nearest
반지름 내 최근접이웃
설명
예제
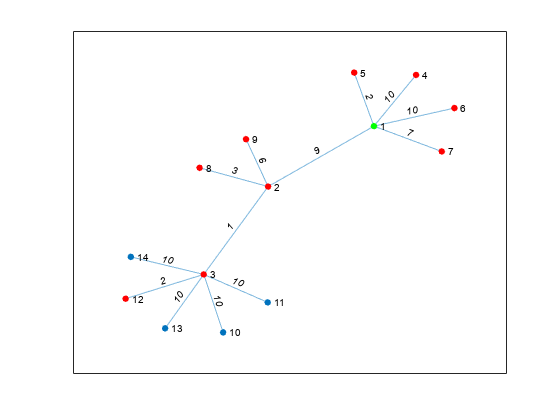
가중치 간선이 있는 그래프를 생성하고 플로팅합니다.
s = [1 1 1 1 1 2 2 2 3 3 3 3 3]; t = [2 4 5 6 7 3 8 9 10 11 12 13 14]; weights = randi([1 10],1,13); G = graph(s,t,weights); p = plot(G,'Layout','force','EdgeLabel',G.Edges.Weight);

노드 1부터 반지름 15 이내에 있는 노드를 확인합니다.
nn = nearest(G,1,15)
nn = 9×1
5
7
2
3
4
6
8
12
9
소스 노드는 녹색으로, 최근접이웃은 빨간색으로 강조 표시합니다.
highlight(p,1,'NodeColor','g') highlight(p,nn,'NodeColor','r')
가중치 간선이 있는 그래프를 생성하고 플로팅합니다.
s = [1 1 1 2 2 6 6 7 7 3 3 9 9 4 4 11 11 8];
t = [2 3 4 5 6 7 8 5 8 9 10 5 10 11 12 10 12 12];
weights = [10 10 10 10 10 1 1 1 1 1 1 1 1 1 1 1 1 1];
G = graph(s,t,weights);
plot(G,'EdgeLabel',G.Edges.Weight)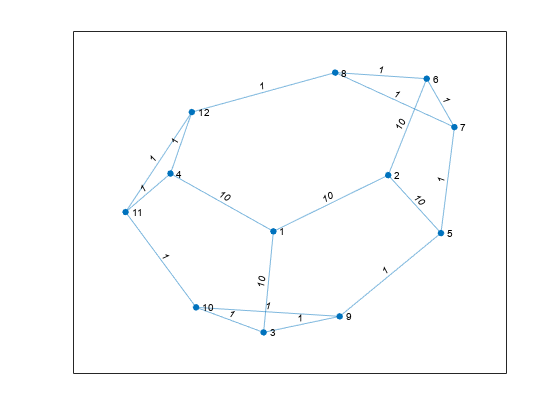
노드 3부터 반지름 5 이내에 있는 노드를 확인하고, 각 노드까지의 거리를 반환합니다.
[nn,dist] = nearest(G,3,5)
nn = 9×1
9
10
5
11
4
7
12
6
8
dist = 9×1
1
1
2
2
3
3
3
4
4
가중치 간선이 있는 유방향 그래프를 생성하고 플로팅합니다.
s = {'a' 'a' 'a' 'b' 'c' 'c' 'e' 'f' 'f'};
t = {'b' 'c' 'd' 'a' 'a' 'd' 'f' 'a' 'b'};
weights = [1 1 1 2 2 2 2 2 2];
G = digraph(s,t,weights);
plot(G,'EdgeLabel',G.Edges.Weight)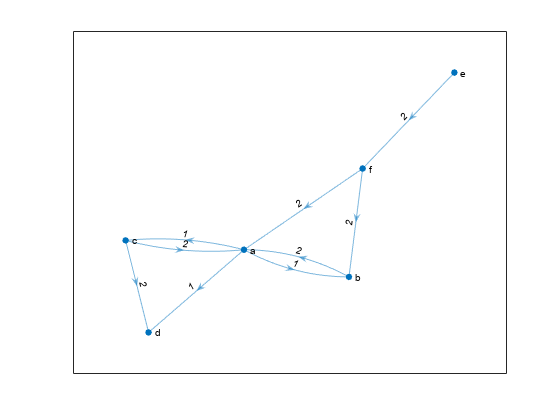
노드 'a'부터 반지름 1 이내에 있는 가장 가까운 노드를 확인합니다. 노드 'a'에서 나가는 경로 거리로 측정합니다.
nn_out = nearest(G,'a',1)nn_out = 3×1 cell
{'b'}
{'c'}
{'d'}
반지름을 Inf로 지정하여 노드 'a'로 들어오는 경로가 있는 모든 노드를 확인합니다.
nn_in = nearest(G,'a',Inf,'Direction','incoming')
nn_in = 4×1 cell
{'b'}
{'c'}
{'f'}
{'e'}
입력 인수
이름-값 인수
출력 인수
확장 기능
버전 내역
R2016a에 개발됨
참고 항목
shortestpath | distances | shortestpathtree | neighbors | successors | predecessors