smooth
응답 변수 데이터 평활화
구문
설명
예제
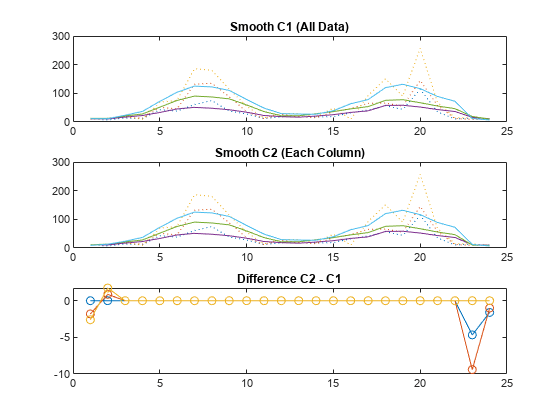
이동평균 필터를 사용하여 데이터를 선형 인덱스 기준으로 평활화해 보고, 이동평균 필터를 사용하여 각 열을 개별적으로 평활화해 봅니다. 결과를 플로팅하고 비교합니다.
count.dat의 데이터를 불러옵니다. 24×3 배열 count에는 하루 동안 세 곳의 교차로에서 집계된 시간당 교통량이 포함되어 있습니다.
load count.dat데이터가 연속 3일 동안 한 곳의 교차로에서 집계된 것이라고 가정하겠습니다. 모든 데이터를 한꺼번에 평활화하면 이 교차로를 통과하는 교통량의 전반적인 주기를 알아낼 수 있습니다. 5시간 범위를 갖는 이동평균 필터를 사용하여 모든 데이터를 선형 인덱스를 기준으로 동시에 평활화합니다.
c = smooth(count(:)); C1 = reshape(c,24,3);
그러나 실제로 데이터는 세 곳의 서로 다른 교차로에서 집계된 것입니다. 그러므로 열을 기준으로 평활화하면 하루 동안 각 교차로를 통과하는 교통량에 대한 보다 의미 있는 정보를 볼 수 있습니다. 데이터의 각 열을 개별적으로 평활화하려면 동일한 이동평균 필터를 사용하십시오.
C2 = zeros(24,3); for I = 1:3 C2(:,I) = smooth(count(:,I)); end
원래 데이터와 선형 인덱스를 기준으로 평활화한 데이터와 각 열을 개별적으로 평활화한 데이터를 플로팅합니다. 그런 다음 평활화된 데이터 세트 간의 차이를 플로팅합니다. 두 방법은 끝점 근방에서 서로 다른 결과를 보입니다.
subplot(3,1,1) plot(count,':'); hold on plot(C1,'-'); title('Smooth C1 (All Data)') subplot(3,1,2) plot(count,':'); hold on plot(C2,'-'); title('Smooth C2 (Each Column)') subplot(3,1,3) plot(C2 - C1,'o-') title('Difference C2 - C1')
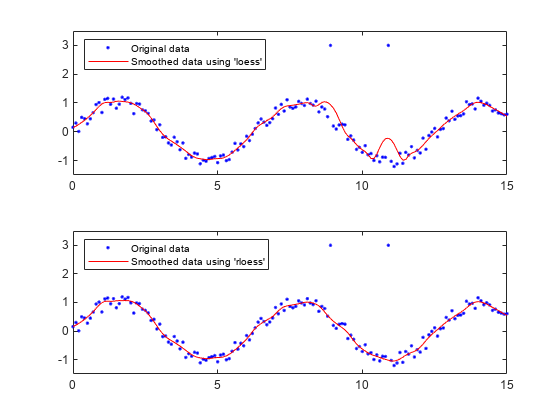
loess 방법과 rloess 방법을 사용하여 데이터를 평활화하고 결과를 플로팅하여 비교합니다. 그런 다음 어느 방법이 이상값에 덜 민감한지 확인합니다.
2개의 이상값을 포함하는 잡음이 있는 데이터를 만듭니다.
x = (0:0.1:15)'; y = sin(x) + 0.5*(rand(size(x))-0.5); y([90,110]) = 3;
loess 방법과 rloess 방법을 사용하여 데이터를 평활화합니다. 데이터 점의 총 개수의 10%를 범위로 사용합니다.
yy1 = smooth(x,y,0.1,'loess'); yy2 = smooth(x,y,0.1,'rloess');
원래 데이터와 평활화된 데이터를 플로팅합니다. 로버스트 방법 rloess에서 이상값이 더 적은 영향을 줍니다.
subplot(2,1,1) plot(x,y,'b.',x,yy1,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''loess''',... 'Location','NW') subplot(2,1,2) plot(x,y,'b.',x,yy2,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''rloess''',... 'Location','NW')
입력 인수
출력 인수
팁
평활화 스플라인을 사용하여 데이터에 대한 매끄러운 피팅을 생성할 수 있습니다. 자세한 내용은
fit을 참조하십시오.
대체 기능
MATLAB® smoothdata 함수를 사용하여 데이터를 평활화할 수도 있습니다. GPU 배열 지원을 제외하고, smoothdata는 smooth 함수의 모든 기능을 포함하고 있으며 몇 가지 이점이 있습니다. smooth와는 달리, smoothdata 함수는 다음을 지원합니다.
행렬, 테이블, 타임테이블
이동 중앙값 방법 및 가우스 방법
NaN값이 처리되는 방법을 지정하는 옵션원래 행렬에 평활화된 데이터를 대입하거나 평활화된 데이터를 원래 행렬에 추가하는 옵션
tall형 배열, C/C++ 코드 생성, 스레드 기반 환경
확장 기능
버전 내역
R2006a 이전에 개발됨