audioDelta
Compute delta features
Syntax
Description
delta = audioDelta(x,deltaWindowLength)
delta = audioDelta(x,deltaWindowLength,initialCondition)
[
also returns the final condition of the filter.delta,finalCondition] = audioDelta(x,___)
Examples
Read in an audio file.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav");Create an audioFeatureExtractor object to extract some spectral features over time from the audio. Call extract to extract the audio features.
afe = audioFeatureExtractor(SampleRate=fs, ... spectralCentroid=true, ... spectralSlope=true); audioFeatures = extract(afe,audioIn);
Call audioDelta to approximate the first derivative of the spectral features over time.
deltaAudioFeatures = audioDelta(audioFeatures);
Plot the spectral features and the delta of the spectral features.
map = info(afe); tiledlayout(2,1) nexttile plot(audioFeatures(:,map.spectralCentroid)) ylabel("Spectral Centroid") nexttile plot(deltaAudioFeatures(:,map.spectralCentroid)) ylabel("Delta Spectral Centroid") xlabel("Frame")
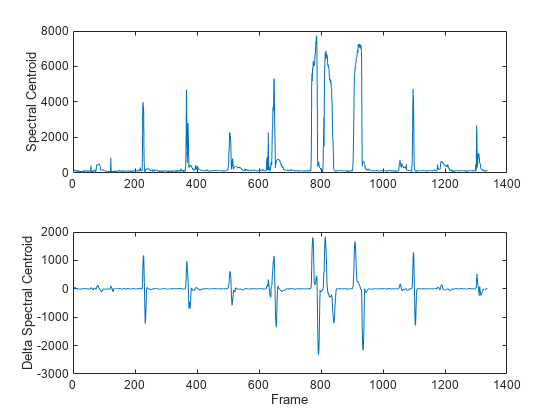
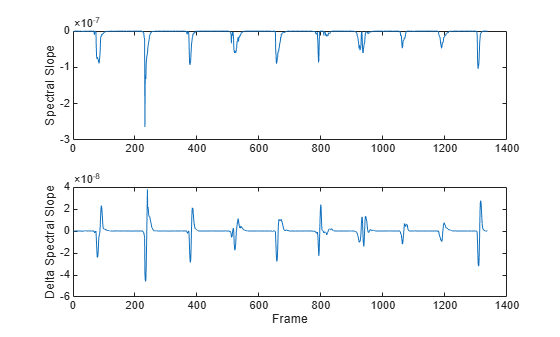
tiledlayout(2,1) nexttile plot(audioFeatures(:,map.spectralSlope)) ylabel("Spectral Slope") nexttile plot(deltaAudioFeatures(:,map.spectralSlope)) ylabel("Delta Spectral Slope") xlabel("Frame")
The delta and delta-delta of mel frequency cepstral coefficients (MFCC) are often used with the MFCC for machine learning and deep learning applications.
Read in an audio file.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav");Use the designAuditoryFilterBank function to design a one-sided frequency-domain mel filter bank.
analysisWindowLength = round(fs*0.03); fb = designAuditoryFilterBank(fs,FFTLength=analysisWindowLength);
Use the stft function to convert the audio signal to a complex, one-sided frequency-domain representation. Convert the STFT to magnitude and apply the frequency-domain filtering.
w = hann(analysisWindowLength,"periodic"); [S,~,t] = stft(audioIn,fs,Window=w,FrequencyRange="onesided"); auditorySTFT = fb*abs(S);
Call the cepstralCoefficients function to extract the MFCC.
melcc = cepstralCoefficients(auditorySTFT);
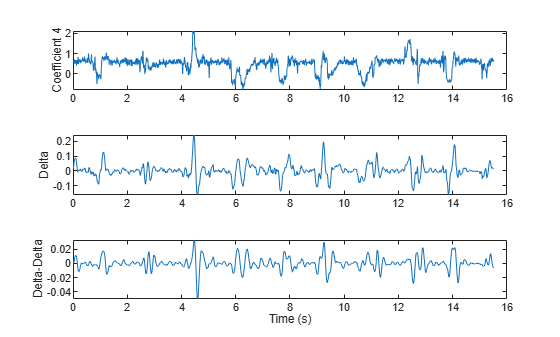
Call the audioDelta function to compute the delta MFCC. Call audioDelta again to compute the delta-delta MFCC. Plot the results.
deltaWindowLength =21; melccDelta = audioDelta(melcc,deltaWindowLength); melccDeltaDelta = audioDelta(melccDelta,deltaWindowLength); coefficientToDisplay =
4; tiledlayout(3,1) nexttile plot(t,melcc(:,coefficientToDisplay+1)) ylabel("Coefficient "+string(coefficientToDisplay)) nexttile plot(t,melccDelta(:,coefficientToDisplay+1)) ylabel("Delta") nexttile plot(t,melccDeltaDelta(:,coefficientToDisplay+1)) xlabel("Time (s)") ylabel("Delta-Delta")
You can calculate the delta of streaming signals by passing state in and out of the audioDelta function.
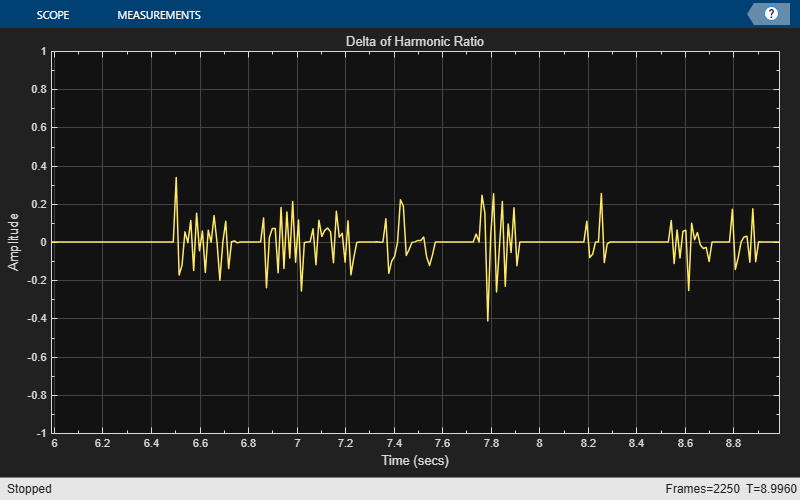
Create a dsp.AudioFileReader object to read an audio file frame-by-frame. Create an audioDeviceWriter object to write audio to your speaker. Create a timescope object to visualize the change in harmonic ratio over time.
fileReader = dsp.AudioFileReader("FemaleSpeech-16-8-mono-3secs.wav", ... SamplesPerFrame=32, ... PlayCount=3); deviceWriter = audioDeviceWriter(SampleRate=fileReader.SampleRate); scope = timescope(SampleRate=fileReader.SampleRate/fileReader.SamplesPerFrame, ... TimeSpanSource="Property", ... TimeSpan=3, ... YLimits=[-1,1], ... Title="Delta of Harmonic Ratio");
While the audio file has unread frames of data:
Read a frame from the audio file
Calculate the harmonic ratio of that frame
Calculate the delta of the harmonic ratio
Write the audio frame to your speaker
Write the change in the harmonic ratio to your scope
On each call to audioDelta, overwrite the previous state. Initialize the state using an empty array.
z = []; w = hann(fileReader.SamplesPerFrame,"periodic"); while ~isDone(fileReader) audioIn = fileReader(); hr = harmonicRatio(audioIn,fileReader.SampleRate, ... Window=w,OverlapLength=0); [deltaHR, z] = audioDelta(hr,5,z); deviceWriter(audioIn); scope(deltaHR) end release(scope)
This example shows how to align audioDelta with the definition of delta found in [1].
Read in the first 100 samples of an audio file.
[x,fs] = audioread("Counting-16-44p1-mono-15secs.wav",[1 100]);In [1], delta is defined as:
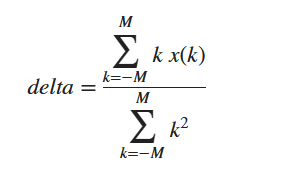
Specify a delta window length of 5. Pad the front and back of the data with floor(5/2) copies of the first and last sample points respectively. Then use the definition to compute the delta. To apply the definition, you loop over the padded data.
winLength = 5; M = floor(winLength/2); frontPad = repmat(x(1),M,1); backPad = repmat(x(end),M,1); xPadded = [frontPad ; x ; backPad]; delta_book = nan(size(x)); % Loop over all frames k = -M:M; for n = 1:length(x) delta_book(n) = sum(k(:).*xPadded(n:(n+2*M)))/sum(k.^2); end
Plot the result.
plot(delta_book,"-o") legend("Book Definition")
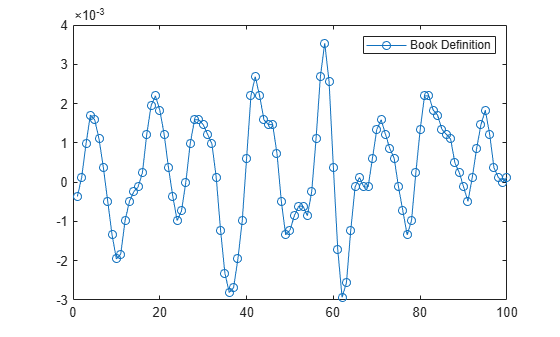
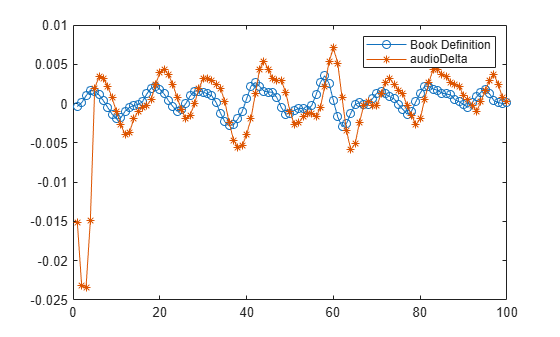
Use audioDelta to compute the delta. Compare with the previous result.
delta_audioDelta = audioDelta(x,winLength); plot(delta_book,"-o") hold on plot(delta_audioDelta,"-*") hold off legend("Book Definition","audioDelta")
To support causal streaming, audioDelta introduces a reporting delay of the least-squares approximation equal to floor(W/2), where W is the delta window length. Additionally, there is a scale factor difference between the book definition and the function. Make the following adjustments to bring audioDelta and the book definition into alignment.
delta_audioDeltaAdjusted = audioDelta(xPadded(:),winLength); delta_audioDeltaAdjusted(1:winLength-1) = []; scaleFix = 0.5; % This is independent of the window length. delta_audioDeltaAdjusted = delta_audioDeltaAdjusted*scaleFix; plot(delta_book,"-o") hold on plot(delta_audioDeltaAdjusted,"-*") hold off legend("Book Definition","audioDelta adjusted")
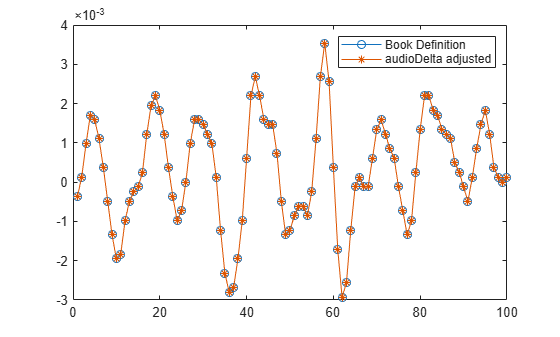
rms(delta_book-delta_audioDeltaAdjusted)
ans = 3.4091e-19
Input Arguments
Output Arguments
More About
Algorithms
To support causal streaming, audioDelta introduces a reporting delay
of the least-squares approximation equal to
floor(. To learn how to align
the function with the classic definition found in [1], see Compare audioDelta with Book Definition.deltaWindowLength/2)
References
[1] Rabiner, Lawrence R., and Ronald W. Schafer. Theory and Applications of Digital Speech Processing. Upper Saddle River, NJ: Pearson, 2010.
Extended Capabilities
Version History
Introduced in R2020b