ischange
데이터 내 급격한 변화 찾기
구문
설명
TF = ischange(___,Name=Value)ischange(A,MaxNumChanges=m)은 최대 m개의 변화 지점을 감지합니다.
예제
잡음이 있는 데이터로 구성된 벡터를 만들고 데이터 평균의 급격한 변화를 찾습니다.
A = [ones(1,5) 25*ones(1,5) 50*ones(1,5)] + rand(1,15); TF = ischange(A)
TF = 1×15 logical array
0 0 0 0 0 1 0 0 0 0 1 0 0 0 0
plot(A,"*") hold on xline(find(TF)) legend("Data","Change Points",Location="NW")

행렬의 각 행에 대한 평균의 급격한 변화 지점을 계산합니다.
A = diag(25*ones(5,1)) + rand(5,5)
A = 5×5
25.8147 0.0975 0.1576 0.1419 0.6557
0.9058 25.2785 0.9706 0.4218 0.0357
0.1270 0.5469 25.9572 0.9157 0.8491
0.9134 0.9575 0.4854 25.7922 0.9340
0.6324 0.9649 0.8003 0.9595 25.6787
TF = ischange(A,2)
TF = 5×5 logical array
0 1 0 0 0
0 1 1 0 0
0 0 1 1 0
0 0 0 1 1
0 0 0 0 1
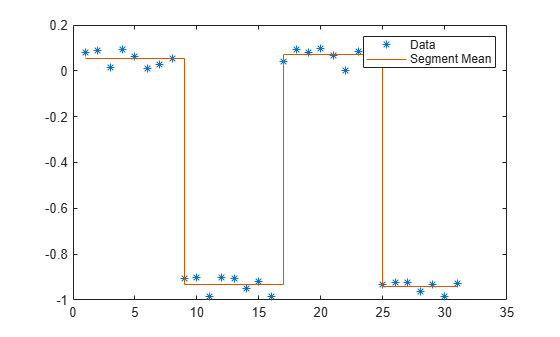
잡음이 있는 데이터로 구성된 벡터를 만듭니다. ischange 함수에 두 개의 출력 인수를 지정하면 데이터의 평균에서 급격한 변화를 찾고, 변화 지점 간의 평균을 계산할 수 있습니다.
A = floor(sin(0:.4:12)) + rand(1,31)/10; [TF,S1] = ischange(A); plot(A,"*") hold on stairs(S1) legend("Data","Segment Mean")
잡음이 있는 데이터로 구성된 벡터를 만듭니다. 그런 다음 데이터의 기울기와 절편에서의 급격한 변화를 계산합니다. 감지 임계값을 크게 지정하면 잡음으로 인해 검출되는 변화 지점 개수가 줄어듭니다.
A = [zeros(1,100) 1:100 99:-1:50 50*ones(1,250)] + 10*rand(1,500); [TF,S1,S2] = ischange(A,"linear",Threshold=200); segline = S1.*(1:500) + S2; plot(1:500,A,1:500,segline) legend("Data","Linear Regime")

입력 인수
입력 데이터로, 벡터, 행렬, 다차원 배열, 또는 숫자형 변수로 구성된 table형 또는 timetable형으로 지정됩니다.
데이터형: double | single | table | timetable
변화 감지 방법으로, 다음 값 중 하나로 지정됩니다.
"mean"— 데이터 평균에서 급격한 변화를 찾습니다."variance"— 데이터 분산에서 급격한 변화를 찾습니다."linear"— 데이터의 기울기와 절편에서의 급격한 변화를 찾습니다.
연산을 수행할 배열의 차원으로, 양의 정수 스칼라로 지정됩니다. 값이 지정되지 않은 경우 디폴트 값은 크기가 1이 아닌 첫 번째 배열 차원이 됩니다.
m×n 입력 행렬 A가 있다고 가정합니다.
ischange(A,1)은A의 각 열에 있는 데이터에 따라 변화 지점을 감지하고m×n행렬을 반환합니다.
ischange(A,2)는A의 각 행에 있는 데이터에 따라 변화 지점을 감지하고m×n행렬을 반환합니다.
table형 또는 timetable형 입력 데이터의 경우 dim은 지원되지 않으며 연산은 각 테이블 변수나 타임테이블 변수를 따라 개별적으로 수행됩니다.
이름-값 인수
출력 인수
알고리즘
데이터 A로 구성된 벡터는 다음과 같이 두 개의 세그먼트, A1과 A2로 분할될 수 있는 경우 변화 지점이 포함됩니다.
는 Threshold 파라미터로 지정되는 임계값이고, C는 비용 함수를 나타냅니다.
예를 들어, 평균에서 급격한 변화를 감지하는 비용 함수는 입니다. 여기서, N은 벡터 x에 있는 요소의 개수입니다. 비용 함수는 세그먼트가 얼마나 평균에 근접한지를 측정합니다.
ischange는 비용 함수의 합계를 반복적으로 최소화하여 다음과 같이 변화 지점 개수 k와 이러한 변화 지점의 위치를 판별합니다.
대체 기능

참고 문헌
[1] Killick R., P. Fearnhead, and I.A. Eckley. "Optimal detection of changepoints with a linear computational cost." Journal of the American Statistical Association. Vol. 107, Number 500, 2012, pp.1590-1598.