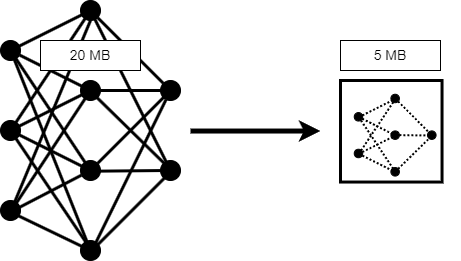
가지치기, 사영 및 양자화
심층 신경망 압축, 신경망 메모리 줄이기, 코드 생성을 위해 신경망 준비
Deep Learning Toolbox™를 Deep Learning Toolbox Model Compression Library 지원 패키지와 함께 사용하여 심층 신경망의 메모리 사용량과 계산 요구 사항을 줄입니다.
1차 테일러 근사를 사용하여 컨벌루션 계층에서 필터를 가지치기합니다.
계층 활성화 부분에 주성분 분석(PCA)을 수행하여 계층을 사영합니다.
계층의 가중치, 편향 및 활성화를 정수 데이터형으로 스케일링한 낮은 정밀도로 양자화합니다.
그런 다음 압축된 신경망에서 코드를 생성하여 원하는 하드웨어에 배포할 수 있습니다.
카테고리
- 신경망 압축 시작하기
Deep Learning Toolbox Model Compression Library의 기본 사항 알아보기
- 가지치기
1차 테일러 근사를 사용하여 신경망 필터 가지치기, 학습 가능한 파라미터 개수 줄이기
- 사영
주성분 분석(PCA)을 사용하여 신경망 계층 사영, 학습 가능한 파라미터 개수 줄이기
- 양자화
신경망 파라미터를 낮은 정밀도의 데이터형으로 양자화, 고정소수점 코드 생성을 위해 딥러닝 신경망 준비
- 신경망 압축 응용 사례
엔드 투 엔드 워크플로에서 딥러닝 모델 압축 살펴보기
추천 예제
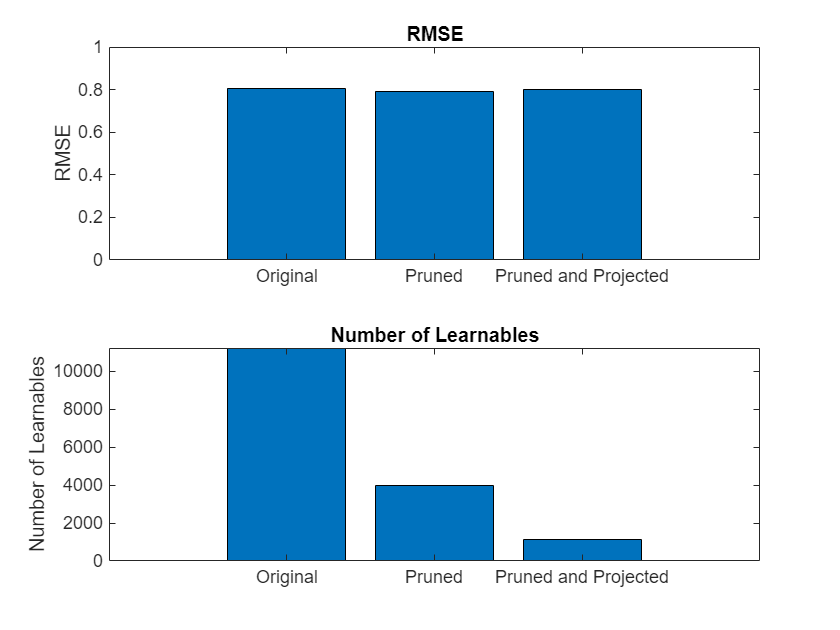
Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.
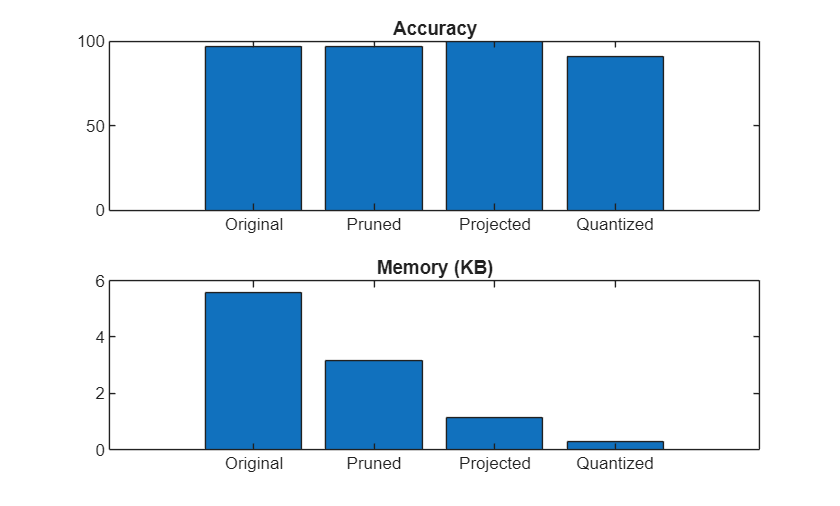
Compress Sequence Classification Network for Road Damage Detection
Compress network to meet memory requirement using pruning, projection, and quantization.
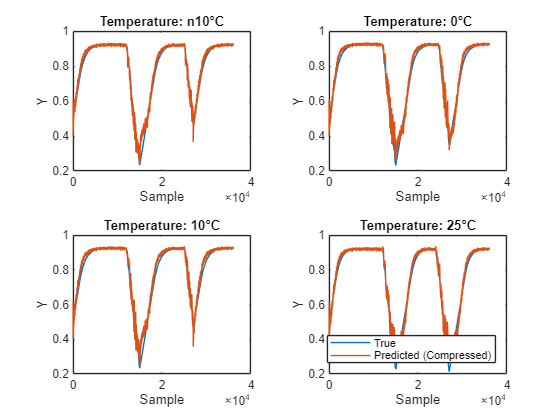
Compress Deep Learning Network for Battery State of Charge Estimation
Compress a neural network for predicting the state of charge of a battery using projection.