토픽 모델링 시작하기
이 예제에서는 토픽 모델을 텍스트 데이터에 피팅하고 토픽을 시각화하는 방법을 보여줍니다.
LDA(잠재 디리클레 할당) 모델은 문서 모음에서 기저 토픽을 발견하는 토픽 모델입니다. 단어의 분포로 특징지어지는 토픽은 주로 함께 나타나는 단어들의 그룹을 뜻합니다. LDA는 비지도 토픽 모델이기 때문에 레이블이 지정된 데이터를 필요로 하지 않습니다.
텍스트 데이터 불러오기 및 추출하기
예제 데이터를 불러옵니다. factoryReports.csv 파일에는 각 이벤트에 대한 텍스트 설명과 범주 레이블이 포함된 공장 보고서가 들어 있습니다.
readtable 함수를 사용하여 데이터를 가져온 후 Description 열에서 텍스트 데이터를 추출합니다.
filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description;
분석할 텍스트 데이터 준비하기
텍스트 데이터를 토큰화하고 전처리한 후 bag-of-words 모델을 만듭니다.
텍스트를 토큰화합니다.
documents = tokenizedDocument(textData);
모델 피팅을 향상시키기 위해 문서에서 문장 부호와 불용어("and", "of", "the" 같은 단어)를 제거합니다.
documents = removeStopWords(documents); documents = erasePunctuation(documents);
bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents);
LDA 모델 피팅하기
fitlda 함수를 사용하여 7개 토픽으로 LDA 모델을 피팅합니다. 세부 정보가 출력되지 않도록 'Verbose' 옵션을 0으로 설정합니다.
numTopics = 7;
mdl = fitlda(bag,numTopics,'Verbose',0);토픽 시각화하기
워드 클라우드를 사용하여 처음 4개 토픽을 시각화합니다.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic " + topicIdx) end
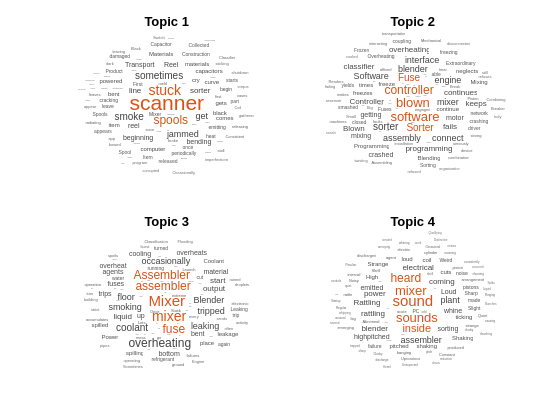
텍스트 분석의 다음 단계로, 다른 전처리 단계를 사용하여 모델 피팅을 향상시키고 토픽 혼합을 시각화해 볼 수 있습니다. 예제는 토픽 모델을 사용하여 텍스트 데이터 분석하기 항목을 참조하십시오.
참고 항목
removeStopWords | tokenizedDocument | erasePunctuation | bagOfWords | fitlda | wordcloud