이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
다변량 데이터 시각화하기
이 예제에서는 통계적 플롯을 사용하여 다변량 데이터를 시각화하는 방법을 보여줍니다. 많은 통계량 분석이 두 개의 변수, 즉 한 개의 예측 변수와 한 개의 응답 변수를 사용합니다. 두 개의 변수는 2차원 산점도 플롯, 이변량 히스토그램, 상자 플롯과 같은 플롯을 사용하여 쉽게 시각화할 수 있습니다. 또한 3차원 산점도 플롯을 사용하거나 색으로 표시되는 세 번째 변수가 있는 2차원 산점도 플롯을 사용하여 삼변량 데이터를 시각화할 수 있습니다. 그러나 많은 데이터 세트가 다수의 변수를 포함하고 있어서 바로 시각화하기가 더 어렵습니다. 이 예제에서는 Statistics and Machine Learning Toolbox™의 함수를 사용하여 고차원 데이터를 시각화하는 방법을 살펴봅니다.
데이터 불러오기
1970년대와 1980년대에 제조된 400대 자동차에 대한 측정값을 포함하는 carbig 데이터 세트를 불러옵니다. 다변량 시각화를 사용하여 연료 효율(단위: 갤런당 마일 주행 거리(MPG)), 가속도(0에서 60mph까지 가속하는 데 걸리는 시간, 단위: 초), 엔진 배기량(단위: 입방 인치), 중량, 마력에 대한 값을 살펴봅니다.
load carbig X = [MPG,Acceleration,Displacement,Weight,Horsepower]; varNames = ["MPG","Acceleration","Displacement","Weight","Horsepower"];
산점도 플롯 행렬
고차원 데이터를 보는 한 가지 방법은 저차원 부분공간에 데이터의 슬라이스를 표시하는 것입니다. gplotmatrix 함수를 사용하면 X의 5개 변수에 대한 모든 이변량 산점도 플롯으로 구성된 배열을 각 변수에 대한 일변량 히스토그램과 함께 표시할 수 있습니다. 실린더 개수를 기준으로 관측값을 그룹화합니다.
gplotmatrix(X,[],Cylinders,[],[],8,[],[],varNames)
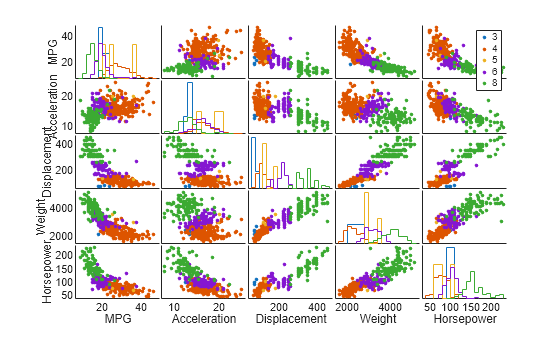
각 산점도 플롯의 점은 기통 개수에 따라 색으로 구분됩니다. 즉, 4기통은 빨간색, 6기통은 자주색, 8기통은 녹색으로 표시됩니다. 로터리 엔진이 장착된 자동차에는 3기통이 탑재되어 있고 일부 자동차에는 5기통이 탑재되어 있습니다. 플롯으로 구성된 이러한 배열은 변수 쌍 간의 관계에 대한 패턴을 찾는 데 도움이 됩니다. 더 높은 차원에 중요한 패턴이 있을 수도 있는데, 이 플롯에서는 그러한 패턴을 알아보기가 쉽지 않습니다.
평행좌표 플롯
산점도 플롯 행렬은 이변량 관계만 표시하는 반면, 일부 플롯은 모든 변수를 함께 표시하므로 이를 통해 변수 사이에 더 높은 차원 관계를 살펴볼 수 있습니다. 가장 간단한 다변량 플롯은 평행좌표 플롯입니다. 이 플롯의 좌표축은 일반적인 카테시안 그래프에서처럼 직교가 아닌 가로로 놓여 있습니다. 각각의 관측값은 플롯에서 일련의 연결된 선분으로 표현됩니다.
4기통, 6기통 또는 8기통이 탑재된 X의 모든 자동차에 대한 플롯을 만들고 색을 사용하여 관측값을 그룹화할 수 있습니다.
cyl468 = ismember(Cylinders,[4 6 8]); parallelcoords(X(cyl468,:),Group=Cylinders(cyl468), ... Standardize="on",Labels=varNames)
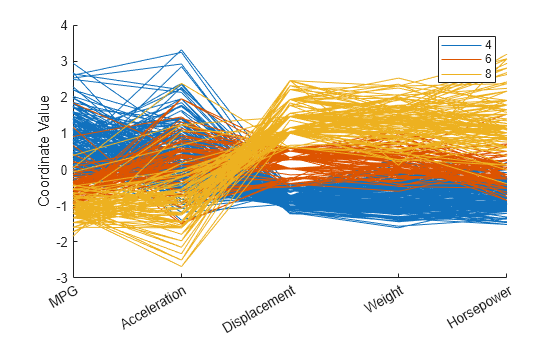
이 플롯에서 가로 방향은 좌표축을 나타내며, 세로축은 데이터를 나타냅니다. 관측값은 각각 5개 변수에 대한 측정값으로 구성됩니다. 각 관측값은 높이로 표현되고 그에 대응하는 선들은 각 좌표축을 가로지릅니다. 5개 변수는 매우 다양한 범위를 가지기 때문에 이 플롯의 각 변수는 평균 0과 분산 1을 갖도록 표준화됩니다. 색으로 구분된 이 그래프를 보면 8기통 자동차의 경우 MPG와 가속도에 대한 값은 낮고 배기량, 중량, 마력에 대한 값은 높은 경향이 있음을 알 수 있습니다.
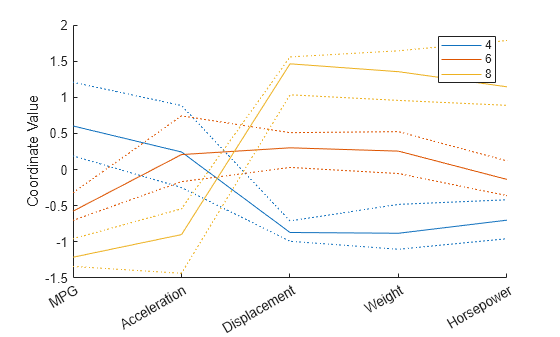
많은 수의 관측값이 포함된 평행좌표 플롯은 읽기가 어려울 수 있습니다. 이 문제를 완화하기 위해 각 그룹에 대해 중앙값과 상위 사분위수, 하위 사분위수(25% 점 및 75% 점)만 표시하는 평행좌표 플롯을 만들 수 있습니다. 이렇게 플롯을 사용하면 그룹을 더 잘 구별할 수 있지만 파악해야 할 수도 있는 관측값(예: 그룹 이상값)이 포함되지 않게 됩니다.
parallelcoords(X(cyl468,:),Group=Cylinders(cyl468), ... Standardize="on",Labels=varNames,Quantile=0.25)
앤드류스(Andrews) 플롯
다변량 시각화의 또 다른 유형은 앤드류스 플롯입니다. 이 플롯은 각 관측값을 구간 [0,1]에서 매끄러운 함수로 나타냅니다.
andrewsplot(X(cyl468,:),Group=Cylinders(cyl468),Standardize="on")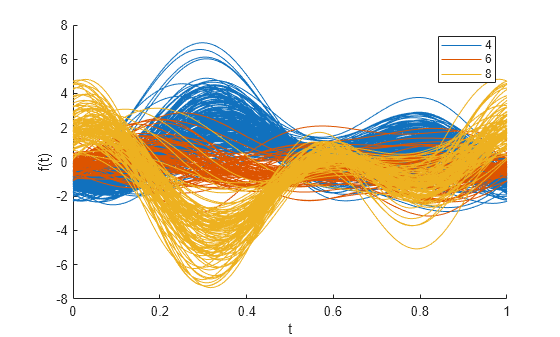
각 함수는 푸리에 급수이며 계수는 그에 대응하는 관측값의 값과 같습니다. 이 예제의 푸리에 급수는 총 5개의 항, 즉 상수항 1개, 주기가 각각 1과 1/2인 사인 항 2개, 사인 항과 유사한 코사인 항 2개를 가집니다. 앞의 세 항은 각 함수의 형태에 가장 뚜렷한 영향을 미칩니다. 즉, 처음 3개 변수의 패턴을 가장 쉽게 알아볼 수 있습니다.
플롯은 t = 0에서 그룹 간의 분명한 차이를 보여줍니다. 이 차이는 첫 번째 변수 MPG가 4기통, 6기통 또는 8기통이 탑재된 자동차를 서로 구별하는 특징 중 하나임을 나타냅니다. 약 t = 1/3에서 그룹 간의 차이도 흥미롭습니다. 이 값을 앤드류스 플롯 함수에 대한 공식에 입력합니다. 결과는 변수의 선형 결합을 정의하는 일련의 계수입니다. 이러한 선형 결합은 한 그룹을 다른 그룹과 구별하는 데 도움이 됩니다.
t1 = 1/3; coeffs = [1/sqrt(2) sin(2*pi*t1) cos(2*pi*t1) sin(4*pi*t1) cos(4*pi*t1)]
coeffs = 1×5
0.7071 0.8660 -0.5000 -0.8660 -0.5000
이들 계수는 8기통 자동차에 비해 4기통 자동차가 MPG과 가속도의 값이 더 높고 배기량, 마력, 특히 중량의 값이 더 낮다는 것을 나타냅니다. 이 결론은 평행좌표 플롯에서의 결론과 일치합니다.
그림문자 플롯
그림문자를 사용해 다변량 데이터를 시각화하여 차원을 나타낼 수도 있습니다. 함수 glyphplot은 2가지 유형의 그림문자, 즉 별과 체르노프 얼굴을 지원합니다. 데이터 세트에서 처음 9대 자동차 모델에 대한 별 플롯을 만듭니다. 별에서 각 축(spoke)은 하나의 변수를 나타내고 축 길이는 해당 관측값에 대한 변수의 값에 비례합니다.
g = glyphplot(X(1:9,:),Glyph="star",VarLabels=varNames, ... ObsLabels=Model(1:9,:)); set(g(:,3),FontSize=8);
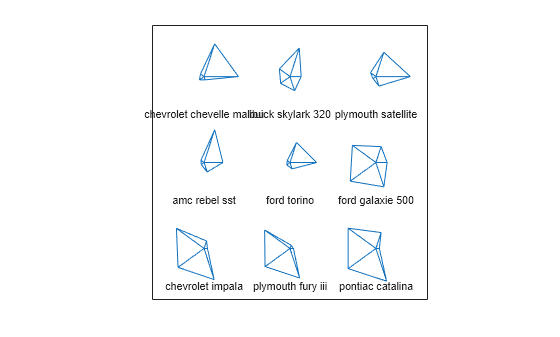
Figure 창에서 이 플롯을 사용하면 데이터 커서를 이용해 대화형 방식으로 데이터 값을 탐색할 수 있습니다. 예를 들어 Ford Torino에 대한 별의 가장 오른쪽 점을 클릭하면 해당 자동차의 MPG 값이 17임을 보여줍니다.
그림문자 플롯 및 다차원 스케일링
특정 순서 없이 그리드에 별을 플로팅하는 경우 인접한 별이 상당히 다르게 보이는 Figure가 만들어질 수 있습니다. 그러면 패턴을 시각적으로 인식하지 못할 수 있습니다. 패턴 인식에 도움이 되도록 다차원 스케일링(MDS)을 그림문자 플롯과 함께 사용하십시오.
먼저 1977년도 자동차를 모두 선택한 다음 zscore 함수를 사용하여 5개 변수 각각을 평균 0과 분산 1을 갖도록 표준화합니다. 그런 다음, 표준화된 관측값 사이의 유클리드 거리를 비유사성 척도로 계산합니다. 더 복잡한 응용 모델의 경우에는 덜 단순한 비유사성 척도를 사용해 보십시오.
models77 = find((Model_Year==77)); dissimilarity = pdist(zscore(X(models77,:)));
마지막으로, mdscale을 사용하여 원래 고차원 데이터 점 간의 차이를 근사하는 2차원 위치 집합을 생성합니다. 이러한 위치를 사용하여 그림문자를 플로팅합니다. 결과로 생성된 2차원 플롯에서 거리는 데이터를 대략적으로만 재현합니다.
Y = mdscale(dissimilarity,2); figure glyphplot(X(models77,:),Glyph="star",Centers=Y, ... VarLabels=varNames,ObsLabels=Model(models77,:),Radius=0.5) title("1977 Model Year")
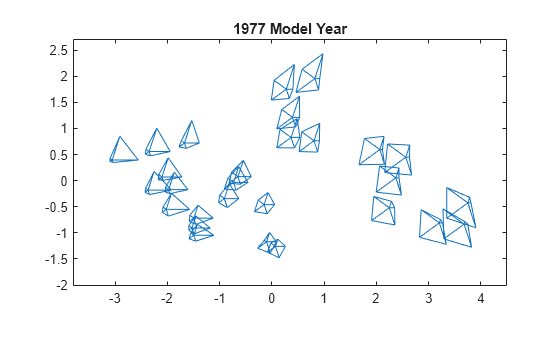
2차원 플롯은 MDS를 차원 축소 방법으로 사용합니다. 일반적으로 차원의 축소는 정보 손실을 의미하지만, 그림문자는 데이터의 모든 고차원 정보를 포함합니다. MDS를 사용하는 목적은 그림문자 사이의 패턴을 쉽게 확인할 수 있도록 데이터의 변동에 규칙성을 부여하는 데 있습니다.
앞의 플롯과 마찬가지로, Figure 창을 사용하여 이 플롯을 대화형 방식으로 탐색할 수 있습니다.
그림문자 플롯의 또 다른 유형은 체르노프 얼굴입니다. 이 그림문자는 각 관측값에 대한 데이터 값을 얼굴 특징(예: 얼굴의 크기, 얼굴의 모양, 눈의 위치 등)으로 인코딩합니다. 변수에 대한 특징의 대응 관계에 따라 어떤 관계를 플롯에서 가장 쉽게 볼 수 있는지가 결정됩니다. glyphplot을 사용하여 이러한 대응 관계를 지정합니다.
figure facePlot = glyphplot(X(models77,:),Glyph="face",Centers=Y, ... VarLabels=varNames,ObsLabels=Model(models77,:)); set(facePlot(:,1:2),Color="#D95319") title("1977 Model Year")
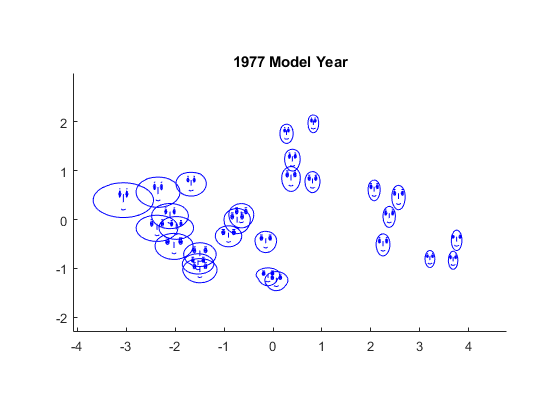
이 플롯에서 가장 눈에 띄는 2가지 특징인 얼굴 크기와 이마에서 턱까지의 상대적인 크기는 각각 MPG 변수와 가속도 변수를 인코딩합니다. 이마 모양과 턱 모양은 각각 배기량 변수와 중량 변수를 인코딩합니다. 눈 사이의 너비는 마력 변수를 인코딩합니다. 주목할만한 점은 넓은 이마와 좁은 턱을 가진 얼굴과 그 반대의 얼굴이 거의 없다는 것이며, 이는 배기량과 중량 간의 양의 선형 상관을 나타냅니다. 이 결과는 산점도 플롯 행렬의 결과와 일치합니다.
참고 항목
gplotmatrix | parallelcoords | andrewsplot | glyphplot