GapEvaluation
Gap criterion clustering evaluation object
Description
GapEvaluation is an object consisting of sample data (X), clustering data (OptimalY), and gap criterion values
(CriterionValues) used to
evaluate the optimal number of clusters (OptimalK). The gap criterion values
correspond to the difference ExpectedLogW –
LogW, where W is the within-cluster dispersion,
ExpectedLogW is determined by Monte Carlo sampling from a reference
distribution, and LogW is computed from the sample data. The optimal
number of clusters corresponds to the solution with the largest local or global gap value
within a tolerance range (SearchMethod). For
more information, see Gap Value.
Creation
Create a gap criterion clustering evaluation object by using the evalclusters function and specifying the criterion as
"gap".
You can then use compact to create a compact version of the gap
criterion clustering evaluation object. The function removes the contents of the properties
X, OptimalY, and
Missing.
Properties
Object Functions
Examples
Evaluate the optimal number of clusters using the gap clustering evaluation criterion.
Load the fisheriris data set. The data contains length and width measurements from the sepals and petals of three species of iris flowers.
load fisheririsEvaluate the optimal number of clusters based on the gap criterion values. Cluster the data using kmeans.
rng("default") % For reproducibility evaluation = evalclusters(meas,"kmeans","gap","KList",1:6)
evaluation =
GapEvaluation with properties:
NumObservations: 150
InspectedK: [1 2 3 4 5 6]
CriterionValues: [0.0720 0.5928 0.8762 1.0114 1.0534 1.0720]
OptimalK: 5
Properties, Methods
The OptimalK value indicates that, based on the gap criterion, the optimal number of clusters is five.
Plot the gap criterion values for each number of clusters tested.
plot(evaluation)
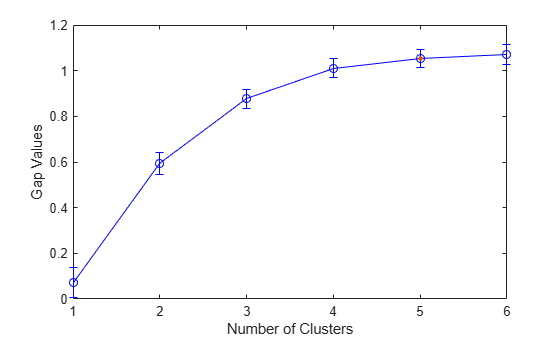
Based on the plot, the maximum value of the gap criterion occurs at six clusters. However, the value at five clusters is within one standard error of the maximum, so the suggested optimal number of clusters is five.
Create a grouped scatter plot to examine the relationship between petal length and width. Group the data by the suggested clusters.
PetalLength = meas(:,3);
PetalWidth = meas(:,4);
clusters = evaluation.OptimalY;
gscatter(PetalLength,PetalWidth,clusters,[],"xod^*");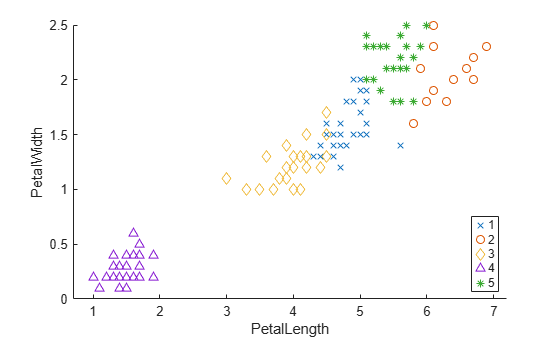
The plot shows cluster 4 in the lower-left corner, completely separated from the other four clusters. Cluster 4 contains flowers with the smallest petal widths and lengths. Cluster 2 is in the upper-right corner, and contains flowers with the largest petal widths and lengths. Cluster 5 is next to cluster 2, and contains flowers with similar petal widths but smaller petal lengths compared to the flowers in cluster 2. Clusters 1 and 3 are near the center of the plot, and contain flowers with measurements between the extremes.
More About
References
[1] Tibshirani, R., G. Walther, and T. Hastie. “Estimating the number of clusters in a data set via the gap statistic.” Journal of the Royal Statistical Society: Series B. Vol. 63, Part 2, 2001, pp. 411–423.
Version History
Introduced in R2013b