이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
시계열 전망 시작하기
이 예제에서는 심층 신경망 디자이너 앱을 사용하여, 시계열 데이터를 전망하는 간단한 장단기 기억(LSTM) 신경망을 만드는 방법을 보여줍니다.
LSTM 신경망은 루프를 사용하여 시간 스텝을 순회하고 순환 신경망(RNN) 상태를 업데이트하여 입력 데이터를 처리하는 RNN입니다. RNN 상태에는 모든 이전 시간 스텝에서 기억한 정보가 포함됩니다. LSTM 신경망을 사용하면 이전 시간 스텝을 입력값으로 사용해서 시계열 또는 시퀀스의 후속 값을 전망할 수 있습니다.
시퀀스 데이터 불러오기
WaveformData에서 예제 데이터를 불러옵니다. 이 데이터에 액세스하려면 예제를 라이브 스크립트로 여십시오. 파형 데이터 세트는 3개 채널로 이루어진 다양한 길이로 생성된 합성 파형 데이터를 포함합니다. 이 예제에서는 이전 시간 스텝에서 주어진 값으로 파형의 미래 값을 전망하는 LSTM 신경망을 훈련시킵니다.
load WaveformData시퀀스 중 일부를 시각화합니다.
idx = 1;
numChannels = size(data{idx},2);
figure
stackedplot(data{idx},DisplayLabels="Channel " + (1:numChannels))이 예제에서는 훈련을 위한 데이터를 준비하기 위해 이 예제에 지원 파일로 첨부된 헬퍼 함수 prepareForecastingData를 사용합니다. 이 함수는 다음 단계를 통해 데이터를 준비합니다.
시퀀스의 미래 시간 스텝 값을 전망하려면 목표값을 시간 스텝 하나만큼 값이 이동된 훈련 시퀀스로 지정하십시오. LSTM 신경망은 입력 시퀀스의 시간 스텝마다 다음 시간 스텝의 값을 예측하도록 학습합니다. 훈련 시퀀스의 마지막 시간 스텝은 포함하지 마십시오.
데이터의 90%가 포함된 훈련 세트와 데이터의 10%가 포함된 테스트 세트로 데이터를 분할합니다.
[XTrain,TTrain,XTest,TTest] = prepareForecastingData(data,[0.9 0.1]);
더 적합한 피팅을 위해, 그리고 훈련의 발산을 방지하기 위해 채널의 평균이 0, 분산이 1이 되도록 예측 변수와 목표값을 정규화할 수 있습니다. 예측을 수행할 때는 훈련 데이터와 동일한 통계량을 사용하여 테스트 데이터도 정규화해야 합니다. 자세한 내용은 항목을 참조하십시오.
신경망 아키텍처 정의하기
신경망을 구축하기 위해 심층 신경망 디자이너 앱을 엽니다.
deepNetworkDesigner
시퀀스 신경망을 만들기 위해 Sequence-to-Sequence 분류 신경망(훈련되지 않음) 섹션에서 LSTM을 클릭합니다.
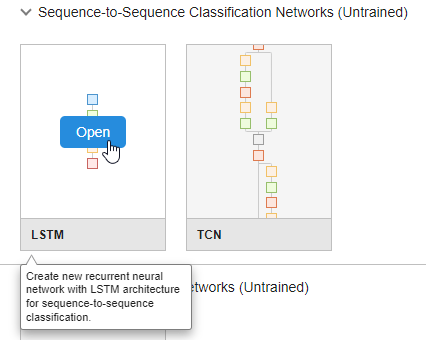
이렇게 하면 시퀀스 분류 문제에 적합한 사전 작성된 신경망이 열립니다. 마지막 계층을 편집하여 분류 신경망을 회귀 신경망으로 변환할 수 있습니다.
먼저, 소프트맥스 계층을 삭제합니다.
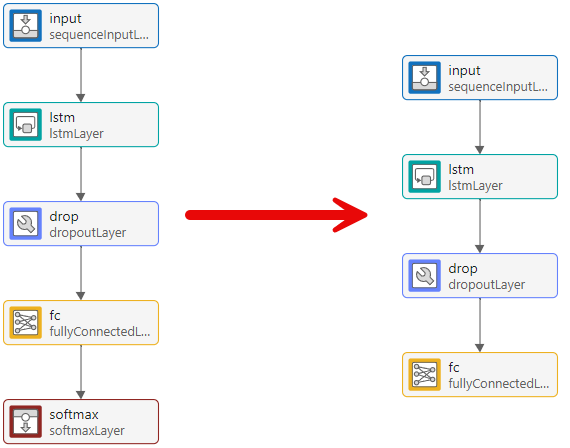
다음으로, 계층의 속성을 조정하여 파형 데이터 세트에 적합하도록 만듭니다. 목표가 시계열의 미래 데이터 점을 전망하는 것이므로 출력 크기는 입력 크기와 같아야 합니다. 이 예제에서 입력 데이터에 3개의 입력 채널이 있으므로 신경망 출력값에도 3개의 출력 채널이 있어야 합니다.
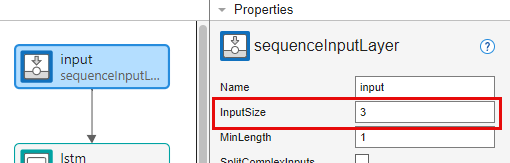
시퀀스 입력 계층 input을 선택하고 InputSize를 3으로 설정합니다.
완전 연결 계층 fc를 선택하고 OutputSize를 3으로 설정합니다.
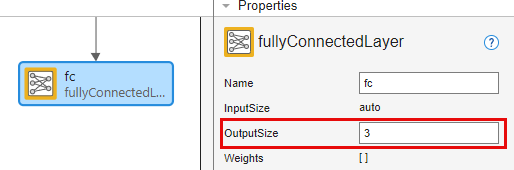
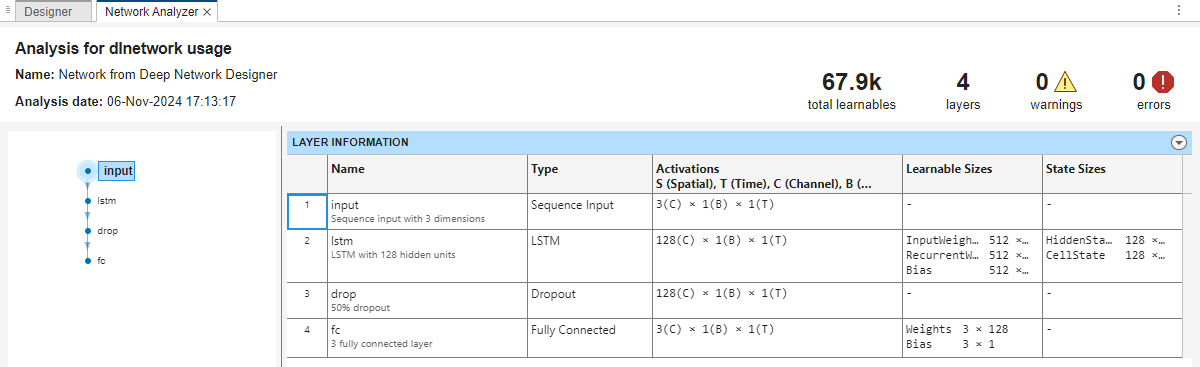
신경망이 훈련 준비가 되었는지 확인하려면 분석을 클릭하십시오. 딥러닝 신경망 분석기에 보고되는 오류나 경고가 없으므로 신경망이 훈련할 준비가 된 것입니다. 신경망을 내보내기 위해 내보내기를 클릭합니다. 앱은 신경망을 변수 net_1에 저장합니다.
훈련 옵션 지정하기
훈련 옵션을 지정합니다. 옵션 중에서 선택하려면 경험적 분석이 필요합니다. 실험을 실행하여 다양한 훈련 옵션 구성을 살펴보려면 실험 관리자 앱을 사용합니다. 순환 계층은 시퀀스 데이터를 한 번에 하나의 시간 스텝씩 처리하기 때문에 마지막 시간 스텝에서의 채우기가 계층 출력에 부정적인 영향을 줄 수 있습니다. SequencePaddingDirection 옵션을 "left"로 설정하여 시퀀스 데이터를 왼쪽에서 채우거나 자르십시오.
options = trainingOptions("adam", ... MaxEpochs=300, ... SequencePaddingDirection="left", ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false);
신경망 훈련시키기
trainnet 함수를 사용하여 신경망을 훈련시킵니다. 목표가 회귀이므로, 평균제곱오차(MSE) 손실을 사용합니다.
net = trainnet(XTrain,TTrain,net_1,"mse",options);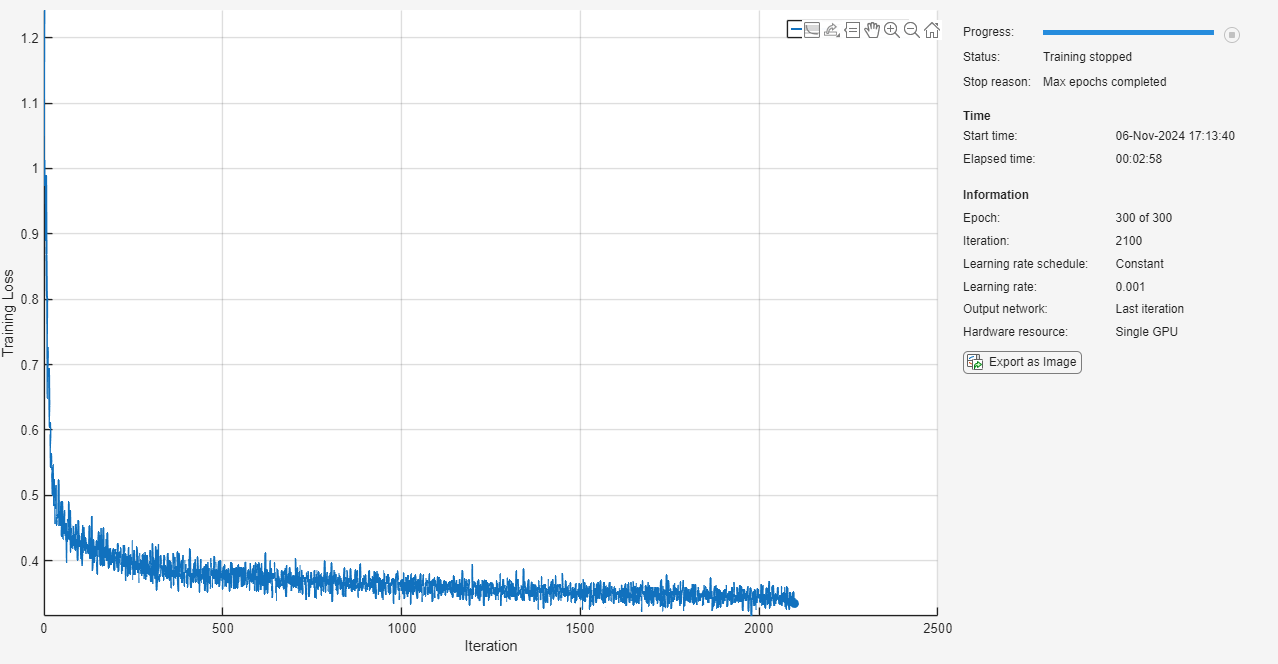
미래의 시간 스텝 전망하기
폐루프 전망은 이전 예측을 입력값으로 사용하여 시퀀스의 후속 시간 스텝을 예측합니다.
첫 번째 테스트 관측값을 선택합니다. resetState 함수로 상태를 재설정하여 RNN 상태를 초기화합니다. 그런 다음 predict 함수를 사용하여 초기 예측 Z를 수행합니다. 입력 데이터의 모든 시간 스텝을 사용하여 RNN 상태를 업데이트합니다.
X = XTest{1};
T = TTest{1};
net = resetState(net);
offset = size(X,1);
[Z,state] = predict(net,X(1:offset,:));
net.State = state;예측을 더 전망하려면 시간 스텝을 루프를 사용해 순회하고 predict 함수와 이전 시간 스텝에 대해 예측된 값을 사용하여 예측을 수행합니다. 각 예측 후에 RNN 상태를 업데이트합니다. 이전에 예측된 값을 RNN으로 반복적으로 전달하여 다음 200개의 시간 스텝을 전망합니다. RNN이 더 예측을 수행하기 위해 입력 데이터가 필요하지 않으므로 전망할 시간 스텝의 개수를 원하는 대로 지정할 수 있습니다. 초기 예측의 마지막 시간 스텝은 첫 번째로 전망된 시간 스텝입니다.
numPredictionTimeSteps = 200; Y = zeros(numPredictionTimeSteps,numChannels); Y(1,:) = Z(end,:); for t = 2:numPredictionTimeSteps [Y(t,:),state] = predict(net,Y(t-1,:)); net.State = state; end numTimeSteps = offset + numPredictionTimeSteps;
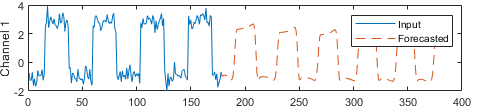
예측값과 입력값을 비교합니다.
figure l = tiledlayout(numChannels,1); title(l,"Time Series Forecasting") for i = 1:numChannels nexttile plot(X(1:offset,i)) hold on plot(offset+1:numTimeSteps,Y(:,i),"--") ylabel("Channel " + i) end xlabel("Time Step") legend(["Input" "Forecasted"])
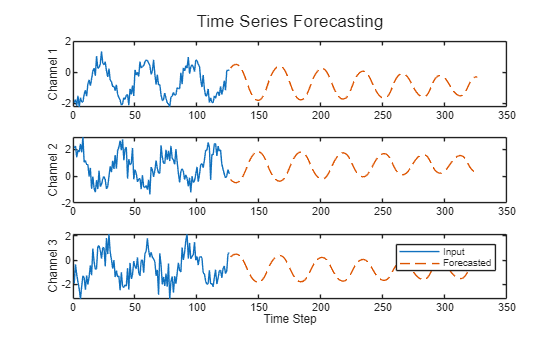
이러한 예측 방식을 폐루프 전망이라고 합니다. 시계열 전망 및 개루프 전망 수행에 대한 자세한 내용은 딥러닝을 사용한 시계열 전망 항목을 참조하십시오.
참고 항목
dlnetwork | trainingOptions | trainnet | scores2label | 심층 신경망 디자이너