이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
AI를 사용한 오디오 처리
Audio Toolbox™는 화자 식별, 음성 명령 인식, 음성 분리, 음향 장면 인식, 잡음 제거 등을 포함해 오디오, 음성, 음향 응용 분야에서의 다양한 머신러닝 및 딥러닝 솔루션 개발에 필요한 기능을 제공합니다.
audioDatastore를 사용하여 대규모 오디오 데이터 세트를 수집하고 파일을 병렬로 처리할 수 있습니다.신호 레이블 지정기를 사용하여 오디오 녹음에 수동 또는 자동으로 주석을 달아 오디오 데이터 세트를 만들 수 있습니다.
audioDataAugmenter를 사용하여, 오디오 데이터 세트의 증강 및 합성을 위해 내장 신호 처리 방법이나 사용자 지정 신호 처리 방법으로 구성된 무작위 파이프라인을 만들 수 있습니다.audioFeatureExtractor를 사용하여 중간 계산을 공유하면서 다양한 기능 조합을 추출할 수 있습니다.
Audio Toolbox는 또한 텍스트-음성 변환 및 음성-텍스트 변환을 위한 타사 API에 대한 액세스를 제공하며, 사전 훈련된 모델을 포함하므로 사용자가 전이 학습을 수행하고, 사운드를 분류하고, 특징 임베딩을 추출할 수 있습니다. 사전 훈련된 신경망을 사용하려면 Deep Learning Toolbox™가 필요합니다.
카테고리
- 응용 사례
오디오 응용 분야에 AI 워크플로 적용
- 데이터셋 관리 및 레이블 지정
대규모 데이터 세트 수집, 생성 및 레이블 지정
- 특징 추출
멜 스펙트로그램, MFCC, 피치, 스펙트럼 설명자
- 데이터 증강
증강 파이프라인, 피치 및 시간 이동, 시간 연장, 볼륨 및 잡음 제어
- 분할
음성과 기타 사운드 감지 및 분리
- 사전 훈련된 모델
전이 학습, 사운드 분류, 특징 임베딩, 사전 훈련된 오디오 딥러닝 신경망
- 음성 전사(Speech Transcription) 및 합성
텍스트-음성 변환 및 음성-텍스트 변환에 사전 훈련된 모델 또는 타사 API 사용
- 코드 생성 및 GPU 지원
이식 가능한 C/C++/MEX 함수의 생성, GPU를 사용한 배포 또는 처리 속도 향상
추천 예제
AI for Speech Command Recognition
Build, train, compress, and deploy a deep learning model for speech command recognition.

Speech Command Recognition Code Generation on Raspberry Pi
Generate code and deploy feature extraction and speech command recognition network on Raspberry Pi hardware.

Speech Command Recognition Code Generation on Desktop
Deploy feature extraction and a convolutional neural network (CNN) for speech command recognition. In this example, the generated code is a MATLAB executable (MEX) function, which is called by a MATLAB script that displays the predicted speech command along with the time domain signal and auditory spectrogram. For details about audio preprocessing and network training, see 음성 명령 인식을 위한 딥러닝 신경망 훈련시키기.

Keyword Spotting in Noise Using MFCC and LSTM Networks
Identify a keyword in noisy speech using a deep learning network. In particular, the example uses a Bidirectional Long Short-Term Memory (BiLSTM) network and mel frequency cepstral coefficients (MFCC).

딥러닝 신경망을 사용하여 음성 잡음 제거하기
이 예제에서는 딥러닝 신경망을 사용하여 음성 신호의 잡음을 제거하는 방법을 다룹니다. 이 예제에서는 동일한 작업에 적용된 두 가지 유형의 신경망, 즉 완전 연결 신경망과 컨벌루션 신경망을 비교합니다.
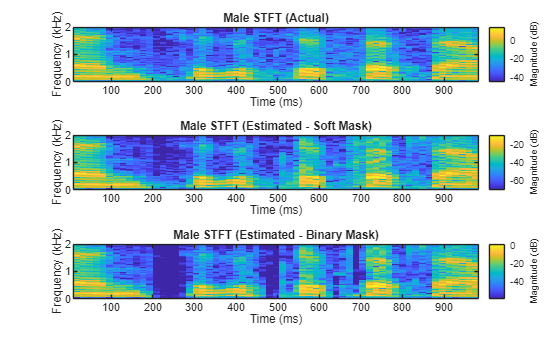
Cocktail Party Source Separation Using Deep Learning Networks
Isolate a speech signal using a deep learning network.
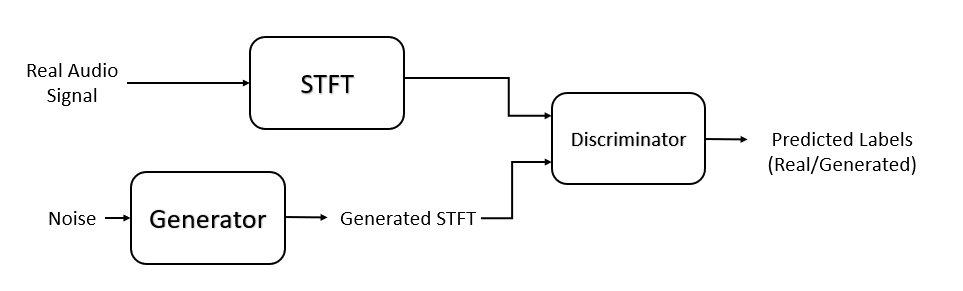
Train Generative Adversarial Network (GAN) for Sound Synthesis
Train and use a generative adversarial network (GAN) to generate sounds.

Speaker Identification Using Pitch and MFCC
Use machine learning to identify people based on features extracted from recorded speech.
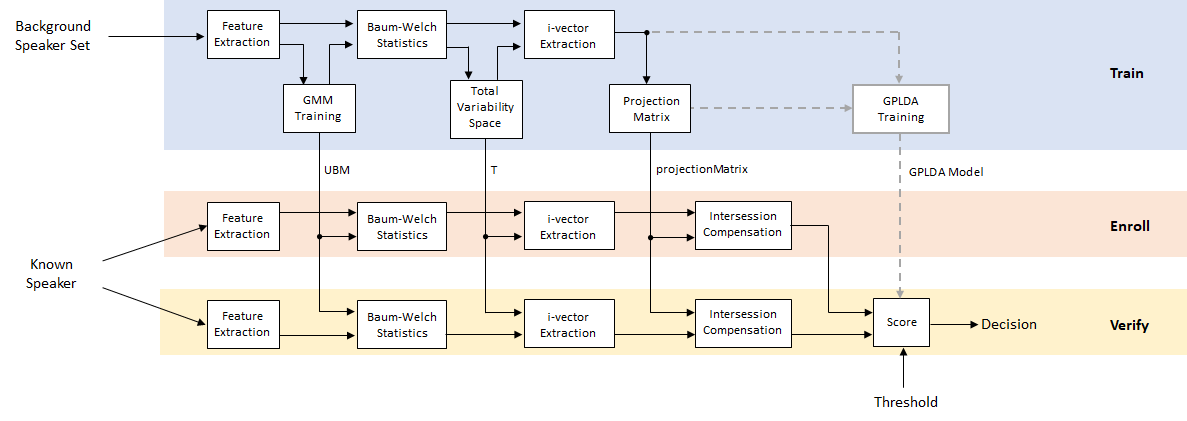
Speaker Verification Using i-vectors
Speaker verification, or authentication, is the task of confirming that the identity of a speaker is who they purport to be. Speaker verification has been an active research area for many years. An early performance breakthrough was to use a Gaussian mixture model and universal background model (GMM-UBM) [1] on acoustic features (usually mfcc). For an example, see Speaker Verification Using Gaussian Mixture Model. One of the main difficulties of GMM-UBM systems involves intersession variability. Joint factor analysis (JFA) was proposed to compensate for this variability by separately modeling inter-speaker variability and channel or session variability [2] [3]. However, [4] discovered that channel factors in the JFA also contained information about the speakers, and proposed combining the channel and speaker spaces into a total variability space. Intersession variability was then compensated for by using backend procedures, such as linear discriminant analysis (LDA) and within-class covariance normalization (WCCN), followed by a scoring, such as the cosine similarity score. [5] proposed replacing the cosine similarity scoring with a probabilistic LDA (PLDA) model. [11] and [12] proposed a method to Gaussianize the i-vectors and therefore make Gaussian assumptions in the PLDA, referred to as G-PLDA or simplified PLDA. While i-vectors were originally proposed for speaker verification, they have been applied to many problems, like language recognition, speaker diarization, emotion recognition, age estimation, and anti-spoofing [10]. Recently, deep learning techniques have been proposed to replace i-vectors with d-vectors or x-vectors [8] [6].

Train End-to-End Speaker Separation Model
Use an end-to-end deep learning network for speaker-independent speech separation.