테이블을 생성하고 테이블에 데이터 할당하기
테이블은 텍스트 파일 또는 스프레드시트의 테이블 형식 데이터와 같은 열 방향 데이터에 적합합니다. 테이블은 데이터 열을 변수로 저장합니다. 테이블에 포함된 변수는 데이터형이 서로 다를 수 있습니다. 그러나 모든 변수의 행 개수는 동일해야 합니다. 하지만 테이블 변수는 열 벡터로만 저장하는 것으로 한정되지 않습니다. 예를 들어, 테이블 변수는 여러 열로 구성된 행렬을 포함할 수 있습니다. 단, 다른 테이블 변수와 동일한 개수의 행을 가져야 합니다.
MATLAB®에서는 여러 가지 방법으로 테이블을 생성하고 여기에 데이터를 할당할 수 있습니다.
table함수를 사용하여 입력 배열에서 테이블을 만듭니다.점 표기법을 사용하여 기존 테이블에 변수를 추가합니다.
빈 테이블에 변수를 할당합니다.
테이블을 사전할당하고 나중에 데이터를 채웁니다.
array2table,cell2table또는struct2table함수를 사용하여 변수를 테이블로 변환합니다.readtable함수를 사용하여 파일에서 테이블을 읽어옵니다.가져오기 툴을 사용하여 테이블을 가져옵니다.
어떤 방법을 선택할지는 데이터의 특성 그리고 코드에서 테이블을 어떻게 사용할 것인지에 따라 결정합니다.
입력 배열에서 테이블 생성하기
table 함수를 사용하여 배열에서 테이블을 생성할 수 있습니다. 예를 들어, 환자 5명에 대한 데이터가 포함된 작은 테이블을 생성합니다.
먼저, 데이터로 구성된 열 방향 배열을 6개 만듭니다. 환자가 5명이기 때문에 이들 배열은 5개 행을 가집니다. (배열은 대부분 5×1 열 벡터이지만 BloodPressure는 5×2 행렬입니다.)
LastName = ["Sanchez";"Johnson";"Zhang";"Diaz";"Brown"]; Age = [38;43;38;40;49]; Smoker = [true;false;true;false;true]; Height = [71;69;64;67;64]; Weight = [176;163;131;133;119]; BloodPressure = [124 93; 109 77; 125 83; 117 75; 122 80];
이제 테이블 patients를 데이터에 대한 컨테이너로 만듭니다. table 함수에 대한 다음 호출에서 입력 인수는 작업 공간 변수 이름을 patients의 변수 이름으로 사용합니다.
patients = table(LastName,Age,Smoker,Height,Weight,BloodPressure)
patients=5×6 table
LastName Age Smoker Height Weight BloodPressure
_________ ___ ______ ______ ______ _____________
"Sanchez" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Zhang" 38 true 64 131 125 83
"Diaz" 40 false 67 133 117 75
"Brown" 49 true 64 119 122 80
이 테이블은 6개의 변수를 가지므로 5×6 테이블입니다. BloodPressure 변수에서 볼 수 있듯이 테이블 변수는 열을 여러 개 가질 수 있습니다. 이 예제에서는 테이블이 행과 열이 아니라 행과 변수를 갖는 이유를 보여줍니다.
점 표기법을 사용하여 테이블에 변수 추가하기
테이블을 만든 후에는 점 표기법을 사용하여 언제든지 새 변수를 추가할 수 있습니다. 점 표기법은 이름 T.varname으로 테이블 변수를 참조할 수 있습니다. 여기서 T는 테이블이고 varname은 변수 이름입니다. 이 표기법은 데이터에 액세스하고 데이터를 구조체의 필드에 할당하는 데 사용하는 표기법과 유사합니다.
예를 들어, BMI 변수를 patients에 추가해 보겠습니다. patients.Weight와 patients.Height의 값을 사용하여 BMI(체질량지수)를 계산합니다. BMI 값을 새 테이블 변수에 할당합니다.
patients.BMI = (patients.Weight*0.453592)./(patients.Height*0.0254).^2
patients=5×7 table
LastName Age Smoker Height Weight BloodPressure BMI
_________ ___ ______ ______ ______ _____________ ______
"Sanchez" 38 true 71 176 124 93 24.547
"Johnson" 43 false 69 163 109 77 24.071
"Zhang" 38 true 64 131 125 83 22.486
"Diaz" 40 false 67 133 117 75 20.831
"Brown" 49 true 64 119 122 80 20.426
변수를 빈 테이블에 할당하기
테이블을 만드는 또 다른 방법은 빈 테이블로 시작하고 여기에 변수를 할당하는 것입니다. 예를 들어, 환자 데이터로 구성된 테이블을 다시 만들되, 이번에는 점 표기법을 사용하여 변수를 할당해 보겠습니다.
먼저 table을 인수 없이 호출하여 빈 테이블 patients2를 만듭니다.
patients2 = table
patients2 = 0×0 empty table
다음으로 변수를 할당하여 환자 데이터의 복사본을 만듭니다. Name 및 BP 테이블 변수에서 보이는 것처럼 테이블 변수 이름이 배열 이름과 일치할 필요는 없습니다.
patients2.Name = LastName; patients2.Age = Age; patients2.Smoker = Smoker; patients2.Height = Height; patients2.Weight = Weight; patients2.BP = BloodPressure
patients2=5×6 table
Name Age Smoker Height Weight BP
_________ ___ ______ ______ ______ __________
"Sanchez" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Zhang" 38 true 64 131 125 83
"Diaz" 40 false 67 133 117 75
"Brown" 49 true 64 119 122 80
테이블을 사전할당하고 행 채우기
때로는 테이블에 저장하려는 데이터의 크기와 데이터형을 알지만 데이터를 할당하는 것은 나중에 할 계획일 수 있습니다. 한 번에 몇 개의 행만 추가하고자 할 수도 있습니다. 이 경우, 테이블에 공간을 사전할당한 다음 빈 행에 값을 할당하는 것이 더 효율적일 수 있습니다.
예를 들어, 서로 다른 관측소의 시간 및 온도 측정값을 포함하도록 테이블에 공간을 사전할당하려면 table 함수를 사용하십시오. 입력 배열을 제공하는 대신 테이블 변수의 크기와 데이터형을 지정합니다. 타임테이블 변수에 이름을 제공하려면 VariableNames 이름-값 인수를 지정하십시오. 사전할당은 데이터형에 적합한 디폴트 값으로 테이블 변수를 채웁니다.
sz = [4 3]; varTypes = ["double" "datetime" "string"]; varNames = ["Temperature" "Time" "Station"]; temps = table(Size=sz,VariableTypes=varTypes,VariableNames=varNames)
temps=4×3 table
Temperature Time Station
___________ ____ _________
0 NaT <missing>
0 NaT <missing>
0 NaT <missing>
0 NaT <missing>
테이블에 행을 할당하거나 추가하는 한 방법은 행에 셀형 배열을 할당하는 것입니다. 셀형 배열이 행 벡터이고 해당 요소가 각 변수의 데이터형과 일치하는 경우 할당 시 셀형 배열이 테이블 행으로 변환됩니다. 그러나 셀형 배열을 사용하면 한 번에 한 행만 할당할 수 있습니다. 값을 처음 2개 행에 할당합니다.
temps(1,:) = {75,datetime("now"),"S1"};
temps(2,:) = {68,datetime("now")+1,"S2"}temps=4×3 table
Temperature Time Station
___________ ____________________ _________
75 19-Apr-2026 06:47:43 "S1"
68 20-Apr-2026 06:47:43 "S2"
0 NaT <missing>
0 NaT <missing>
다른 방법으로, 더 작은 테이블의 행을 더 큰 테이블에 할당할 수 있습니다. 이 방법을 사용하면 한 번에 하나 이상의 행을 할당할 수 있습니다.
temps(3:4,:) = table([63;72],[datetime("now")+2;datetime("now")+3],["S3";"S4"])
temps=4×3 table
Temperature Time Station
___________ ____________________ _______
75 19-Apr-2026 06:47:43 "S1"
68 20-Apr-2026 06:47:43 "S2"
63 21-Apr-2026 06:47:43 "S3"
72 22-Apr-2026 06:47:43 "S4"
두 구문 중 하나를 사용하면서 테이블 끝을 넘어 행을 할당하여 테이블의 크기를 늘릴 수 있습니다. 필요한 경우 누락된 행이 디폴트 값으로 채워집니다.
temps(6,:) = {62,datetime("now")+6,"S6"}temps=6×3 table
Temperature Time Station
___________ ____________________ _________
75 19-Apr-2026 06:47:43 "S1"
68 20-Apr-2026 06:47:43 "S2"
63 21-Apr-2026 06:47:43 "S3"
72 22-Apr-2026 06:47:43 "S4"
0 NaT <missing>
62 25-Apr-2026 06:47:43 "S6"
변수를 테이블로 변환하기
다른 데이터형을 가지는 변수를 테이블로 변환할 수 있습니다. 셀형 배열과 구조체는 데이터형이 서로 다른 배열을 저장할 수 있는 다른 유형의 컨테이너입니다. 따라서 셀형 배열과 구조체를 테이블로 변환할 수 있습니다. 또한 배열을 테이블로 변환할 수도 있습니다. 이때 테이블 변수에는 배열의 값 열이 포함됩니다. 이러한 종류의 변수를 변환하려면 array2table, cell2table 또는 struct2table 함수를 사용하십시오.
예를 들어, array2table을 사용하여 배열을 테이블로 변환해 보겠습니다. 배열에는 열 이름이 없으므로 테이블은 디폴트 변수 이름을 가집니다.
A = randi(3,3)
A = 3×3
3 3 1
3 2 2
1 1 3
a2t = array2table(A)
a2t=3×3 table
A1 A2 A3
__ __ __
3 3 1
3 2 2
1 1 3
VariableNames 이름-값 인수를 사용하여 고유한 테이블 변수 이름을 제공할 수 있습니다.
a2t = array2table(A,VariableNames=["First" "Second" "Third"])
a2t=3×3 table
First Second Third
_____ ______ _____
3 3 1
3 2 2
1 1 3
파일에서 테이블 읽어오기
CSV(쉼표로 구분된 값) 파일 또는 Excel® 스프레드시트와 같은 파일에는 흔히 대량의 테이블 형식 데이터가 있습니다. 이러한 데이터를 테이블로 읽어오려면 readtable 함수를 사용하십시오.
예를 들어 CSV 파일 outages.csv는 MATLAB과 함께 배포되는 샘플 파일입니다. 이 파일에는 일련의 정전에 대한 데이터가 포함되어 있습니다. outages.csv의 첫 번째 라인에는 열 이름이 있습니다. 파일의 나머지 부분에는 각 정전에 대한 쉼표로 구분된 데이터 값이 포함되어 있습니다. 여기에는 처음 몇 개 행이 표시되어 있습니다.
Region,OutageTime,Loss,Customers,RestorationTime,Cause SouthWest,2002-02-01 12:18,458.9772218,1820159.482,2002-02-07 16:50,winter storm SouthEast,2003-01-23 00:49,530.1399497,212035.3001,,winter storm SouthEast,2003-02-07 21:15,289.4035493,142938.6282,2003-02-17 08:14,winter storm West,2004-04-06 05:44,434.8053524,340371.0338,2004-04-06 06:10,equipment fault MidWest,2002-03-16 06:18,186.4367788,212754.055,2002-03-18 23:23,severe storm ...
outages.csv를 읽고 데이터를 테이블에 저장하려면 readtable을 사용하면 됩니다. 이 함수는 숫자형 값, 날짜/시간 및 문자열을 적절한 데이터형을 가진 테이블 변수로 읽어옵니다. 여기서 Loss 및 Customers는 숫자형 배열입니다. OutageTime 변수와 RestorationTime 변수는 datetime형 배열입니다. readtable은 입력 파일의 해당 열에 있는 텍스트의 날짜/시간 형식을 인식하기 때문입니다. 텍스트 데이터의 나머지 부분을 string형 배열로 읽어오려면 TextType 이름-값 인수를 지정하십시오.
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
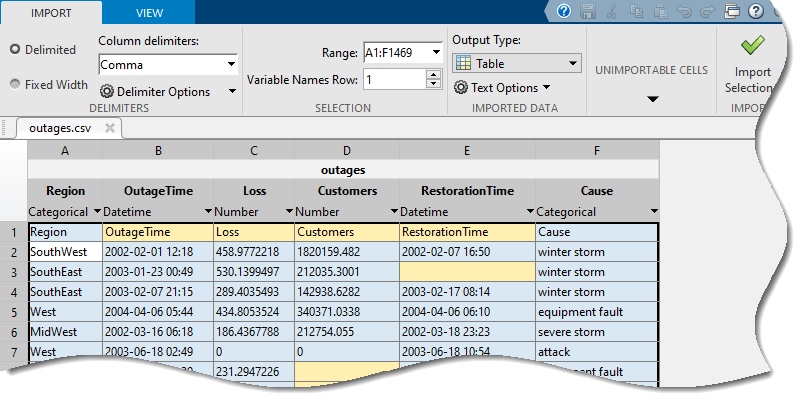
가져오기 툴을 사용하여 테이블 가져오기
마지막으로 가져오기 툴을 사용하여 스프레드시트 파일 또는 구분된 텍스트 파일에서 대화형 방식으로 데이터를 미리 보고 가져올 수 있습니다. 가져오기 툴을 여는 방법에는 다음과 같이 두 가지가 있습니다.
MATLAB 툴스트립: 홈 탭의 변수 섹션에서 데이터 가져오기를 클릭합니다.
MATLAB 명령 프롬프트:
uiimport(filename)을 입력합니다. 여기서filename은 텍스트 파일이나 스프레드시트 파일의 이름입니다.
예를 들어, uiimport 및 which를 사용하여 outages.csv 샘플 파일을 열고 파일에 대한 경로를 가져옵니다.
uiimport(which("outages.csv"))
가져오기 툴은 outages.csv의 6개 열에 대한 미리보기를 보여줍니다. 데이터를 테이블로 가져오려면 다음 단계를 따르십시오.
가져온 변수 섹션에서 테이블을 유형으로 선택합니다.
오른쪽 위 코너에 있는 선택 항목 가져오기를 클릭합니다. 작업 공간에
outages라는 이름의 새 테이블이 나타납니다.
참고 항목
함수
readtable|table|array2table|cell2table|struct2table