이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
rlDQNAgent
DQN(심층 Q-신경망) 강화 학습 에이전트
설명
DQN(심층 Q-신경망) 알고리즘은 이산 행동 공간이 있는 환경에 대한 오프-폴리시 강화 학습 방법입니다. DQN 에이전트는 최적의 정책 값을 추정하도록 Q-값 함수 크리틱을 훈련시키면서, 크리틱에 의해 추정된 값을 기반으로 엡실론-그리디 정책을 따릅니다. DQN은 타깃 크리틱과 경험 버퍼를 특징으로 하는 Q-러닝의 변형된 형태입니다. DQN 에이전트는 오프라인 훈련(환경 없이, 저장된 데이터에서 훈련)을 지원합니다.
자세한 내용은 DQN(심층 Q-신경망) 에이전트 항목을 참조하십시오. 다양한 유형의 강화 학습 에이전트에 대한 자세한 내용은 강화 학습 에이전트 항목을 참조하십시오.
생성
구문
설명
관측값 사양과 행동 사양을 사용하여 에이전트 생성
agent = rlDQNAgent(observationInfo,actionInfo)observationInfo와 행동 사양 actionInfo로부터 구축된 디폴트 벡터(즉, 다중 출력) Q-값 심층 신경망을 사용합니다. agent의 ObservationInfo 및 ActionInfo 속성은 각각 observationInfo 및 actionInfo 입력 인수로 설정됩니다.
agent = rlDQNAgent(observationInfo,actionInfo,initOpts)initOpts 객체에 지정된 옵션을 사용하여 구성된 디폴트 신경망을 사용합니다. 초기화 옵션에 대한 자세한 내용은 rlAgentInitializationOptions를 참조하십시오.
크리틱을 사용하여 에이전트 생성
agent = rlDQNAgent(critic)
에이전트 옵션 지정
agent = rlDQNAgent(critic,agentOptions)AgentOptions 속성을 agentOptions 입력 인수로 설정합니다. 이 구문은 위에 열거된 구문에 나와 있는 입력 인수 다음에 사용하십시오.
입력 인수
속성
객체 함수
train | Train reinforcement learning agents within a specified environment |
sim | Simulate trained reinforcement learning agents within specified environment |
getAction | Obtain action from agent, actor, or policy object given environment observations |
getCritic | Extract critic from reinforcement learning agent |
setCritic | Set critic of reinforcement learning agent |
generatePolicyFunction | Generate MATLAB function that evaluates policy of an agent or policy object |
예제
이산 행동 공간이 있는 환경을 만들고 관측값 사양과 행동 사양을 가져옵니다. 이 예제에서는 예제 Create DQN Agent Using Deep Network Designer and Train Using Image Observations에 사용된 환경을 불러옵니다. 이 환경은 두 가지의 관측값을 가집니다. 하나는 50×50 회색조 영상이고 다른 하나는 진자의 각속도를 나타내는 스칼라입니다. 행동은 5개의 가능한 요소(흔들리는 폴에 적용된 -2Nm, -1Nm, 0Nm, 1Nm 또는 2Nm의 토크)가 포함된 스칼라입니다.
% Load predefined environment env = rlPredefinedEnv("SimplePendulumWithImage-Discrete"); % Obtain observation and action specifications obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
에이전트 생성 함수는 액터 및 크리틱 신경망을 무작위로 초기화합니다. 난수 생성기의 시드값을 고정하여 재현이 가능하도록 할 수 있습니다.
rng(0)
환경 관측값 사양과 행동 사양을 사용하여 심층 Q-신경망 에이전트를 만듭니다.
agent = rlDQNAgent(obsInfo,actInfo);
에이전트를 확인하기 위해 getAction을 사용하여 임의 관측값에서 행동을 반환합니다.
getAction(agent,{rand(obsInfo(1).Dimension),rand(obsInfo(2).Dimension)})ans = 1×1 cell array
{[1]}
이제 환경 내에서 에이전트를 테스트하고 훈련시킬 수 있습니다.
이산 행동 공간이 있는 환경을 만들고 관측값 사양과 행동 사양을 가져옵니다. 이 예제에서는 예제 Create DQN Agent Using Deep Network Designer and Train Using Image Observations에 사용된 환경을 불러옵니다. 이 환경은 두 가지의 관측값을 가집니다. 하나는 50×50 회색조 영상이고 다른 하나는 진자의 각속도를 나타내는 스칼라입니다. 행동은 5개의 가능한 요소(흔들리는 폴에 적용된 -2Nm, -1Nm, 0Nm, 1Nm 또는 2Nm의 토크)가 포함된 스칼라입니다.
% Load predefined environment env = rlPredefinedEnv("SimplePendulumWithImage-Discrete"); % Obtain observation and action specifications obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
신경망에서 은닉 완전 연결 계층이 갖는 뉴런 수를 (디폴트 개수인 256개 대신에) 128개로 지정하여 agent initialization option 객체를 만듭니다.
initOpts = rlAgentInitializationOptions(NumHiddenUnit=128);
에이전트 생성 함수는 액터 및 크리틱 신경망을 무작위로 초기화합니다. 난수 생성기의 시드값을 고정하여 섹션의 재현이 가능하도록 합니다.
rng(0)
환경 관측값 사양과 행동 사양을 사용하여 정책 경사 에이전트를 만듭니다.
agent = rlDQNAgent(obsInfo,actInfo,initOpts);
두 크리틱에서 각각 심층 신경망을 추출합니다.
criticNet = getModel(getCritic(agent));
은닉 완전 연결 계층이 각각 128개의 뉴런을 갖는지 확인하려면 해당 계층을 다음과 같이 MATLAB® 명령 창에 표시할 수 있습니다.
criticNet.Layers
또는 다음과 같이 analyzeNetwork를 사용하여 대화형 방식으로 구조를 시각화할 수 있습니다.
analyzeNetwork(criticNet)
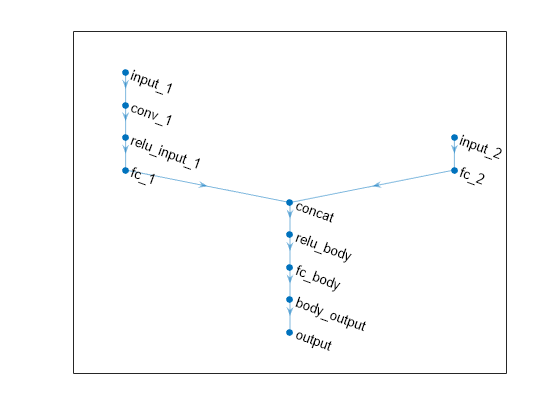
크리틱 신경망을 플로팅합니다.
plot(criticNet)
에이전트를 확인하기 위해 getAction을 사용하여 임의 관측값에서 행동을 반환합니다.
getAction(agent,{rand(obsInfo(1).Dimension),rand(obsInfo(2).Dimension)})ans = 1×1 cell array
{[0]}
이제 환경 내에서 에이전트를 테스트하고 훈련시킬 수 있습니다.
환경 객체를 만들고 관측값 사양과 행동 사양을 가져옵니다. 이 예제에서는 이산 카트-폴 시스템의 균형을 유지하도록 DQN 에이전트 훈련시키기 예제에 사용된 미리 정의된 환경을 불러옵니다. 이 환경에는 4차원 연속 관측값 공간(카트와 폴의 위치와 속도)과 1차원 이산 행동 공간(값이 -10N 또는 10N인 두 개의 가능한 힘이 적용되어 구성됨)이 있습니다.
미리 정의된 환경을 만듭니다.
env = rlPredefinedEnv("CartPole-Discrete");관측값 객체와 행동 사양 객체를 가져옵니다.
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
DQN 에이전트는 관측값과 행동이 주어지면 파라미터화된 Q-값 함수 크리틱을 사용하여 장기 보상을 근사합니다.
DQN 에이전트는 이산 행동 공간을 가지므로 벡터(즉, 다중 출력) Q-값 함수 크리틱을 만들 수 있는데, 일반적으로 이 방식이 그에 상응하는 단일 출력 크리틱보다 더 효율적입니다. 벡터 Q-값 함수는 환경 관측값을 벡터에 매핑한 것이며, 이 벡터의 각 요소는 에이전트가 주어진 관측값에 해당하는 상태에서 시작하여 요소 번호에 해당하는 행동을 실행하고 그 후에는 주어진 정책을 따를 때 기대되는 감가된 누적 장기 보상을 나타냅니다.
크리틱 내에서 Q-값 함수를 모델링하려면 심층 신경망을 사용하십시오. 신경망에는 (obsInfo로 지정된 대로 관측값 채널의 내용을 받는) 하나의 입력 계층과 (가능한 모든 행동에 대한 값으로 구성된 벡터를 반환하는) 하나의 출력 계층이 있어야 합니다.
신경망을 layer 객체로 구성된 배열로 정의하고, 환경 사양 객체에서 관측값 공간 차원(즉, prod(obsInfo.Dimension))과 가능한 행동 개수(즉, numel(actInfo.Elements))를 직접 가져옵니다.
dnn = [
featureInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(24)
reluLayer
fullyConnectedLayer(24)
reluLayer
fullyConnectedLayer(numel(actInfo.Elements))
];신경망을 dlnetwork 객체로 변환하고 가중치 개수를 표시합니다.
dnn = dlnetwork(dnn); summary(dnn)
Initialized: true
Number of learnables: 770
Inputs:
1 'input' 4 features
rlVectorQValueFunction과 함께 신경망 dnn, 관측값 및 행동 사양을 사용하여 크리틱을 만듭니다.
critic = rlVectorQValueFunction(dnn,obsInfo,actInfo);
임의의 관측값 입력값을 사용하여 크리틱이 작동하는지 확인합니다.
getValue(critic,{rand(obsInfo.Dimension)})ans = 2×1 single column vector
-0.0361
0.0913
크리틱을 사용하는 DQN 에이전트를 만듭니다.
agent = rlDQNAgent(critic)
agent =
rlDQNAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDQNAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlFiniteSetSpec]
SampleTime: 1
크리틱에 대한 훈련 옵션을 포함하여 에이전트 옵션을 지정합니다.
agent.AgentOptions.UseDoubleDQN=false;
agent.AgentOptions.TargetUpdateMethod="periodic";
agent.AgentOptions.TargetUpdateFrequency=4;
agent.AgentOptions.ExperienceBufferLength=100000;
agent.AgentOptions.DiscountFactor=0.99;
agent.AgentOptions.MiniBatchSize=256;
agent.AgentOptions.CriticOptimizerOptions.LearnRate=1e-2;
agent.AgentOptions.CriticOptimizerOptions.GradientThreshold=1;에이전트를 확인하기 위해 getAction을 사용하여 임의 관측값에서 행동을 반환합니다.
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[10]}
이제 환경 내에서 에이전트를 테스트하고 훈련시킬 수 있습니다.
환경 객체를 만들고 관측값 사양과 행동 사양을 가져옵니다. 이 예제에서는 이산 카트-폴 시스템의 균형을 유지하도록 DQN 에이전트 훈련시키기 예제에 사용된 미리 정의된 환경을 불러옵니다. 이 환경에는 4차원 연속 관측값 공간(카트와 폴의 위치와 속도)과 1차원 이산 행동 공간(값이 -10N 또는 10N인 두 개의 가능한 힘이 적용되어 구성됨)이 있습니다.
미리 정의된 환경을 만듭니다.
env = rlPredefinedEnv("CartPole-Discrete");관측값 객체와 행동 사양 객체를 가져옵니다.
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
DQN 에이전트는 다중 출력 Q-값 함수 크리틱을 사용할 수 있는데, 일반적으로 이 방식이 그에 상응하는 단일 출력 크리틱보다 더 효율적입니다. 하지만 이 예제에서는 단일 출력 Q-값 함수 크리틱을 대신 만듭니다.
Q-값 함수 크리틱은 현재 관측값과 행동을 입력값으로 받고 single형 스칼라를 출력값(현재 관측값에 해당하는 상태로부터 행동을 취하고 이후 정책을 따랐을 때 추정되는 감가된 누적 장기 보상)으로 반환합니다.
크리틱 내에서 파라미터화된 Q-값 함수를 모델링하려면 두 개의 입력 계층(obsInfo로 지정된 대로 관측값 채널에 대한 입력 계층 및 actInfo로 지정된 대로 행동 채널에 대한 입력 계층)과 (스칼라 값을 반환하는) 하나의 출력 계층을 갖는 신경망을 사용하십시오.
prod(obsInfo.Dimension)과 prod(actInfo.Dimension)은 행 벡터, 열 벡터 또는 행렬로 정렬되는지에 관계없이 각각 관측값 공간과 행동 공간의 차원 수를 반환합니다.
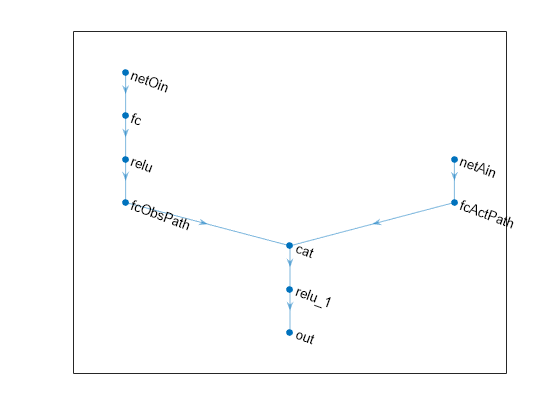
각 신경망 경로를 layer 객체로 구성된 배열로 정의하고 각 경로의 입력 계층과 출력 계층에 이름을 할당하여 경로를 연결합니다.
% Observation path obsPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="netOin") fullyConnectedLayer(24) reluLayer fullyConnectedLayer(24,Name="fcObsPath") ]; % Action path actPath = [ featureInputLayer(prod(actInfo.Dimension),Name="netAin") fullyConnectedLayer(24,Name="fcActPath") ]; % Common path (concatenate inputs along dim #1) commonPath = [ concatenationLayer(1,2,Name="cat") reluLayer fullyConnectedLayer(1,Name="out") ];
dlnetwork 객체를 조합합니다.
net = dlnetwork; net = addLayers(net,obsPath); net = addLayers(net,actPath); net = addLayers(net,commonPath);
계층을 연결합니다.
net = connectLayers(net,"fcObsPath","cat/in1"); net = connectLayers(net,"fcActPath","cat/in2");
신경망을 플로팅합니다.
plot(net)
신경망을 초기화하고 가중치 개수를 표시합니다.
net = initialize(net); summary(net)
Initialized: true
Number of learnables: 817
Inputs:
1 'netOin' 4 features
2 'netAin' 1 features
net, 환경 관측값 및 행동 사양, 그리고 환경 관측값 채널 및 행동 채널과 연결할 신경망 입력 계층의 이름을 사용하여 크리틱 근사기 객체를 만듭니다. 자세한 내용은 rlQValueFunction 항목을 참조하십시오.
critic = rlQValueFunction(net, ... obsInfo, ... actInfo, ... ObservationInputNames="netOin", ... ActionInputNames="netAin");
임의의 관측값 입력값과 행동 입력값을 사용하여 크리틱을 확인합니다.
getValue(critic,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
-0.0232
크리틱을 사용하는 DQN 에이전트를 만듭니다.
agent = rlDQNAgent(critic)
agent =
rlDQNAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDQNAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlFiniteSetSpec]
SampleTime: 1
크리틱에 대한 훈련 옵션을 포함하여 에이전트 옵션을 지정합니다.
agent.AgentOptions.UseDoubleDQN=false;
agent.AgentOptions.TargetUpdateMethod="periodic";
agent.AgentOptions.TargetUpdateFrequency=4;
agent.AgentOptions.ExperienceBufferLength=100000;
agent.AgentOptions.DiscountFactor=0.99;
agent.AgentOptions.MiniBatchSize=256;
agent.AgentOptions.CriticOptimizerOptions.LearnRate=1e-2;
agent.AgentOptions.CriticOptimizerOptions.GradientThreshold=1;에이전트를 확인하기 위해 getAction을 사용하여 임의 관측값에서 행동을 반환합니다.
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[10]}
이제 환경 내에서 에이전트를 테스트하고 훈련시킬 수 있습니다.
이 예제에서는 이산 카트-폴 시스템의 균형을 유지하도록 DQN 에이전트 훈련시키기 예제에 사용된 미리 정의된 환경을 불러옵니다. 이 환경에는 4차원 연속 관측값 공간(카트와 폴의 위치와 속도)과 1차원 이산 행동 공간(값이 -10N 또는 10N인 두 개의 가능한 힘이 적용되어 구성됨)이 있습니다.
env = rlPredefinedEnv("CartPole-Discrete");관측값 객체와 행동 사양 객체를 가져옵니다.
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
DQN 에이전트의 경우 벡터 함수 근사기 rlVectorQValueFunction만 순환 신경망 모델을 지원합니다. 신경망에는 (관측값 채널의 내용을 받는) 하나의 입력 계층과 (가능한 모든 행동에 대한 값으로 구성된 벡터를 반환하는) 하나의 출력 계층이 있어야 합니다.
신경망을 layer 객체로 구성된 배열로 정의합니다. 순환 신경망을 만들기 위해 sequenceInputLayer를 입력 계층으로 사용하고 하나 이상의 lstmLayer를 포함합니다.
net = [
sequenceInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(50)
reluLayer
lstmLayer(20,OutputMode="sequence");
fullyConnectedLayer(20)
reluLayer
fullyConnectedLayer(numel(actInfo.Elements))
];dlnetwork 객체로 변환하고 가중치 개수를 표시합니다.
net = dlnetwork(net); summary(net);
Initialized: true
Number of learnables: 6.3k
Inputs:
1 'sequenceinput' Sequence input with 4 dimensions
net와 환경 사양을 사용하여 크리틱 근사기 객체를 만듭니다.
critic = rlVectorQValueFunction(net,obsInfo,actInfo);
임의의 입력 관측값을 사용하여 크리틱을 확인합니다.
getValue(critic,{rand(obsInfo.Dimension)})ans = 2×1 single column vector
0.0136
0.0067
크리틱에 대한 몇 가지 훈련 옵션을 정의합니다.
criticOptions = rlOptimizerOptions( ... LearnRate=1e-3, ... GradientThreshold=1);
DQN 에이전트 생성을 위한 옵션을 지정합니다. 순환 신경망을 사용하려면 SequenceLength를 1보다 큰 값으로 지정해야 합니다.
agentOptions = rlDQNAgentOptions(... UseDoubleDQN=false, ... TargetSmoothFactor=5e-3, ... ExperienceBufferLength=1e6, ... SequenceLength=32, ... CriticOptimizerOptions=criticOptions); agentOptions.EpsilonGreedyExploration.EpsilonDecay = 1e-4;
에이전트를 만듭니다. 액터 신경망과 크리틱 신경망은 무작위로 초기화됩니다.
agent = rlDQNAgent(critic,agentOptions)
agent =
rlDQNAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDQNAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlFiniteSetSpec]
SampleTime: 1
임의 관측값에서 행동을 반환하기 위해 getAction을 사용하여 에이전트를 확인합니다.
getAction(agent,rand(obsInfo.Dimension))
ans = 1×1 cell array
{[-10]}
순차적인 관측값을 사용하여 에이전트를 실행하려면 시퀀스 길이(시간) 차원을 사용합니다. 예를 들어, 9개의 순차적 관측값에 대한 행동을 구합니다.
[action,state] = getAction(agent, ...
{rand([obsInfo.Dimension 1 9])});관측값의 일곱 번째 요소에 해당하는 행동을 표시합니다.
action = action{1};
action(1,1,1,7)ans = -10
이제 환경 내에서 에이전트를 테스트하고 훈련시킬 수 있습니다.
버전 내역
R2019a에 개발됨