이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
부분 최소제곱 회귀 및 주성분 회귀
이 예제에서는 부분 최소제곱 회귀(PLSR) 및 주성분 회귀(PCR)를 적용하는 방법을 보여주고 이 두 방법의 효과를 살펴봅니다. PLSR 및 PCR은 모두 다수의 예측 변수가 있으며 이러한 예측 변수가 밀접한 상관관계를 가지거나 동일직선상에 있는 경우 응답 변수를 모델링하는 방법입니다. 두 방법 모두 새 예측 변수(성분이라고 함)를 원래 예측 변수로 구성된 선형 결합으로 생성하지만, 이러한 성분을 생성하는 방법은 각기 다릅니다. PCR은 응답 변수를 전혀 고려하지 않고 예측 변수에서 관측된 변동성을 설명하기 위해 성분을 생성합니다. 반면, PLSR은 응답 변수를 고려하므로 더 적은 수의 성분으로 응답 변수를 피팅할 수 있는 모델이 생성되는 경우가 많습니다. 실용적인 측면에서 궁극적으로 더 간결한 모델로 변환되는지 여부는 상황에 따라 달라집니다.
데이터 불러오기
401개 파장에서 60개 가솔린 표본의 스펙트럼 강도와 옥탄가로 구성된 데이터 세트를 불러옵니다. 이 데이터는 Kalivas, John H., "Two Data Sets of Near Infrared Spectra," Chemometrics and Intelligent Laboratory Systems, v.37 (1997) pp.255-259에 설명되어 있습니다.
load spectra whos NIR octane
Name Size Bytes Class Attributes NIR 60x401 192480 double octane 60x1 480 double
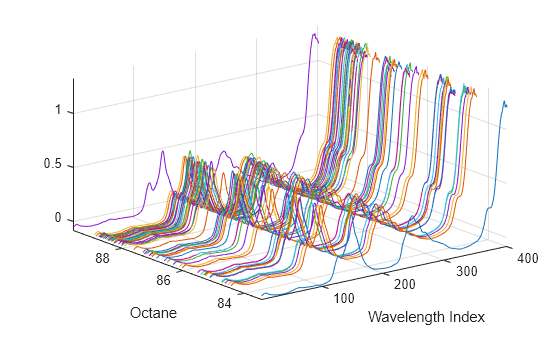
[dummy,h] = sort(octane); oldorder = get(gcf,'DefaultAxesColorOrder'); set(gcf,'DefaultAxesColorOrder',jet(60)); plot3(repmat(1:401,60,1)',repmat(octane(h),1,401)',NIR(h,:)'); set(gcf,'DefaultAxesColorOrder',oldorder); xlabel('Wavelength Index'); ylabel('Octane'); axis('tight'); grid on
두 성분으로 데이터 피팅하기
plsregress 함수를 사용하여 10개의 PLS 성분과 1개의 응답 변수를 갖는 PLSR 모델을 피팅하겠습니다.
X = NIR;
y = octane;
[n,p] = size(X);
[Xloadings,Yloadings,Xscores,Yscores,betaPLS10,PLSPctVar] = plsregress(...
X,y,10);10개 성분은 데이터를 적절히 피팅하는 데 필요한 수보다 더 많을 수 있지만, 이 피팅에서 얻은 진단 정보를 사용하여 더 적은 성분을 갖는 더 단순한 모델을 선택할 수 있습니다. 예를 들어, 성분 개수를 선택하는 한 가지 빠른 방법은 응답 변수에 설명된 분산의 백분율을 성분 개수에 대한 함수로 플로팅하는 것입니다.
plot(1:10,cumsum(100*PLSPctVar(2,:)),'-bo'); xlabel('Number of PLS components'); ylabel('Percent Variance Explained in Y');

실제로, 성분 개수를 선택할 때는 좀 더 주의를 기울이는 것이 좋습니다. 일례로, 널리 사용되는 교차 검증에 관해 이 예제의 뒷부분에서 설명합니다. 여기서는 위에 표시된 플롯을 보면 두 성분을 갖는 PLSR이 관측된 y의 분산을 대부분 설명하는 것을 알 수 있습니다. 2-성분 모델에 피팅되는 응답 변수 값을 구합니다.
[Xloadings,Yloadings,Xscores,Yscores,betaPLS] = plsregress(X,y,2); yfitPLS = [ones(n,1) X]*betaPLS;
다음으로, 2개의 주성분을 갖는 PCR 모델을 피팅합니다. 첫 번째 단계는 2개의 주성분을 계속 유지해 pca 함수를 사용하여 X에 대한 주성분 분석을 수행하는 것입니다. 이 경우 PCR은 단순하게 이러한 두 성분에 대한 응답 변수의 선형 회귀입니다. 변수 간의 변동성이 매우 다른 경우 대개 먼저 표준편차로 각 변수를 정규화하는 것이 적합하지만 여기서는 그렇게 하지 않겠습니다.
[PCALoadings,PCAScores,PCAVar] = pca(X,'Economy',false);
betaPCR = regress(y-mean(y), PCAScores(:,1:2));원래 스펙트럼 데이터 측면에서 PCR 결과를 더 쉽게 해석하기 위해, 중심화하지 않은 원래 변수에 대한 회귀 계수로 변환하겠습니다.
betaPCR = PCALoadings(:,1:2)*betaPCR; betaPCR = [mean(y) - mean(X)*betaPCR; betaPCR]; yfitPCR = [ones(n,1) X]*betaPCR;
PLSR 피팅과 PCR 피팅에 대해 피팅된 응답 변수와 관측된 응답 변수를 플로팅합니다.
plot(y,yfitPLS,'bo',y,yfitPCR,'r^'); xlabel('Observed Response'); ylabel('Fitted Response'); legend({'PLSR with 2 Components' 'PCR with 2 Components'}, ... 'location','NW');
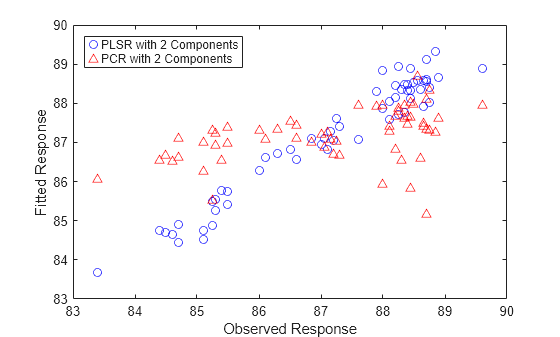
어떤 면에서는 위 플롯의 비교가 타당하지 않습니다. 2-성분 PLSR 모델이 응답 변수를 얼마나 잘 예측했는지를 확인하여 성분 개수(2개)가 선택되었지만 PCR 모델이 같은 성분 개수로 제한되어야 하는 이유는 없습니다. 그러나 이 동일한 성분 개수를 선택하면 PLSR이 y 피팅을 더 훨씬 잘 수행합니다. 실제로, 위의 플롯에서 피팅된 값의 가로 산점도를 살펴보면 2개 성분을 갖는 PCR이 상수 모델을 사용하는 경우보다 더 우수한 성능을 제공하지는 않는 것으로 보입니다. 이 두 회귀에서 얻은 결정계수 값을 통해 이를 알 수 있습니다.
TSS = sum((y-mean(y)).^2); RSS_PLS = sum((y-yfitPLS).^2); rsquaredPLS = 1 - RSS_PLS/TSS
rsquaredPLS = 0.9466
RSS_PCR = sum((y-yfitPCR).^2); rsquaredPCR = 1 - RSS_PCR/TSS
rsquaredPCR = 0.1962
두 모델의 예측 검정력을 비교하는 또 다른 방법은 두 경우 모두에서 두 예측 변수에 대해 응답 변수를 플로팅하는 것입니다.
plot3(Xscores(:,1),Xscores(:,2),y-mean(y),'bo'); legend('PLSR'); grid on; view(-30,30);
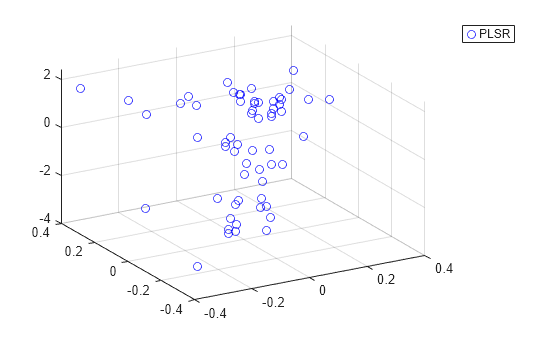
대화형 방식으로 그림을 회전할 수 없는 경우 확인하기가 약간 어렵지만, 위의 PLSR 플롯을 보면 점들이 한 평면에 대해 빽빽하게 흩어져 있음을 알 수 있습니다. 반면, 아래에 표시된 PCR 플롯은 선형 관계가 거의 없는 점 구름을 보여줍니다.
plot3(PCAScores(:,1),PCAScores(:,2),y-mean(y),'r^'); legend('PCR'); grid on; view(-30,30);

두 PLS 성분은 관측된 y에 대한 훨씬 더 나은 예측 변수이지만 다음 그림은 이 성분이 PCR에 사용된 처음 2개 주성분보다 관측된 X에서 다소 더 작은 분산을 설명한다는 것을 보여줍니다.
plot(1:10,100*cumsum(PLSPctVar(1,:)),'b-o',1:10, ... 100*cumsum(PCAVar(1:10))/sum(PCAVar(1:10)),'r-^'); xlabel('Number of Principal Components'); ylabel('Percent Variance Explained in X'); legend({'PLSR' 'PCR'},'location','SE');

PCR 곡선이 균일하게 더 높다는 사실은 두 성분을 갖는 PCR이 y를 피팅할 때 PLSR에 비해 성능이 훨씬 더 낮음을 보여줍니다. PCR은 X를 가장 잘 설명하도록 성분을 생성합니다. 그 결과, 처음 두 성분은 관측된 y를 피팅하는 데 중요한 데이터의 정보를 무시합니다.
3개 이상의 성분으로 피팅하기
PCR에 더 많은 성분이 추가될수록 원래 데이터 y를 피팅하는 성능이 더 높아집니다. 그 이유는 어느 시점에 X의 중요한 예측 정보 대부분이 주성분에 존재하기 때문입니다. 예를 들어, 다음 그림은 2개 성분일 때보다 10개 성분을 사용할 때 두 방법에서 잔차의 차이가 훨씬 더 적다는 것을 보여줍니다.
yfitPLS10 = [ones(n,1) X]*betaPLS10; betaPCR10 = regress(y-mean(y), PCAScores(:,1:10)); betaPCR10 = PCALoadings(:,1:10)*betaPCR10; betaPCR10 = [mean(y) - mean(X)*betaPCR10; betaPCR10]; yfitPCR10 = [ones(n,1) X]*betaPCR10; plot(y,yfitPLS10,'bo',y,yfitPCR10,'r^'); xlabel('Observed Response'); ylabel('Fitted Response'); legend({'PLSR with 10 components' 'PCR with 10 Components'}, ... 'location','NW');

PLSR이 여전히 약간 더 정확한 피팅을 수행하기는 하지만 두 모델 모두 y를 상당히 정확하게 피팅합니다. 그러나, 성분 10개 역시 각 모델에 대해 임의로 선택한 개수입니다.
교차검증을 사용하여 성분 개수 선택하기
예측 변수에 대한 향후 관측값에서 응답 변수를 예측할 때 예상 오차를 최소화하도록 성분 개수를 선택하는 것이 유용한 경우가 많습니다. 간단히 많은 개수의 성분을 사용하면 현재 관측된 데이터를 피팅할 때 양호한 성능을 제공할 수 있지만, 이 전략은 과적합을 초래할 수 있습니다. 현재 데이터를 과도하게 정확하게 피팅하면 다른 데이터에 제대로 일반화되지 않는 모델이 생성되며, 그러면 예상 오차에 대해 지나치게 낙관적인 추정값이 제공됩니다.
교차 검증은 PLSR 또는 PCR에서 성분 개수를 선택하는 데 통계적으로 더욱 타당한 방법입니다. 이 방법을 사용하면 모델을 피팅하고 예측 오차를 추정하는 데 동일한 데이터를 재사용하지 않고 데이터의 과적합을 방지할 수 있습니다. 따라서, 예측 오차에 대한 추정값이 낙관적으로 하향 편향되지 않습니다.
plsregress에서는 옵션인 교차 검증을 사용하여 평균 제곱 예측 오차(MSEP)를 추정할 수 있습니다. 이 경우 10겹 교차 검증을 사용합니다.
[Xl,Yl,Xs,Ys,beta,pctVar,PLSmsep] = plsregress(X,y,10,'CV',10);PCR의 경우, crossval을 PCR의 오차제곱합을 계산하는 단순한 함수와 함께 사용하면 똑같이 10겹 교차 검증을 사용하여 MSEP를 추정할 수 있습니다.
PCRmsep = sum(crossval(@pcrsse,X,y,'KFold',10),1) / n;PLSR의 MSEP 곡선은 두 개 또는 세 개 성분으로 최고의 성능을 얻을 수 있음을 나타냅니다. 반면, PCR이 동일한 예측 정확도를 얻으려면 4개의 성분이 필요합니다.
plot(0:10,PLSmsep(2,:),'b-o',0:10,PCRmsep,'r-^'); xlabel('Number of components'); ylabel('Estimated Mean Squared Prediction Error'); legend({'PLSR' 'PCR'},'location','NE');
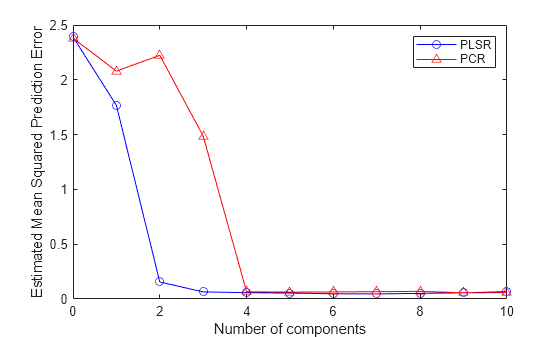
실제로, PCR의 두 번째 성분은 모델의 예측 오차를 증가시킵니다. 이는 해당 성분에 포함된 예측 변수의 결합이 y와 긴밀한 상관관계가 없음을 나타냅니다. 마찬가지로, PCR이 y가 아니라 X의 변동을 설명하기 위해 성분을 생성하기 때문입니다.
모델 간결성
그렇다면 PCR이 3개의 성분을 갖는 PLSR과 동일한 예측 정확도를 달성하기 위해서는 4개의 성분이 필요하다고 가정할 경우 PLSR 모델이 더 간결한 것일까요? 이는 모델의 어떤 측면을 고려하는지에 따라 달라집니다.
PLS 가중치는 PLS 성분을 정의하는 원래 변수의 선형 결합입니다. 즉, PLS 가중치는 PLSR의 각 성분이 원래 변수에 어떠한 방향으로 얼마나 크게 종속되는지를 설명합니다.
[Xl,Yl,Xs,Ys,beta,pctVar,mse,stats] = plsregress(X,y,3); plot(1:401,stats.W,'-'); xlabel('Variable'); ylabel('PLS Weight'); legend({'1st Component' '2nd Component' '3rd Component'}, ... 'location','NW');

이와 유사하게, PCA 적재값은 PCR의 각 성분이 원래 변수에 얼마나 크게 종속되는지를 설명합니다.
plot(1:401,PCALoadings(:,1:4),'-'); xlabel('Variable'); ylabel('PCA Loading'); legend({'1st Component' '2nd Component' '3rd Component' ... '4th Component'},'location','NW');

PLSR 또는 PCR에서 어떠한 변수에 가장 큰 가중치를 적용하는지를 검사하여 각 성분에 실제로 의미 있는 해석방식을 제공할 수 있습니다. 예를 들어, 이 스펙트럼 데이터에서는 가솔린에 존재하는 화합물 측면에서 최대 강도를 해석한 후 적은 수의 화합물에서 특정 성분을 선별해 이러한 가중치를 관측할 수 있습니다. 이러한 관점에서 성분 수가 적을수록 해석 과정이 더 단순하며, PLSR이 응답 변수를 적절히 예측하는 데 더 적은 수의 성분이 필요한 경우가 많으므로 PLSR에서 더 간결한 모델이 생성됩니다.
한편, PLSR과 PCR 모두 원래 예측 변수 각각에 대해 하나의 회귀 계수와 함께 하나의 절편을 생성합니다. 이러한 점에서, 사용되는 성분 개수에 관계없이 두 모델 모두 모든 예측 변수에 종속되므로 둘 중 어느 것도 상대적으로 더 간결하지 않습니다. 더 구체적으로 설명하자면, 이 데이터에서 예측을 수행하기 위해서는 두 모델 모두 401개의 스펙트럼 강도 값을 필요로 합니다.
그러나 궁극적인 목표는 응답 변수를 정확하게 예측하는 데 영향을 주지 않는 한도 내에서 원래 변수 집합을 최대한 작은 부분 집합으로 줄이는 것입니다. 예를 들어, PLS 가중치 또는 PCA 적재값을 사용하여 각 성분에 가장 큰 영향을 미치는 변수만 선택할 수 있습니다. 앞에서 살펴본 것처럼 PCR 모델 피팅에서 몇몇 성분이 예측 변수의 변동을 주요하게 설명할 수 있으며, 그들 성분은 또한 응답 변수와 긴밀한 상관관계가 있지 않은 변수에 대한 큰 가중치를 포함할 수 있습니다. 따라서, PCR이 예측에 불필요한 변수를 유지하는 결과를 초래합니다.
이 예제에 사용된 데이터의 경우에는 PLSR 및 PCR이 정확한 예측을 수행하는 데 필요한 성분 개수 차이는 크지 않으며 PLS 가중치와 PCA 적재값이 동일한 변수에서 선택된 것처럼 보입니다. 이 점은 다른 데이터에는 해당되지 않을 수 있습니다.