비전-언어 모델
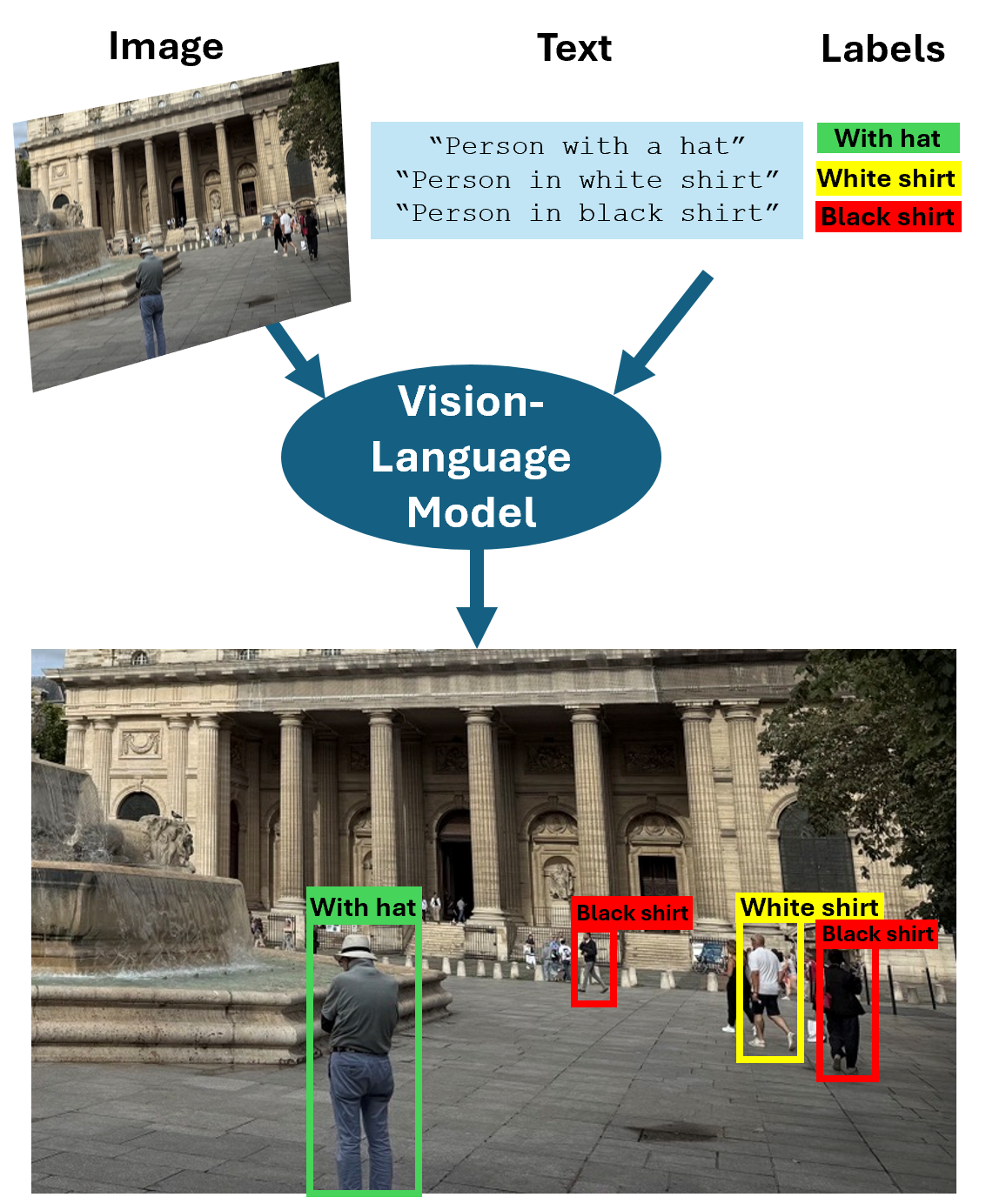
비전-언어 모델(VLM)은 영상과 텍스트를 입력으로 받아 텍스트를 출력으로 생성하거나 해당 주석과 함께 경계 상자를 반환할 수 있는 다중모달 모델로, 객체 검출 및 비주얼 그라운딩(visual grounding)과 같은 작업을 가능하게 합니다. 이러한 모델은 영상이나 비디오의 시각적 콘텐츠를 분석하고, 함께 제공된 텍스트를 처리하며, 시각 데이터와 텍스트 데이터 간의 상관관계를 식별할 수 있습니다. 이 모델은 언어적 컨텍스트 내에서 시각 정보를 해석하는 다양한 작업을 수행할 수 있도록 지원하며, 이는 실제 의미를 이해하는 것이 아니라 예측 알고리즘을 활용하여 이루어집니다. Computer Vision Toolbox™는 CLIP, Grounding DINO, Moondream 등 여러 사전 훈련된 VLM을 제공하며, 다음과 같은 응용 분야에서 사용할 수 있습니다.
영상 캡션 생성 — 영상에 대한 설명 텍스트를 생성합니다.
영상 검색 — 미리 정의된 세트에서 텍스트 설명과 가장 일치하는 영상을 찾습니다.
객체 검출 — 텍스트 기반 쿼리에 따라 영상에서 객체를 검출합니다.
영상 분류 — 텍스트 범주에 따라 영상을 분류합니다.
또한, 영상 레이블 지정기 앱과 비디오 레이블 지정기 앱에서 설명 텍스트 프롬프트를 통해 ground truth를 자동으로 레이블 지정하는 데에도 VLM을 사용할 수 있습니다. 시작하려면 Get Started with Vision-Language Models 항목을 참조하십시오.
앱
| 영상 레이블 지정기 | 컴퓨터 비전 응용 분야에서 영상에 레이블 지정 |
| 비디오 레이블 지정기 | Label video for computer vision applications |
함수
도움말 항목
시작하기
- Get Started with Vision-Language Models
Use vision-language models for multimodal tasks such as image captioning, zero-shot classification, and image search.
추천 예제

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
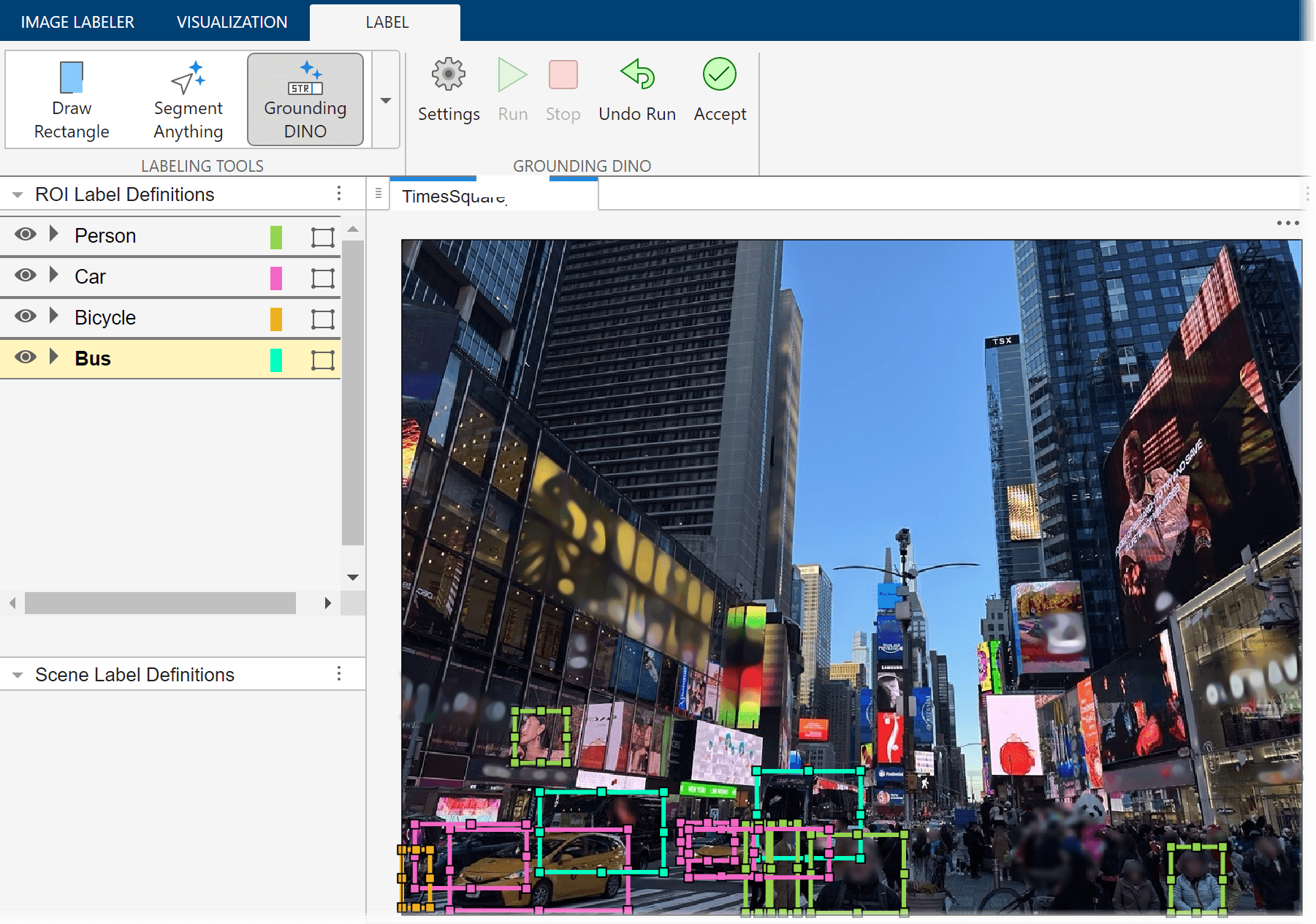
Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).
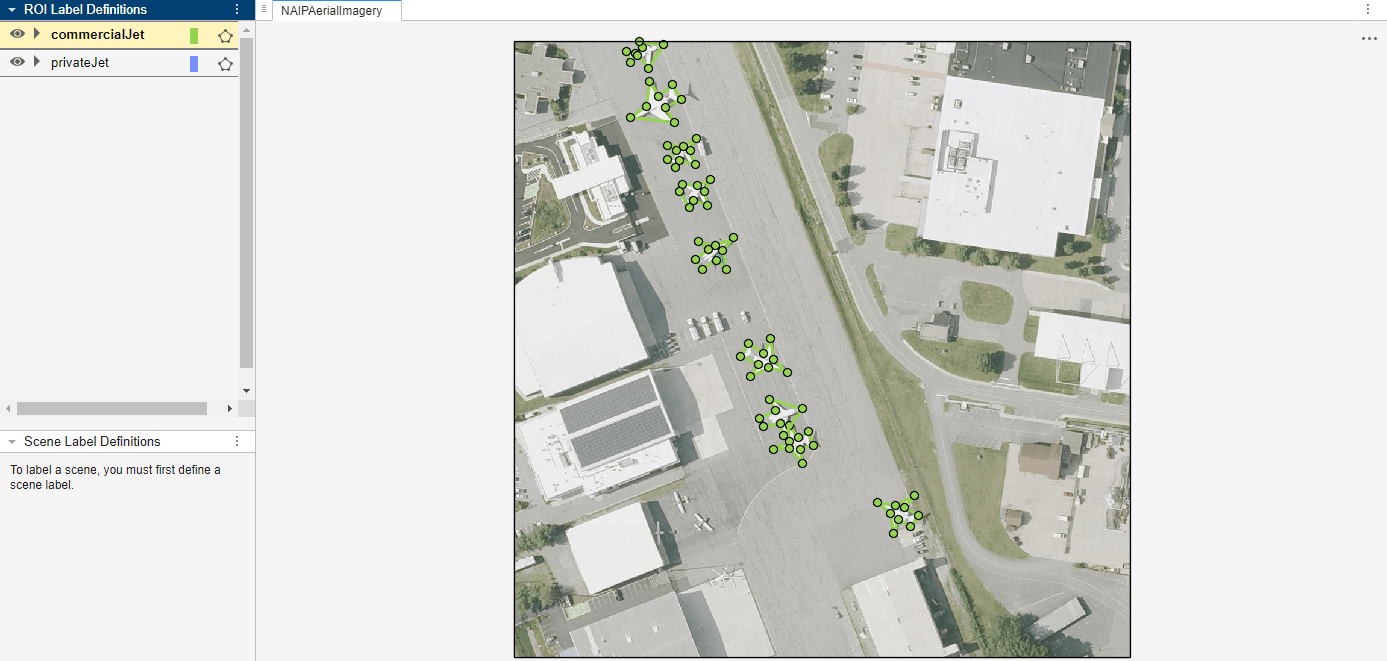
Automate Ground Truth Polygon Labeling Using Grounded SAM Model
Combine Grounding DINO and the Segment Anything Model 2 (SAM 2) to automatically produce polygon labels using the Video Labeler app.
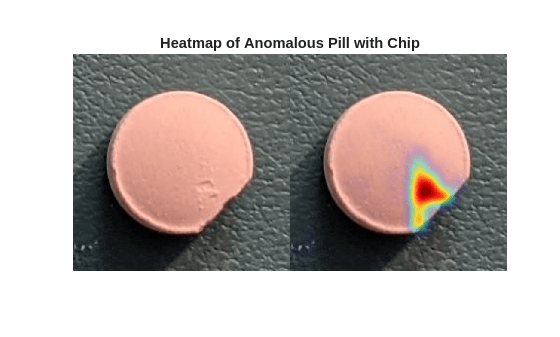
Detect Industrial Defects Using Zero-Shot AnomalyCLIP
Detect and localize industrial production defects in pill images using an AnomalyCLIP anomaly detection network.