단순 전처리 함수 만들기
이 예제에서는 텍스트 데이터 전처리 라이브 편집기 작업을 사용하여 분석할 텍스트 데이터를 정리하고 전처리하는 함수를 만드는 방법을 보여줍니다.
텍스트 데이터가 클수록 통계 분석에 부정적 영향을 주는 잡음 데이터가 많이 들어 있을 수 있습니다. 예를 들어 텍스트 데이터에 다음이 포함되어 있을 수 있습니다.
대/소문자가 변형된 단어. 예를 들면 "new"와 "New"
어형이 변형된 단어. 예를 들면 "walk"와 "walking"
잡음을 추가하는 단어. 예를 들면 "the"와 "of" 같은 불용어(stop word)
문장 부호 및 특수 문자
HTML 및 XML 태그
다음 워드 클라우드는 공장 보고서의 원시 텍스트 데이터에 단어 빈도 분석을 적용한 버전과 동일한 텍스트 데이터를 전처리한 버전을 나타낸 것입니다.

대부분의 워크플로에서 서로 다른 텍스트 데이터 모음을 동일한 방식으로 용이하게 마련하기 위해 전처리 함수를 필요로 합니다. 예를 들어 모델을 훈련시킬 때 동일한 함수를 사용하여 동일한 단계를 통해 훈련 데이터와 새 데이터를 전처리할 수 있습니다.
텍스트 데이터 전처리 라이브 편집기 작업을 사용하여 대화형 방식으로 텍스트 데이터를 전처리하고 결과를 시각화할 수 있습니다. 이 예제에서는 텍스트 데이터 전처리 라이브 편집기 작업을 사용하여, 텍스트 데이터를 전처리하고 재사용할 수 있는 함수를 만드는 코드를 생성합니다. 라이브 편집기 작업에 대한 자세한 내용은 라이브 스크립트에 대화형 방식 작업 추가하기 항목을 참조하십시오.
먼저 공장 보고서 데이터를 불러옵니다. 이 데이터는 공장 고장 이벤트에 대한, 텍스트로 된 설명을 포함합니다.
tbl = readtable("factoryReports.csv")
텍스트 데이터 전처리 라이브 편집기 작업을 엽니다. 작업을 열려면 우선 작업 이름을 입력하고 제안된 명령 완성에서 텍스트 데이터 전처리를 선택합니다. 또는 라이브 편집기 탭에서 작업 > 텍스트 데이터 전처리를 선택합니다.

다음 옵션을 사용하여 텍스트를 전처리합니다.
입력 데이터로
tbl을 선택하고 테이블 변수Description을 선택합니다.자동 언어 검출을 사용하여 텍스트를 토큰화합니다.
표제어 추출을 개선하기 위해 토큰 세부 정보에 품사 태그를 추가합니다.
표제어 추출을 사용하여 단어를 정규화합니다.
3자 미만이거나 14자가 넘는 단어를 제거합니다.
불용어를 제거합니다.
문장 부호를 지웁니다.
전처리된 텍스트를 워드 클라우드로 표시합니다.
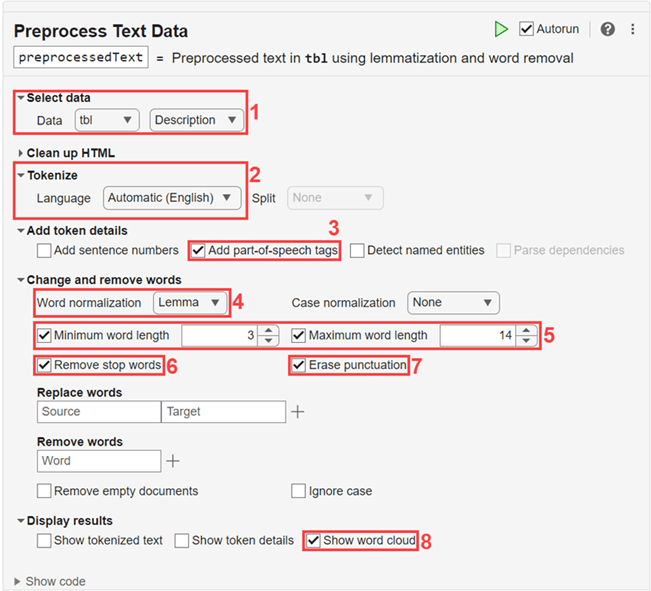

텍스트 데이터 전처리 라이브 편집기 작업은 라이브 스크립트에 코드를 생성합니다. 생성 코드는 사용자가 선택한 옵션을 반영하며 디스플레이를 생성하기 위한 코드를 포함합니다. 생성 코드를 보려면 작업 파라미터 영역의 맨 아래 있는 코드 표시를 클릭하십시오. 작업이 확장되면서 생성 코드가 표시됩니다.
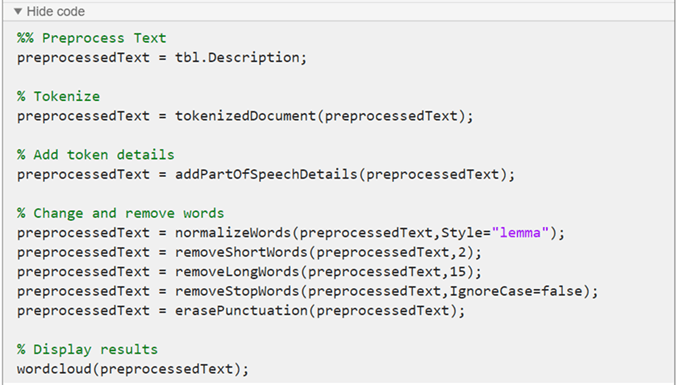
생성 코드는 기본적으로 preprocessedText를 MATLAB® 작업 공간에 반환되는 출력 변수의 이름으로 사용합니다. 다른 출력 변수 이름을 지정하기 위해 작업 맨 위의 요약 행에 새 이름을 입력합니다.

코드에서 동일한 단계를 재사용하기 위해 텍스트 데이터를 입력으로 받아 전처리된 텍스트 데이터를 출력하는 함수를 만듭니다. 이 함수는 스크립트의 끝에 포함시키거나 별도의 파일로 포함시킬 수 있습니다. 이 예제의 마지막에 나오는 preprocessTextData 함수는 텍스트 데이터 전처리 라이브 편집기 작업에서 생성된 코드를 사용합니다.
이 함수를 사용하려면 테이블을 preprocessTextData 함수의 입력으로 지정하십시오.
documents = preprocessTextData(tbl);
전처리 함수
preprocessTextData 함수는 텍스트 데이터 전처리 라이브 편집기 작업에서 생성된 코드를 사용합니다. 이 함수는 테이블 tbl을 입력으로 받고 전처리된 텍스트 preprocessedText를 반환합니다. 함수는 다음 단계를 수행합니다.
입력 테이블의
Description변수에서 텍스트 데이터를 추출합니다.tokenizedDocument를 사용하여 텍스트를 토큰화합니다.addPartOfSpeechDetails를 사용하여 품사 세부 정보를 추가합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.removeStopWords를 사용하여 불용어(예: "and", "of", "the")를 제거합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.
function preprocessedText = preprocessTextData(tbl) %% Preprocess Text preprocessedText = tbl.Description; % Tokenize preprocessedText = tokenizedDocument(preprocessedText); % Add token details preprocessedText = addPartOfSpeechDetails(preprocessedText); % Change and remove words preprocessedText = normalizeWords(preprocessedText,Style="lemma"); preprocessedText = removeShortWords(preprocessedText,2); preprocessedText = removeLongWords(preprocessedText,15); preprocessedText = removeStopWords(preprocessedText,IgnoreCase=false); preprocessedText = erasePunctuation(preprocessedText); end
자세한 워크플로를 보여주는 예제는 Preprocess Text Data in Live Editor 항목을 참조하십시오. 텍스트 분석의 다음 단계로, 분류 모델을 만들어 보거나 토픽 모델을 사용하여 데이터를 분석할 수 있습니다. 예제는 분류를 위한 간단한 텍스트 모델 만들기 및 토픽 모델을 사용하여 텍스트 데이터 분석하기 항목을 참조하십시오.
참고 항목
텍스트 데이터 전처리하기 | tokenizedDocument | erasePunctuation | removeStopWords | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails