공정 모델 추정
라이브 편집기에서 SISO(단일 입력 단일 출력) 시스템에 대한 연속시간 공정 모델을 시간 영역 또는 주파수 영역에서 추정
설명
공정 모델 추정 작업을 통해 SISO 시스템에 대한 공정 모델을 대화형 방식으로 추정하고 검증할 수 있습니다. 모델 구조를 정의하고 바꾸고, 초기 조건 처리 및 탐색 방법 같은 선택적 파라미터를 지정할 수 있습니다. 이 작업은 라이브 스크립트에 대한 MATLAB® 코드를 자동으로 생성해 줍니다. 일반적인 라이브 편집기 작업에 대한 자세한 내용은 라이브 스크립트에 대화형 방식 작업 추가하기 항목을 참조하십시오.
공정 모델은 선형 시스템 동특성을 설명하는 간단한 연속시간 전달 함수입니다. 공정 모델 요소에는 정적 이득, 시정수, 시간 지연, 적분기, 프로세스 영점이 포함됩니다.
공정 모델은 다양한 산업에서 시스템 동특성을 설명할 때 자주 사용되며, 다양한 프로덕션 환경에 적용 가능합니다. 이 모델의 장점은 단순하고, 전송 지연 추정을 지원하며, 모델 계수가 극점과 영점처럼 쉽게 해석 가능하다는 점입니다. 공정 모델 추정에 대한 자세한 내용은 What Is a Process Model? 항목을 참조하십시오.
공정 모델 추정 작업은 보다 일반적인 System Identification 앱과는 별개입니다. 여러 모델 구조에 대한 추정값을 계산하고 비교하려면 System Identification 앱을 사용하십시오.
시작하려면, 입력 및 출력 데이터가 포함된 실험 데이터를 MATLAB 작업 공간에 불러온 다음 그 데이터를 작업에 가져오십시오. 그런 다음 추정할 모델 구조를 선택합니다. 이 작업에서 제공하는 컨트롤과 플롯을 통해 서로 다른 모델 구조로 실험하고 각 모델의 출력이 측정값과 얼마나 잘 맞는지 비교할 수 있습니다.
작업 열기
MATLAB 편집기에서 공정 모델 추정 작업을 라이브 스크립트에 추가하려면 다음을 수행하십시오.
라이브 편집기 탭에서 작업 > 공정 모델 추정을 선택합니다.
스크립트의 코드 블록에
process,estimate같은 관련 키워드를 입력합니다. 제안된 명령 완성 항목에서공정 모델 추정을 선택합니다.
예제
공정 모델 추정 라이브 편집기 작업을 사용하여 공정 모델을 추정하고 모델 출력을 측정 데이터와 비교합니다.
데이터 설정하기
측정 데이터 tt1을 MATLAB 작업 공간에 불러옵니다. tt1은 하나의 입력 변수 u와 하나의 출력 변수 y를 포함하는 타임테이블입니다.
load sdata1 tt1
데이터를 작업으로 가져오기
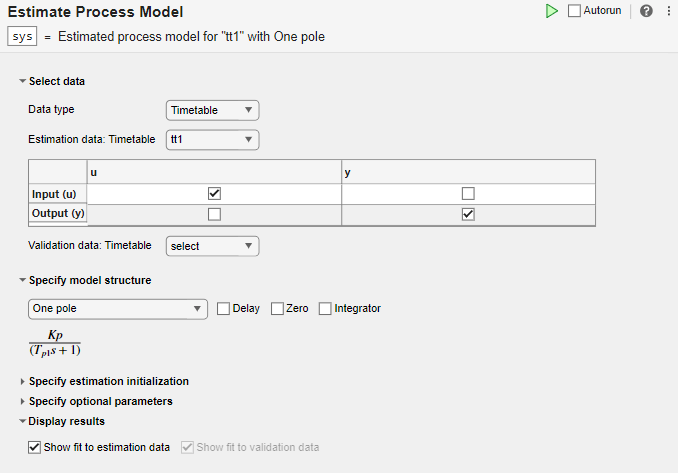
데이터 선택 섹션에서 데이터형을 Timetable로 설정하고 추정 데이터를 tt1로 설정합니다.
tt1 입력 및 출력 변수 이름이 포함된 테이블이 작업에 표시됩니다.
디폴트 설정을 사용하여 모델 추정하기
모델 구조와 선택적 파라미터를 검토합니다.
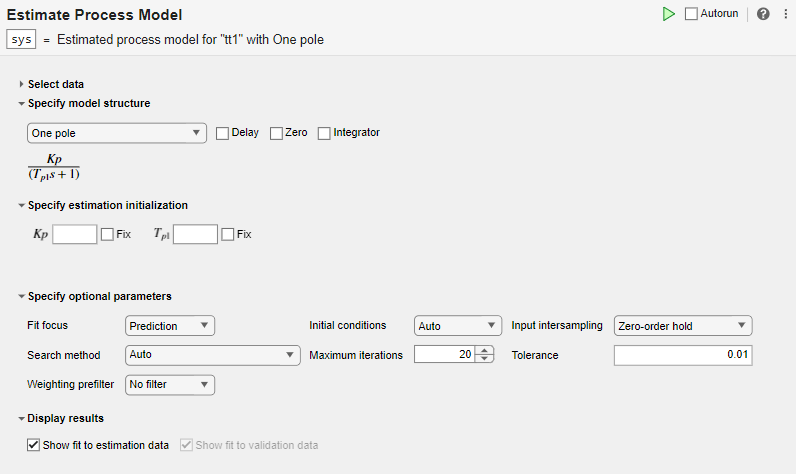
모델 구조 지정 섹션에서 디폴트 옵션은 지연, 영점 또는 적분기가 없는 One Pole입니다. 이 섹션의 파라미터 아래에 표시되는 수식을 통해 지정된 구조를 알 수 있습니다.
추정 초기화 지정 섹션에서 모델 구조의 파라미터와 일치하는 초기화 파라미터를 통해 추정 시작점을 설정할 수 있습니다. 고정을 선택하는 경우 파라미터는 사용자가 지정한 값으로 고정된 상태를 유지합니다. 이 예제에서는 초기화를 지정하지 마십시오. 그러면 시작점에 디폴트 값이 사용됩니다.
선택적 파라미터 지정 섹션에는 프로세스 추정에 대한 디폴트 옵션이 설정되어 있습니다.
녹색 화살표를 클릭하여 라이브 편집기 탭에서 작업을 실행합니다. 자동 실행을 선택하여 파라미터를 업데이트할 때마다 자동으로 작업을 실행할 수도 있습니다.
![]()
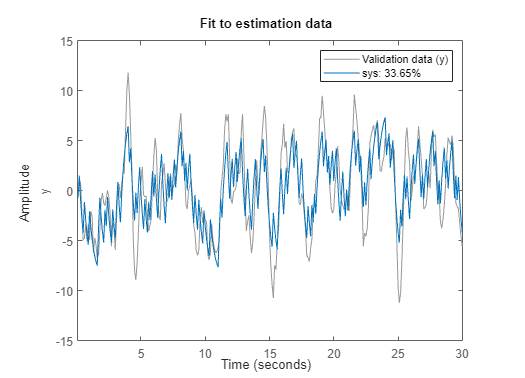
플롯에 추정 데이터, 추정된 모델 출력, 피팅 백분율이 표시됩니다.
파라미터 설정을 사용한 실험
파라미터 설정을 사용하여 실험하고 그러한 설정이 피팅에 미치는 영향을 확인합니다.
예를 들어 지연을 One Pole 구조에 추가하고 작업을 실행해 보겠습니다.
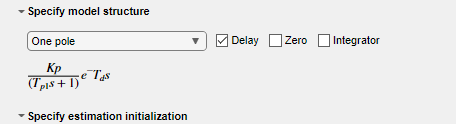
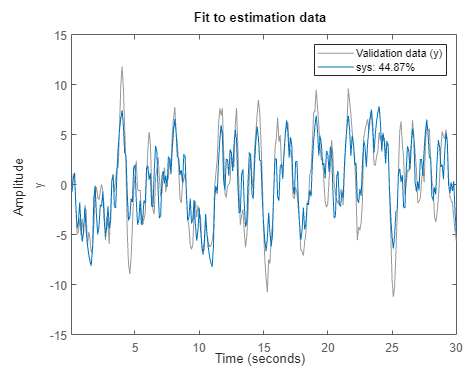
피팅 백분율은 여전히 50% 미만이지만 추정 피팅이 개선되었습니다.
다른 모델 구조를 사용해 보십시오. 모델 구조 지정에서 지연 없이 Underdamped Pair를 선택하고 작업을 실행합니다.
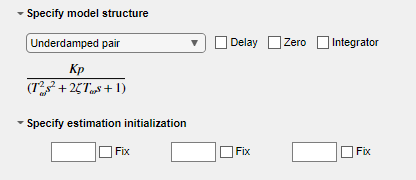
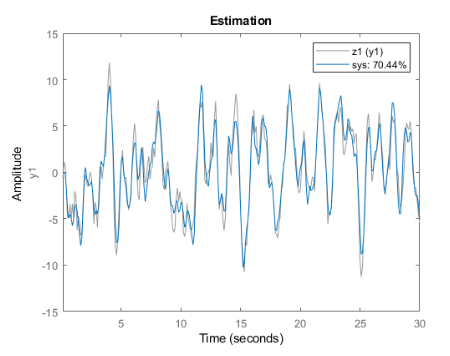
피팅 결과가 크게 향상되었습니다.
코드 생성하기
작업에서 생성된 코드를 표시하려면 파라미터 섹션의 맨 아래에 있는 ![]() 를 클릭하십시오. 코드에는 작업의 현재 파라미터 구성이 반영되어 있습니다.
를 클릭하십시오. 코드에는 작업의 현재 파라미터 구성이 반영되어 있습니다.
추정된 공정 모델을 검증할 수 있도록 별도의 추정 데이터와 검증 데이터를 사용합니다.
데이터 설정하기
측정 데이터 sdata1을 MATLAB 작업 공간에 불러오고 그 내용을 검토합니다.
load sdata1 umat1 ymat1 Ts
데이터를 두 개의 세트로 분할합니다. 하나는 추정을 위한 것이고 다른 하나는 검증을 위한 것입니다. 원래 데이터 세트에는 300개의 샘플이 있으므로, 새 데이터 세트에는 각각 150개의 샘플이 있습니다.
u_est = umat1(1:150); u_val = umat1(151:300); y_est = ymat1(1:150); y_val = ymat1(151:300); Ts
Ts = 0.1000
데이터를 작업으로 가져오기
데이터 선택 섹션에서 데이터형을 숫자로 설정합니다. 샘플 시간 0.1초로 설정합니다. 추정과 검증에 적절하게 데이터 세트를 선택합니다.
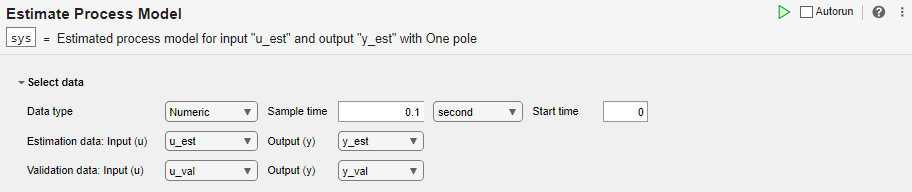
모델 추정 및 검증하기
예제 라이브 편집기 작업을 통해 공정 모델 추정하기에서는 모델 구조 Underdamped Pair를 사용할 때 결과가 가장 좋았습니다. 이 예제에도 동일한 옵션을 선택합니다.
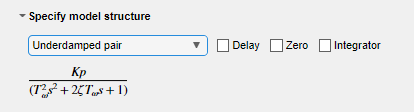
작업을 실행합니다. 작업을 실행하면 플롯 두 개가 생성됩니다. 첫 번째 플롯은 추정 결과를 보여주고, 두 번째 플롯은 검증 결과를 보여줍니다.
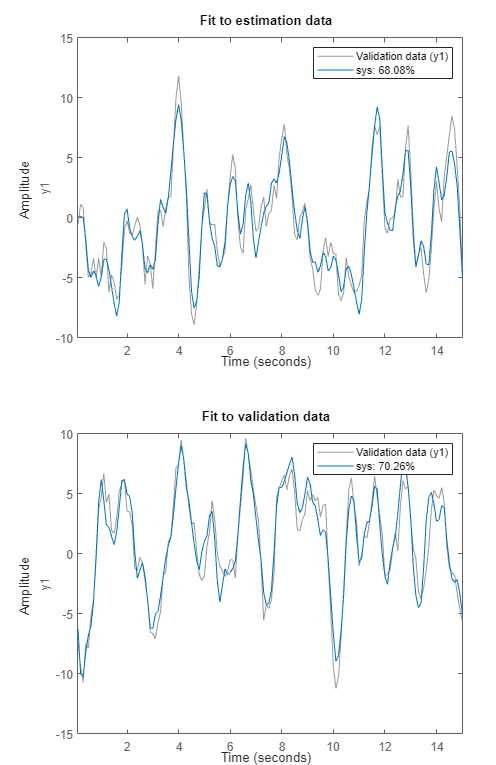
추정 데이터에 대한 피팅이 라이브 편집기 작업을 통해 공정 모델 추정하기에서보다 다소 떨어집니다. 현재 예제에서의 추정에는 모델 추정을 위한 데이터가 절반밖에 들어 있지 않습니다. 모델의 적합도를 보다 일반적으로 나타내는 검증 데이터에 대한 피팅이 추정 데이터에 대한 피팅보다 더 낫습니다.