이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
andrewsplot
앤드류스(Andrews) 플롯
설명
andrewsplot(는 행렬 X)X의 다변량 데이터로부터 앤드류스 플롯을 만듭니다. 플롯은 X의 각 관측값에 대한 연속 곡선을 표시합니다. 자세한 내용은 앤드류스(Andrews) 플롯 항목을 참조하십시오.
andrewsplot(는 하나 이상의 이름-값 인수를 사용하여 추가 옵션을 지정합니다. 예를 들어 플로팅하기 전에 X,Name=Value)X의 데이터를 표준화하고 그룹화 변수를 사용하여 데이터를 그룹화할 수 있습니다.
andrewsplot(는 대상 좌표축 ax,___)ax에 플롯을 표시합니다. 이 좌표축을 위에 열거된 구문에서 첫 번째 입력 인수로 지정합니다.
예제
그룹화된 표본 데이터를 시각화하기 위해 앤드류스 플롯을 만듭니다.
세 가지 붓꽃 종에 대한 4가지 측정값(꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비)을 포함하는 fisheriris 데이터 세트를 불러옵니다.
load fisheriris행렬 meas는 150개 꽃에 대한 4가지 측정값을 모두 포함합니다. 셀형 배열 species는 150개 꽃 각각에 대한 종 이름을 포함합니다.
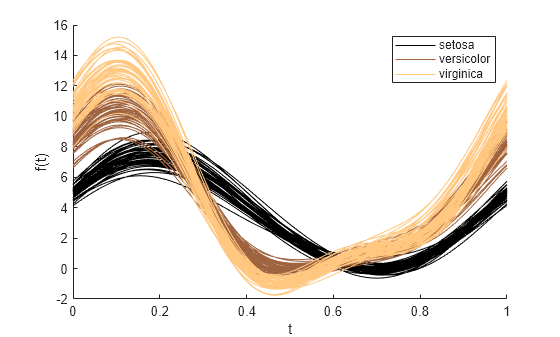
표본 데이터를 species로 그룹화하여 앤드류스 플롯을 만듭니다.
andrewsplot(meas,Group=species)

플롯은 각 관측값(꽃)을 구간 [0,1]에서 매끄러운 함수로 표시합니다. 각 곡선의 색은 꽃의 종을 나타냅니다.
각 그룹의 중앙값과 사분위수만 표시하는 단순화된 앤드류스 플롯을 하나 더 만듭니다.
andrewsplot(meas,Group=species,Quantile=0.25)
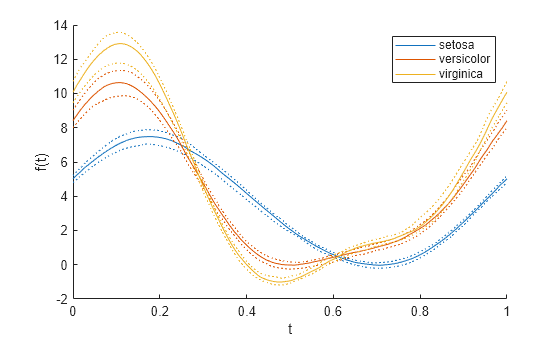
이 플롯은 각 그룹의 중앙값을 실선 곡선으로 표시하고 그 밖의 사분위수 값을 동일한 색의 점선 곡선으로 표시합니다.
앤드류스 플롯을 사용하여 다차원 데이터를 시각화합니다. 먼저 데이터를 그룹화합니다. 그런 다음 표준화와 사분위수를 사용하여 그룹 간의 차이를 확인합니다.
100명 환자에 대한 의료 정보를 포함하는 patients 데이터 세트를 불러옵니다. 1과 0 대신 설명적 범주 이름인 Smoker와 Nonsmoker를 지정합니다. 그런 다음 Diastolic 변수, Systolic 변수, Weight 변수, Age, Smoker 변수를 사용하여 테이블을 만듭니다.
load patients Smoker = categorical(Smoker,logical([1 0]), ... ["Smoker","Nonsmoker"]); patientData = table(Diastolic,Systolic,Weight,Age,Smoker);
patientData의 변수로부터 앤드류스 플롯을 만듭니다. 마지막 변수를 사용하여 흡연 상태에 따라 데이터를 그룹화합니다.
andrewsplot(patientData{:,1:end-1},Group=patientData.Smoker)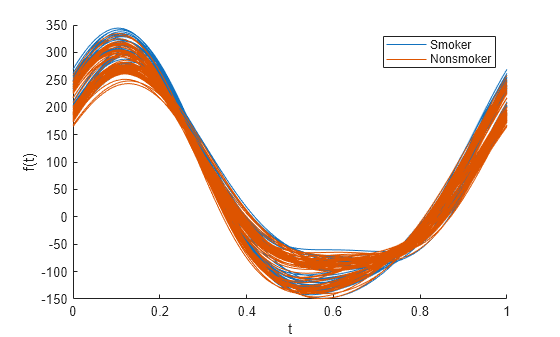
기본적으로 플롯은 표준화되지 않은 데이터를 사용합니다. 이 플롯에서는 Smoker 그룹과 Nonsmoker 그룹 간에 큰 차이가 보이지 않습니다.
플로팅하기 전에 숫자형 patientData 변수를 표준화합니다.
andrewsplot(patientData{:,1:end-1},Group=Smoker,Standardize="on")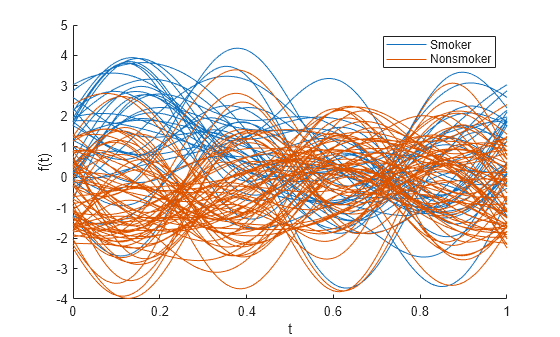
이번에 생성된 앤드류스 플롯에서는 Smoker 그룹과 Nonsmoker 그룹 간에 변동이 더 크게 나타납니다. 이 플롯은 patientData의 매 환자마다 100개 곡선을 표시했기 때문에 다소 복잡합니다.
각 관측값마다 곡선을 하나씩 표시하는 대신에 각 그룹의 사분위수 곡선을 표시합니다. 사분위수는 25번째 백분위수, 중앙값, 75번째 백분위수로 구성됩니다.
andrewsplot(patientData{:,1:end-1},Group=patientData.Smoker, ...
Standardize="on",Quantile=0.25)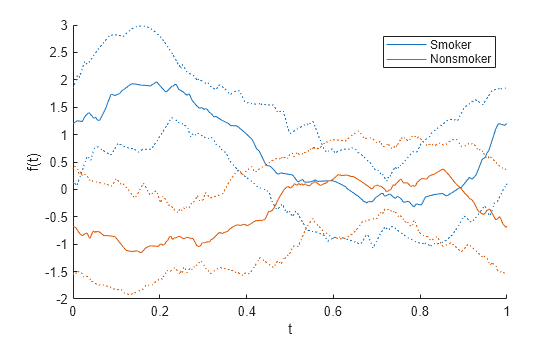
사분위수 곡선은 Smoker 그룹과 Nonsmoker 그룹 간의 차이를 보여줍니다. 예를 들어 약 0.25에서 두 그룹은 겹치지 않는 사분위수 값을 가지고 있습니다.
앤드류스 플롯에 표시되는 각 함수는 변수들의 선형 결합이며 해당 계수들은 시간이 지남에 따라 변한다는 점을 기억하십시오. (앤드류스(Andrews) 플롯 항목을 참조하십시오.) 시간 0.25에서의 변수에 대한 계수를 계산합니다. 이와 같은 변수들의 선형 결합은 그룹을 구별하는 데 도움이 될 수 있습니다.
t = 0.25; variables = patientData.Properties.VariableNames(1:end-1)
variables = 1×4 cell
{'Diastolic'} {'Systolic'} {'Weight'} {'Age'}
coefficients = [1/sqrt(2) sin(2*pi*t) cos(2*pi*t) sin(4*pi*t)]
coefficients = 1×4
0.7071 1.0000 0.0000 0.0000
시간 0.25에서, Diastolic 변수와 Systolic 변수는 비슷한 크기의 양의 계수를 가지고 있고 Weight 변수와 Age 변수는 0 계수를 가지고 있습니다. 위의 플롯은 데이터의 표준화 후에 Smoker 그룹의 사분위수 곡선은 시간 0.25에서 양의 값을 가지고 있고 Nonsmoker 그룹의 사분위수 곡선은 시간 0.25에서 음의 값을 가지고 있음을 보여줍니다.
이와 같은 플롯과 변수 계수는 Smoker 그룹의 환자들이 Diastolic 값과 Systolic 값이 더 높은 경향이 있음을 나타내며, 이는 patientData의 Smoker 그룹과 Nonsmoker 그룹을 구별하는 한 가지 방법을 제공합니다.
앤드류스 플롯의 모양을 조정합니다. andrewsplot 호출 시에 일부 플롯 속성을 설정할 수 있습니다. 또는 플롯을 만들기 전이나 만든 후에 모양을 지정할 수 있습니다.
세 가지 붓꽃 종에 대한 4가지 측정값(꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비)을 포함하는 fisheriris 데이터 세트를 불러옵니다.
load fisheriris행렬 meas는 150개 꽃에 대한 4가지 측정값을 모두 포함합니다. 셀형 배열 species는 150개 꽃 각각에 대한 종 이름을 포함합니다.
meas의 측정값 데이터와 species의 그룹 데이터를 사용하여 앤드류스 플롯을 만듭니다. 플로팅하기 전에 색 순서를 설정하여 그룹화된 데이터에 대해 디폴트가 아닌 색 체계(copper)를 지정합니다.
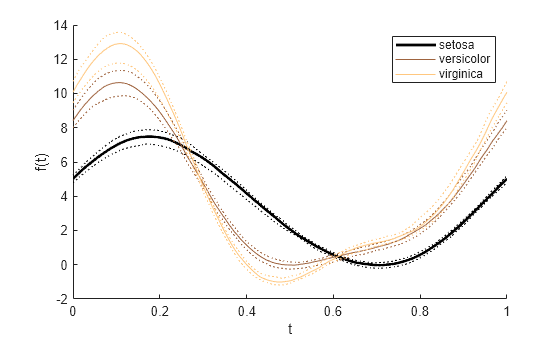
colororder(copper(3)) andrewsplot(meas,Group=species)
species의 각 그룹에 대해 중앙값 곡선, 25번째 백분위수 곡선, 75번째 백분위수 곡선만 플로팅합니다. 플롯 선을 더 굵게 만들기 위해 선 너비를 2로 지정합니다. andrewsplot에 대한 호출에 LineWidth 값을 지정하면 이 함수는 플롯 내 모든 곡선의 선 너비를 동일한 값으로 설정합니다.
andrewsplot(meas,Group=species,Quantile=0.25,LineWidth=2)

위의 플롯을 다시 만들되, 이번에는 setosa 그룹의 붓꽃에 대한 중앙값 측정값을 나타내는 곡선의 선 너비만 늘립니다. 먼저 Line 객체로 구성된 배열 p를 만듭니다. 여기서 각 객체는 플롯 내 하나의 곡선에 대응됩니다. 그런 다음 점 표기법을 사용하여 이 배열에 있는 첫 번째 Line 객체의 LineWidth 속성을 수정합니다.
p = andrewsplot(meas,Group=species,Quantile=0.25)
p = 9×1 Line array: Line (median) Line (lower quantile) Line (upper quantile) Line (median) Line (lower quantile) Line (upper quantile) Line (median) Line (lower quantile) Line (upper quantile)
p(1).LineWidth = 2;
입력 인수
이름-값 인수
출력 인수
세부 정보
팁
Line 속성에 나열된 속성에 대해 속성 이름과 값을 지정하여 플롯 곡선의 특성을 수정할 수 있습니다. 그러나 이 방법을 사용하면 수정 사항이 플롯 내 모든 곡선에 적용됩니다. 특정 플롯 곡선만 수정하려면
Line객체를 반환하는 구문을 사용한 후에 점 표기법을 사용하여 각 객체 속성을 개별적으로 조정하십시오. 예제는 플롯 모양 조정하기 항목을 참조하십시오.
버전 내역
R2006a 이전에 개발됨