증 세트에 대한 분류 오차를 최소화하여 베이즈 최적화 수행. 총 최적화 시간을 초 단위로 지정합니다. 베이즈 최적화의 강력한 기능을 가장 잘 활용하려면 목적 함수의 값을 적어도 30번 이상 계산해야 합니다. 여러 개의 GPU에서 신경망을 병렬로 훈련시키려면 'UseParallel' 값을 true로 설정하십시오. GPU가 1개만 있는데 'UseParallel' 값을 true로 설정하면 모든 워커가 하나의 GPU를 공유하게 되고 훈련 속도가 빨라지지 않으며 GPU에서 메모리 부족이 발생할 가능성이 높아집니다.
각 신경망의 훈련이 끝나면 bayesopt가 명령 창에 결과를 출력합니다. 그런 다음 bayesopt 함수가 BayesObject.UserDataTrace에 파일 이름을 반환합니다. 목적 함수는 훈련된 신경망을 디스크에 저장하고 bayesopt에 파일 이름을 반환합니다.
BayesObject = bayesopt(ObjFcn,optimVars, ... 'MaxTime',14*60*60, ... 'IsObjectiveDeterministic',false, ... 'UseParallel',false);
|===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | SectionDepth | InitialLearn-| Momentum | L2Regulariza-| | | result | | runtime | (observed) | (estim.) | | Rate | | tion | |===================================================================================================================================| | 1 | Best | 0.197 | 955.69 | 0.197 | 0.197 | 3 | 0.61856 | 0.80624 | 0.00035179 |
| 2 | Best | 0.1918 | 790.38 | 0.1918 | 0.19293 | 2 | 0.074118 | 0.91031 | 2.7229e-09 |
| 3 | Accept | 0.2438 | 660.29 | 0.1918 | 0.19344 | 1 | 0.051153 | 0.90911 | 0.00043113 |
| 4 | Accept | 0.208 | 672.81 | 0.1918 | 0.1918 | 1 | 0.70138 | 0.81923 | 3.7783e-08 |
| 5 | Best | 0.1792 | 844.07 | 0.1792 | 0.17921 | 2 | 0.65156 | 0.93783 | 3.3663e-10 |
| 6 | Best | 0.1776 | 851.49 | 0.1776 | 0.17759 | 2 | 0.23619 | 0.91932 | 1.0007e-10 |
| 7 | Accept | 0.2232 | 883.5 | 0.1776 | 0.17759 | 2 | 0.011147 | 0.91526 | 0.0099842 |
| 8 | Accept | 0.2508 | 822.65 | 0.1776 | 0.17762 | 1 | 0.023919 | 0.91048 | 1.0002e-10 |
| 9 | Accept | 0.1974 | 1947.6 | 0.1776 | 0.17761 | 3 | 0.010017 | 0.97683 | 5.4603e-10 |
| 10 | Best | 0.176 | 1938.4 | 0.176 | 0.17608 | 2 | 0.3526 | 0.82381 | 1.4244e-07 |
| 11 | Accept | 0.1914 | 2874.4 | 0.176 | 0.17608 | 3 | 0.079847 | 0.86801 | 9.7335e-07 |
| 12 | Accept | 0.181 | 2578 | 0.176 | 0.17809 | 2 | 0.35141 | 0.80202 | 4.5634e-08 |
| 13 | Accept | 0.1838 | 2410.8 | 0.176 | 0.17946 | 2 | 0.39508 | 0.95968 | 9.3856e-06 |
| 14 | Accept | 0.1786 | 2490.6 | 0.176 | 0.17737 | 2 | 0.44857 | 0.91827 | 1.0939e-10 |
| 15 | Accept | 0.1776 | 2668 | 0.176 | 0.17751 | 2 | 0.95793 | 0.85503 | 1.0222e-05 |
| 16 | Accept | 0.1824 | 3059.8 | 0.176 | 0.17812 | 2 | 0.41142 | 0.86931 | 1.447e-06 |
| 17 | Accept | 0.1894 | 3091.5 | 0.176 | 0.17982 | 2 | 0.97051 | 0.80284 | 1.5836e-10 |
| 18 | Accept | 0.217 | 2794.5 | 0.176 | 0.17989 | 1 | 0.2464 | 0.84428 | 4.4938e-06 |
| 19 | Accept | 0.2358 | 4054.2 | 0.176 | 0.17601 | 3 | 0.22843 | 0.9454 | 0.00098248 |
| 20 | Accept | 0.2216 | 4411.7 | 0.176 | 0.17601 | 3 | 0.010847 | 0.82288 | 2.4756e-08 |
|===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | SectionDepth | InitialLearn-| Momentum | L2Regulariza-| | | result | | runtime | (observed) | (estim.) | | Rate | | tion | |===================================================================================================================================| | 21 | Accept | 0.2038 | 3906.4 | 0.176 | 0.17601 | 2 | 0.09885 | 0.81541 | 0.0021184 |
| 22 | Accept | 0.2492 | 4103.4 | 0.176 | 0.17601 | 2 | 0.52313 | 0.83139 | 0.0016269 |
| 23 | Accept | 0.1814 | 4240.5 | 0.176 | 0.17601 | 2 | 0.29506 | 0.84061 | 6.0203e-10 |
__________________________________________________________
Optimization completed.
MaxTime of 50400 seconds reached.
Total function evaluations: 23
Total elapsed time: 53088.5123 seconds
Total objective function evaluation time: 53050.7026
Best observed feasible point:
SectionDepth InitialLearnRate Momentum L2Regularization
____________ ________________ ________ ________________
2 0.3526 0.82381 1.4244e-07
Observed objective function value = 0.176
Estimated objective function value = 0.17601
Function evaluation time = 1938.4483
Best estimated feasible point (according to models):
SectionDepth InitialLearnRate Momentum L2Regularization
____________ ________________ ________ ________________
2 0.3526 0.82381 1.4244e-07
Estimated objective function value = 0.17601
Estimated function evaluation time = 1898.2641
최종 신경망 평가하기
최적화를 통해 찾은 가장 좋은 신경망과 그 검증 정확도를 불러옵니다.
bestIdx = BayesObject.IndexOfMinimumTrace(end);
fileName = BayesObject.UserDataTrace{bestIdx};
savedStruct = load(fileName);
valError = savedStruct.valErrorvalError = 0.1760
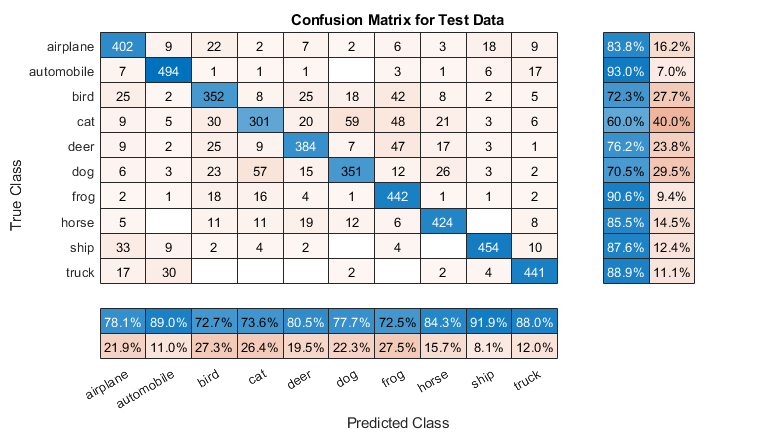
테스트 세트의 레이블을 예측하고 테스트 오차를 계산합니다. 테스트 세트에 포함된 각 영상에 대한 분류를 특정한 성공 확률을 갖는 독립적인 이벤트로 취급합니다. 즉, 잘못 분류된 영상의 개수는 이항분포를 따릅니다. 이를 바탕으로 표준 오차(testErrorSE)와 일반화 오차율의 약 95% 신뢰구간(testError95CI)을 계산합니다. 이 방법을 종종 왈드(Wald) 방법이라고 합니다. bayesopt는 신경망을 테스트 세트에 노출하지 않으면서 검증 세트를 사용하여 가장 좋은 신경망을 결정합니다. 이 시점에서 테스트 오차가 검증 오차보다 높을 수 있습니다.
[YPredicted,probs] = classify(savedStruct.trainedNet,XTest); testError = 1 - mean(YPredicted == YTest)
testError = 0.1910
NTest = numel(YTest); testErrorSE = sqrt(testError*(1-testError)/NTest); testError95CI = [testError - 1.96*testErrorSE, testError + 1.96*testErrorSE]
testError95CI = 1×2
0.1801 0.2019
테스트 데이터에 대해 혼동행렬을 플로팅합니다. 열 및 행 요약을 사용하여 각 클래스의 정밀도를 표시하고 다시 호출합니다.
figure('Units','normalized','Position',[0.2 0.2 0.4 0.4]); cm = confusionchart(YTest,YPredicted); cm.Title = 'Confusion Matrix for Test Data'; cm.ColumnSummary = 'column-normalized'; cm.RowSummary = 'row-normalized';
다음 코드를 사용하여 몇 개의 테스트 영상을 예측된 클래스 및 해당 클래스의 확률과 함께 표시할 수 있습니다.
figure idx = randperm(numel(YTest),9); for i = 1:numel(idx) subplot(3,3,i) imshow(XTest(:,:,:,idx(i))); prob = num2str(100*max(probs(idx(i),:)),3); predClass = char(YPredicted(idx(i))); label = [predClass,', ',prob,'%']; title(label) end
최적화를 위한 목적 함수
최적화를 위한 목적 함수를 정의합니다. 이 함수는 다음과 같은 단계를 수행합니다.
최적화 변수의 값을 입력값으로 받습니다.
bayesopt는 변수 이름과 같은 열 이름을 갖는 테이블에 최적화 변수의 현재 값을 포함하여 목적 함수를 호출합니다. 예를 들어, 신경망 섹션 심도의 현재 값은optVars.SectionDepth입니다.신경망 아키텍처와 훈련 옵션을 정의합니다.
신경망을 훈련시키고 검증합니다.
훈련된 신경망, 검증 오차, 훈련 옵션을 디스크에 저장합니다.
저장된 신경망의 검증 오차와 파일 이름을 반환합니다.
function ObjFcn = makeObjFcn(XTrain,YTrain,XValidation,YValidation) ObjFcn = @valErrorFun; function [valError,cons,fileName] = valErrorFun(optVars)
컨벌루션 신경망 아키텍처를 정의합니다.
공간 출력 크기가 항상 입력 크기와 같도록 컨벌루션 계층에 채우기를 추가합니다.
최댓값 풀링 계층을 사용하여 공간 차원을 인자 2로 다운샘플링할 때마다 필터의 개수를 2배만큼 늘립니다. 이를 통해 각 컨벌루션 계층에 필요한 연산량이 대략 같아지게 됩니다.
서로 다른 심도를 갖는 신경망이 대략 같은 개수의 파라미터를 갖고 반복당 필요한 연산량이 대략 같아지도록
1/sqrt(SectionDepth)에 비례하는 필터 개수를 선택합니다. 신경망 파라미터의 개수와 신경망의 전체적인 유연성을 높이려면numF를 높이십시오. 보다 심층의 신경망을 훈련시키려면SectionDepth변수의 범위를 변경하십시오.convBlock(filterSize,numFilters,numConvLayers)를 사용하여 각각filterSize와numFilters개의 필터가 지정되어 있고 연이어 배치 정규화 계층과 ReLU 계층이 오는numConvLayers컨벌루션 계층 블록을 만듭니다.convBlock함수는 이 예제의 끝에서 정의됩니다.
imageSize = [32 32 3];
numClasses = numel(unique(YTrain));
numF = round(16/sqrt(optVars.SectionDepth));
layers = [
imageInputLayer(imageSize)
% The spatial input and output sizes of these convolutional
% layers are 32-by-32, and the following max pooling layer
% reduces this to 16-by-16.
convBlock(3,numF,optVars.SectionDepth)
maxPooling2dLayer(3,'Stride',2,'Padding','same')
% The spatial input and output sizes of these convolutional
% layers are 16-by-16, and the following max pooling layer
% reduces this to 8-by-8.
convBlock(3,2*numF,optVars.SectionDepth)
maxPooling2dLayer(3,'Stride',2,'Padding','same')
% The spatial input and output sizes of these convolutional
% layers are 8-by-8. The global average pooling layer averages
% over the 8-by-8 inputs, giving an output of size
% 1-by-1-by-4*initialNumFilters. With a global average
% pooling layer, the final classification output is only
% sensitive to the total amount of each feature present in the
% input image, but insensitive to the spatial positions of the
% features.
convBlock(3,4*numF,optVars.SectionDepth)
averagePooling2dLayer(8)
% Add the fully connected layer and the final softmax and
% classification layers.
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer];신경망 훈련 옵션을 지정합니다. 초기 학습률, SGD 모멘텀 및 L2 정규화 강도를 최적화합니다.
검증 데이터를 지정하고, trainNetwork가 Epoch당 한 번씩 신경망을 검증하도록 'ValidationFrequency' 값을 선택합니다. 고정된 횟수의 Epoch에 대해 훈련시키고, 마지막 몇 회의 Epoch에서는 학습률을 10배만큼 떨어뜨립니다. 이렇게 하면 파라미터 업데이트의 잡음이 줄어들고 신경망 파라미터가 손실 함수의 최솟값에 근접하게 안정화됩니다.
miniBatchSize = 256;
validationFrequency = floor(numel(YTrain)/miniBatchSize);
options = trainingOptions('sgdm', ...
'InitialLearnRate',optVars.InitialLearnRate, ...
'Momentum',optVars.Momentum, ...
'MaxEpochs',60, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',40, ...
'LearnRateDropFactor',0.1, ...
'MiniBatchSize',miniBatchSize, ...
'L2Regularization',optVars.L2Regularization, ...
'Shuffle','every-epoch', ...
'Verbose',false, ...
'Plots','training-progress', ...
'ValidationData',{XValidation,YValidation}, ...
'ValidationFrequency',validationFrequency);데이터 증강을 사용하여 세로 축을 따라 훈련 영상을 무작위로 뒤집고 최대 4개의 픽셀을 가로와 세로 방향으로 무작위로 평행 이동합니다. 데이터 증강은 신경망이 과적합되는 것을 방지하고 훈련 영상의 정확한 세부 정보가 기억되지 않도록 하는 데 도움이 됩니다.
pixelRange = [-4 4];
imageAugmenter = imageDataAugmenter( ...
'RandXReflection',true, ...
'RandXTranslation',pixelRange, ...
'RandYTranslation',pixelRange);
datasource = augmentedImageDatastore(imageSize,XTrain,YTrain,'DataAugmentation',imageAugmenter);신경망을 훈련시키고 훈련 중에 훈련 진행 상황을 플로팅합니다. 훈련이 끝나면 훈련 플롯을 모두 닫습니다.
trainedNet = trainNetwork(datasource,layers,options);
close(findall(groot,'Tag','NNET_CNN_TRAININGPLOT_UIFIGURE'))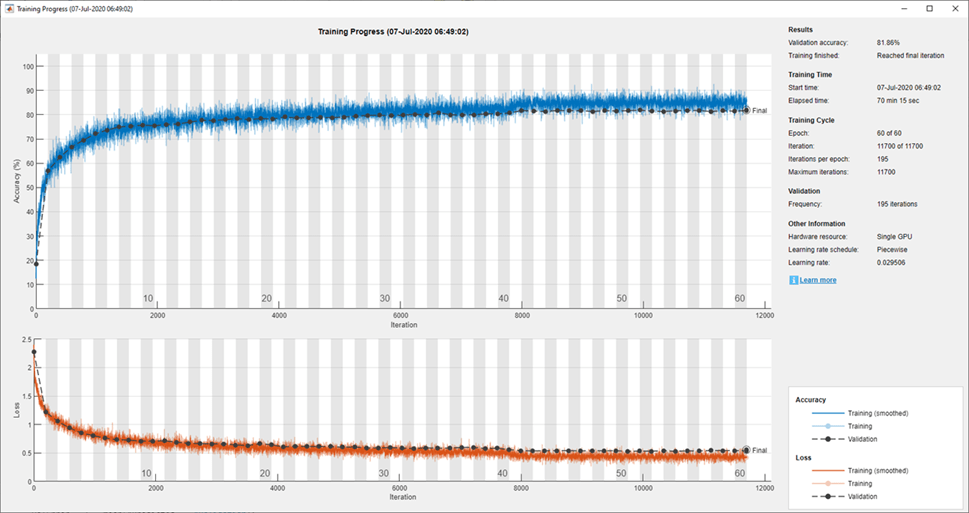
훈련된 신경망을 검증 세트에 대해 실행하고, 예측된 영상 레이블을 계산하고, 검증 데이터에 대한 오차율을 계산합니다.
YPredicted = classify(trainedNet,XValidation);
valError = 1 - mean(YPredicted == YValidation);검증 오차를 포함하는 파일 이름을 만들고, 신경망, 검증 오차, 훈련 옵션을 디스크에 저장합니다. 목적 함수는 fileName을 출력 인수로 반환하고, bayesopt는 BayesObject.UserDataTrace에 모든 파일 이름을 반환합니다. 추가로 필요한 출력 인수 cons는 변수에 대한 제약 조건을 지정합니다. 변수 제약 조건은 없습니다.
fileName = num2str(valError) + ".mat"; save(fileName,'trainedNet','valError','options') cons = []; end end
convBlock 함수는 각각 filterSize와 numFilters개의 필터가 지정되어 있고 연이어 배치 정규화 계층과 ReLU 계층이 오는 numConvLayers 컨벌루션 계층 블록을 만듭니다.
function layers = convBlock(filterSize,numFilters,numConvLayers) layers = [ convolution2dLayer(filterSize,numFilters,'Padding','same') batchNormalizationLayer reluLayer]; layers = repmat(layers,numConvLayers,1); end
참고 문헌
[1] Krizhevsky, Alex. "Learning multiple layers of features from tiny images." (2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
참고 항목
실험 관리자 | trainnet | trainingOptions | dlnetwork | bayesopt (Statistics and Machine Learning Toolbox)